Flink写500亿/天数据到远端Kafka排错、Flink优化记录。
序
since:2021年6月3日 19:32
suth: Hadi
注:由于为公司项目,所以大多数内容进行了屏蔽或删除处理,记录此只是希望大家继续学习,如果发现任何ip、人物、服务器等信息,请立即私信我进行更改,请勿走上违法犯罪道路!
前言
5月26号接到上级命令,协助优化Flink推送数据,现在问题有数据掉落,数据重复,数据积压,数据损坏等等,基本能遇到的数据推送的问题全都有了。所用核心数为105核(本文所有的资源与数据量都是以A预处理集群进行讨论的),单核单位MEM为4G,数据量大概为500亿/天,高峰在8点~20点(其中10点和14点最高峰)。所以按照常理来说资源应该是完全足够的。流程为从预处理节点进行数据消费后直接推送到核心节点进行对外数据共享。
环境介绍
资源情况
预处理集群Kafka为21台服务器,核心Kafka为10台。带宽140G(在6月2日进行了升级到400G),这个带宽会与其他数据量共用。预处理服务器单台64 CPU,251G MEM,65T 机械硬盘。核心CPU和MEM与预处理相同,100T 机械(部分SSD)。预处理Kafka监控没有,实时程序执行情况没有,核心Kafka监控没有。
架构情况
预处理处理数据在各个预处理集群,有N个较小的集群作为预处理集群,我们称之为预处理集群。后续只会提到两个预处理集群为A和B。
预处理完毕后在中央核心集群进行进一步加工等其他操作,称之为核心集群。
环境改造
总体监控设计
由于排查问题为预处理集群数据量大的都存在该问题,故先把没有的监控搭建上。包含预处理Kafka Manager、实时程序 pushgetway,核心Kafka Manager。
刚好一个月前搭建了一个Promethues用于NiFi预处理的积压监控,网络也是互通的,故在此上面进行监控配置升级。
首先搭建KafkaManager在核心,一共两个KafkaManager用于核心和预处理节点的Kafka集群监控。然后在Promethues中配置各类Metrics指标抓取,最后由Grafana进行展示,效果如下图
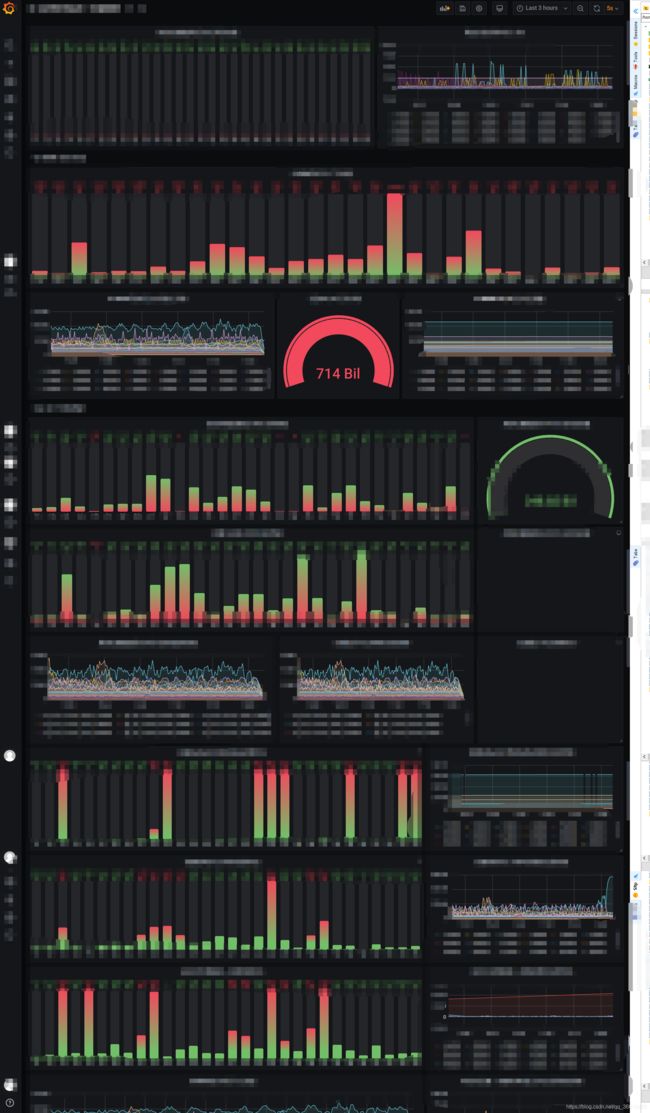
