Spark和Alluxio
摘要: Spark在大数据处理领域正获得快速增长,其核心的RDD极大地提升了处理性能并且支持迭代运算。目前Spark DataFrame和Spark SQL更加成熟,而作为普通文件存储方案的Tachyon升级成为Alluxio,在成熟度和性能上都得到了进一步的提升,方便非结构化的文件处理,如影像、视频文件等,这里介绍其特性和使用方法。
原文[英]:http://www.alluxio.com/2016/04/getting-started-with-alluxio-and-spark/
简介
Alluxio是一个基于内存的分布式文件系统,它是架构在底层分布式文件系统和上层分布式计算框架之间的一个中间件,主要职责是以文件形式在内存或其它存储设施中提供数据的存取服务。
在大数据计算领域,Spark正成为耀眼的新星。当Spark与其大量的生态系统结合使用时,更加能够发挥出超长的能力。Alluxio, 原名Tachyon, 为Spark提供了可靠的数据共享层, 使Spark之行应用逻辑而Alluxio用于处理存储。例如, 全球金融集团 Barclays made the impossible possible,通过Alluxio和Spark融入其体系架构。 Baidu 分析petabytes级别的数据得到 30x performance improvements ,通过使用基于 Alluxio 和 Spark 的新架构。 通过Alluxio 1.0 release and 和即将到来的 Spark 2.0 release, 我们建立了一个简单而清晰的方式,把两者整合起来。
本文针对Alluxio 和 Spark的新的使用者,在单机上如何配置、使用大数据能力提供帮助。后续,我们将进一步将Spark和Alluxio扩展到分布式集群上。
本文内容
- 如何在本地机器上设置 Alluxio 和 Spark。
- 使用 Alluxio 和 Spark 的优势。
- Data sharing between multiple jobs: Only one job needs to incur the slow read from cold data
- Resilience against job failures: Data is preserved in Alluxio across job failures or restarts
- Managed storage: Alluxio optimizes the utilization of allocated storage across applications
- 权衡是否使用基于内存的 Spark application storage 还是 Alluxio storage。
- 如何连接 Alluxio 到外部存储, 如 S3。
开始
为了进行本教程, 我创建一个工作目录并且赋给环境变量。这使在不同的项目目录中引用代码变得更为容易。
- mkdir alluxio-spark-getting-started
- cd alluxio-spark-getting-started
- export DEMO_HOME=$(pwd)
为了启动 Alluxio 和 Spark, 首先需要下载这两个软件的分发版。本文中, 我们使用 Alluxio 1.0.1 和 Spark 1.6.1, 使用Alluxio 1.0+ 和 Spark 1.0+的步骤是一样的。
设置 Alluxio
下载, 提取, 和启动一个预编译的 Alluxio,网址: Alluxio website:
- cd $DEMO_HOME
- wget http://alluxio.org/downloads/files/1.0.1/alluxio-1.0.1-bin.tar.gz
- tar xvfz alluxio-1.0.1-bin.tar.gz
- cd alluxio-1.0.1
- bin/alluxio bootstrap-conf localhost
- bin/alluxio format
- bin/alluxio-start.sh local
验证一下 Alluxio 是否运行正常,访问: localhost:19999/home.
设置 Spark
下载预编译的Spark版本。Spark需要Alluxio客户端 jar软件包,连接 Spark 到 Alluxio; 现在是时候整合两个系统。
下载完后, 创建一个新的Spark environment配置,拷贝conf/spark-env.sh.template 到 conf/spark-env.sh。然后,你可以让Alluxio client jar可用,通过将其加到文件conf/spark-env.sh的SPARK_CLASSPATH 项中; 确认你的环境的path配置是正确的。
- cd $DEMO_HOME
- wget http://apache.mirrors.pair.com/spark/spark-1.6.1/spark-1.6.1-bin-hadoop2.4.tgz
- tar xvfz spark-1.6.1-bin-hadoop2.4.tgz
- wget http://alluxio.org/downloads/files/1.0.1/alluxio-core-client-spark-1.0.1-jar-with-dependencies.jar
- cd spark-1.6.1-bin-hadoop2.4
- cp conf/spark-env.sh.template conf/spark-env.sh
- echo 'export SPARK_CLASSPATH=/path/to/alluxio-core-client-spark-1.0.1-jar-with-dependencies.jar:$SPARK_CLASSPATH' >> conf/spark-env.sh
运行一个简单的例子
作为第一个例子, 我们运行Alluxio with Spark 从本地存储读取数据,来熟悉一下这两个系统整合后的使用方法。
注意,这种方式从Alluxio得到的性能提升是有限的; 本地存储的快速存取和OS buffer cache极大地帮助了磁盘数据的读取。 对于小的文件,有可能得到更低的效率,因为在执行期的通讯会增加开销。
示范数据
可以下载到一个从英文字典中随机创建的单词文件。