在进行监控搭建的过程中,也发现了各种奇葩的报错与问题。比如核心集群与预处理集群的Kafka配置全为默认值,B预处理kafka集群与某其他程序在同一服务器,其中这个程序固定吃200G内存,但CPU占用不到5%,严重影响资源配比。
现在回过头来看看监控,最严重的的省份就是 A和B两个集群。我们这里挑最严重的A和B进行排查。
预处理Kafka集群
刚刚也说过了,在预处理的Kafka与核心的Kafka配置皆为默认值,直接登录进行修改配置吧。
登录Ambari进行Kafka更改
KafkaManager 各省配置
直接上部分更改配置:

内存使用从4G提到12G。
PS:预处理Kafka集群此前并没有配置log打印信息,但预处理Kafka集群问题不明显,只是会影响消费数据入库和消费速度,故没有继续精细化配置。
可以参考的kafka端配置有:
| 配置名 |
内容 |
备注 |
| message.max.bytes |
消息体的最大大小,单位是字节 |
|
| num.network.threads |
broker 处理消息的最大线程数 |
|
| num.io.threads |
broker处理磁盘IO 的线程数 |
|
| background.threads |
后台任务处理的线程数 |
删除文件线程池 |
| queued.max.requests |
等待IO线程处理的请求队列最大数 |
熔断 |
| socket.send.buffer.bytes |
socket的发送缓冲区 |
|
| socket.receive.buffer.bytes |
socket的接受缓冲区 |
|
| socket.request.max.bytes |
socket请求的最大数值 |
|
| log.segment.bytes |
segment文件大小 |
|
| log.cleaner.min.cleanable.ratio |
日志清理的频率控制 |
|
核心Kafka集群
核心kafka集群在排忧的过程中,进行了一次扩容操作,从10扩容到23。更改与上述差不多的配置,由于是对外提供服务器的kafka集群,所以采用了配置滚动重启的方式进行配置重启。
其中有一台Kafka服务器,至今也无法连入其他Kafka服务器,所以只能进行下线操作,这个排错还在进行中。
Flink推送程序
在入手Flink程序的时候,就很朴实无华,消费写出,完事。
之前也提到了,问题就比较少,就是数据多了,数据少了,数据不完整了,数据有时延了,数据有重复了。
那么久先查看下实时程序吧:大概使用checkpoint进行offset提交预处理消费,producer推送到核心kafka。那为什么这么慢?以B预处理集群为例,每天500亿的结果数据推送到核心集群kafka,使用批量推送,每次1k条。
问题点:
使用checkpoint的时候,sink端需要进行幂等性操作,不然会在程序失败的时候导致重复写入。
批量推送没有问题,但是并没有进行压缩操作,导致数据大小太大,进行远距离消息传输所需带宽增大。
使用的kafka-connect 和kafkaSink版本过低。
解决三个问题:
手动提交或使用事务操作,由于是海量数据,故选择手动提交offset操作,避免数据重复提交。
在producer端添加lz4压缩,为方便consumer端方便操作,直接将topic也进行了compressType的更改。
将kafka-connect和KafkaSink版本升级,使用最新版本的jar包进行数据推送。
在升级jar包的时候发生了一个报错:
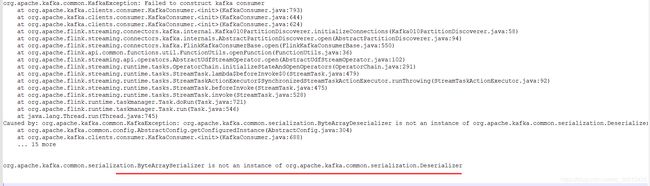
这个可能是将序列化和序列化解析弄反了,但是在Flink代码中并没有这个错误发生。最后发现是pom文件引入该包时使用了complie,而Flink提交时指定的库也有相同包,进行了更改报错消失。所以也算是莫名其妙。
上述问题看着简单,其实确实简单,但在巨量数据面前,问题就频频爆发。
但就算进行了上述更改,在数据量超过300MB/s的时候,还是发现有如下报错:
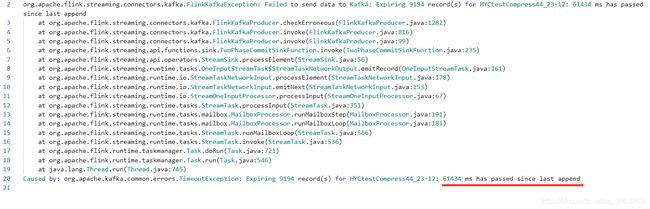
这个错误网上也有很多描述:
大多数都是说将request.timeout.ms 提高,batch-size 和liner-ms 调到比较合适的值。 但是其实这个原因的本质错误在org.apache.kafka.clients.producer.internals.ProducerBatch#maybeExpire中,(注意老版本不会区分以下三个报错)
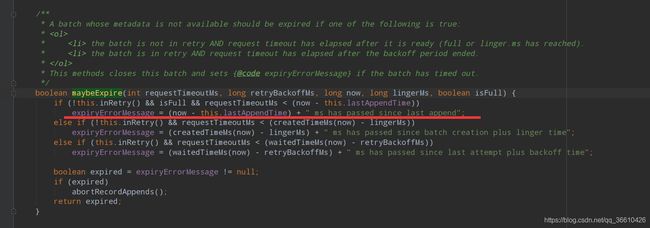
可以看到这个报错时第一种类型。原理描述可以如下:
一个partition只会有队头的batch被发送,sender线程不会对发送中partition的其余batch检查过期,指向同一个broker的多个partition的batch能够合并成一个request发送。其中前两点是由Accumulator里的muted变量来保证。注意是只有muted的partition才不会对其余batch检查过期,在把batch组装成request即将发送时才会把partition添加进muted。
如果在发送过程中网络抖动发送失败,那么就会把retry的batch添加到deque的头部等待下一次request组装。但如果由于网络抖动时长requestTimeoutMs不能组装成request,该retry的batch也会被sender线程检查过期,并立即返回callback。
所以这个超时就是我已经添加了数据到缓冲中,在缓冲中进行数据的发送,如果缓冲装满了,并且最后装入的时间大于了requestTimeoutMs,那么就会报错。
解决办法除了刚刚上述两个参数的调整,最重要的是不要用统一producer异步发送给多个partition,就能避免异步发送被任何后序barch超时异常扰乱的可能。所以改造方案最佳方案是 一个producer尽量只对一个partition进行数据的同时发送。
一个是异步发送能做到,一个是同步发送时的多线程发送各个partition能做到,所以单线程挨个partition的同步发送是不用担心的。正常来说对一个topic进行异步发送或多线程同步发送是没什么问题的。
同时经过kafka社区大神的认同,上面提到的request发送失败进行retry,很大的原因就是同一个request发送了多个partition的batch。虽然指向同一broker的多个partition的batch可以合并以提高并发效率,但每个batch达到broker之后要被各自不同的follower复制,全部都完成之后才会一起返回一个response。很明显总耗时很容易拉长导致producer超时retry。
摘自: https://www.jianshu.com/p/e0fcc4c30b38
问题是有这个解决办法,但其实后续我们发现就算更改后一样会有类似的报错出现,导致TaskManager重启。所以开启JVM的排查。
JVM排查
先在Flink页面查看TaskManager 的运行时长,比如
就是重启过的服务器*(后期进行的截图)。
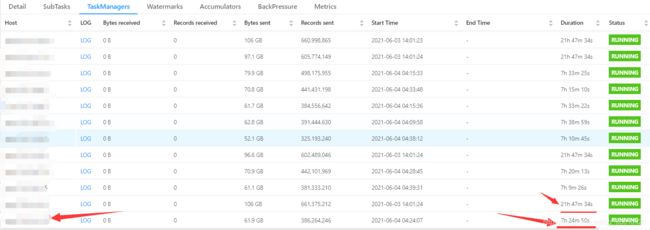
我们Flink没有开启webShell,就直接进服务器进行查看吧。
ps -ef |grep applicationId
筛选出taskManager的运行PID。
使用 jmap -J-d64 -heap 58071,演示效果如下:
以上图片为操作演示,以下图片为真实截图:
先查看heap堆的情况:jmap -J-d64 -heap 6956
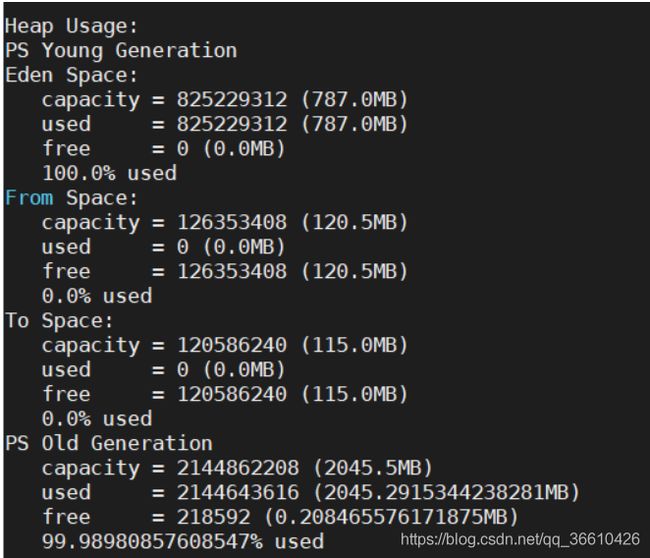
这里采用的是Java 1.8 默认GC ParallelGC收集器。新生代比例还是比较健康8:1:1。如果对GC不熟悉的童鞋,我建议重学JVM部分,推荐清单=>

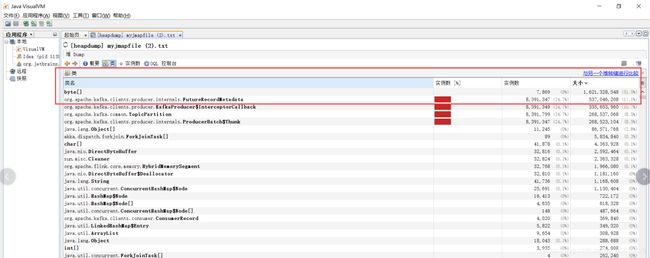
老年代99.98%,那么就看看内存占用情况吧:jmap -histo:live 6956 |head -n 20
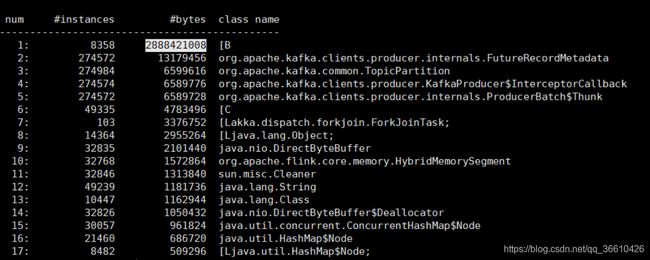
可以看到占空间最大的是byte[],简单介绍下:
[C is a char[] [S is a short[] [I is a int[] [B is a byte[] [I is a int[]]
其实估摸着能猜出来是什么,因为 2、3、4、5名都是producer端关于数据发送的如下图:

大概就是数据堆积无法发送,导致GC失败,(但在TaskManager中的日志并没看到GC相关报错,很奇怪),触发了OOM的:
java.lang.OutofMemoryError: GC overhead limit exceeded
查看下GC耗时:jstat -gcutil 6956 1s
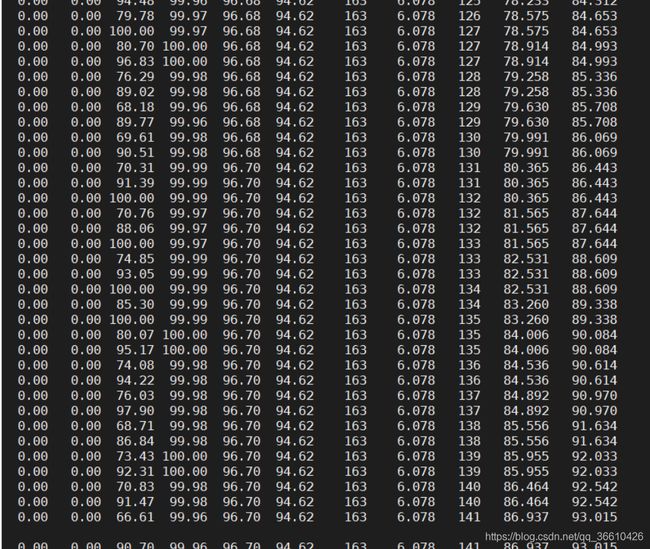
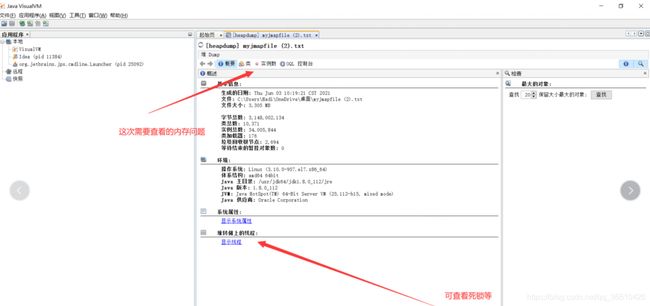
那么就dump JVM内存,看看到底装了啥btye[],装了这么多吧。4G的hprof文件从服务器上下载下来:
jmap -dump:format=b,file=myHeap.hprof 6956
使用jvisualvm打开,查看
这里down出 byte数组:
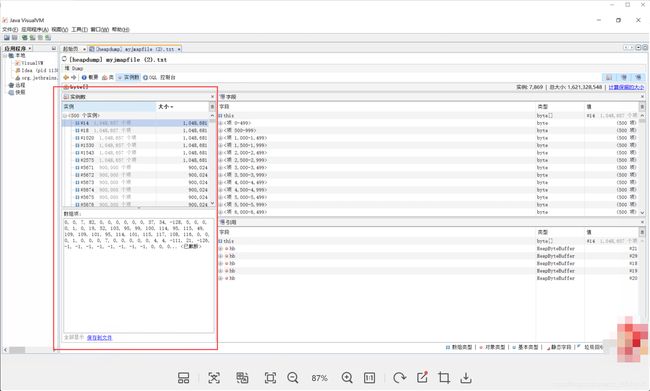
down出的文件如下:

将byte进行文件塑化后得出:
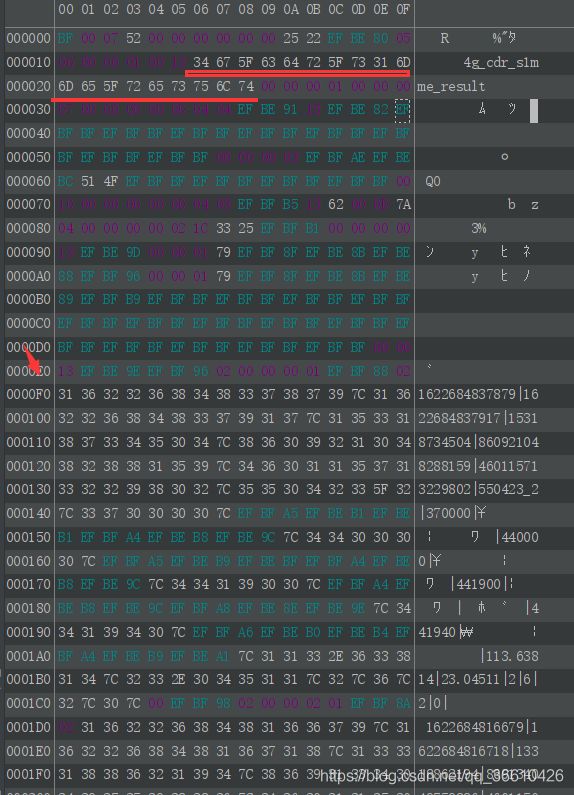
可以明确地看出来,这个就是从 source端取出的一条条数据。那么为什么这么多呢?因为缓冲区。
在上图中 RecordAccumulator中存储的ProducerBatch会存储这么多数据等待发射。具体上面也讲过了,怪不得这些数据无法被GC掉,因为是强引用,只有request成功后才会被清除掉。
所以将实时程序中对缓冲区相关的内存调小,整个GC问题就解决掉了。
优化后效果
消费速度:
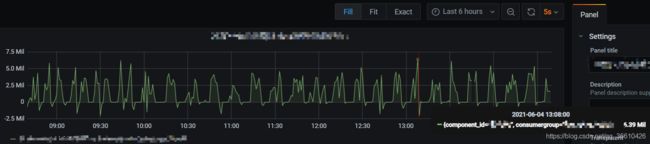
核心写入速度:
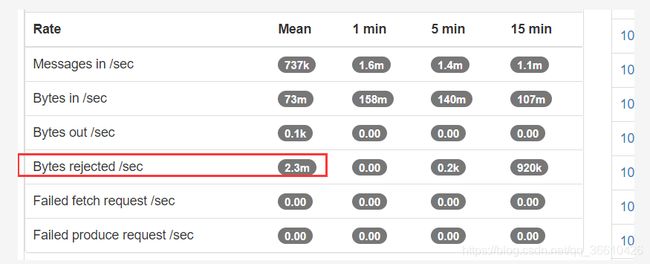
实测最高峰可达500mb/s (lz4压缩后),5million/s 条。
后续
后续,测试三天查看稳定性后进行所有预处理集群部署,意味着这次更新对下游会产生影响(之前都是无感更新操作)。
后记
整个排查的过程,这里写的挺粗糙的,原理都很简单,基本上就是别犯错。
但是很明显在开发过程中留下的都是不停催促的痕迹:
- 搭建的kafka,基础调参都没有。
- 整体监控,没有。对于我们这种超多集群环境的掌控,没有确实的监控,或者可以说有监控没人来看,或者说看了也都懒得处理。在这次排查过程中尽显无疑。对某些人来说拖一拖就拖一拖;“我不会呀”也能打发我很久。某些操作人员根本不考虑后果和影响,直接蛮干,点完就完事的心态,比如A预处理集群Kafka迁移。虽然我们服务器总量大,但其实还是很吃紧,扩容能缓解但并不是最终最好的方案。
- 不懂真正参数意义,只能尝试。这个可以理解为技术力欠缺,需要积累,不知道参与这次问题排查的人员记录了多少,又学习了多少。
- 望各位看到此贴的朋友不要当恶人。
再次声明
本blog只在CSDN发布,每个地方发布的版本不相同,有Hadi式加密手段(包含图片或段落文字),请勿进行传播扩散,仅供学习使用。
由于为公司项目,所以大多数内容进行了屏蔽或删除处理,记录此只是希望大家继续学习,如果发现任何ip、人物、服务器等信息,请立即私信我进行更改,请勿走上违法犯罪道路!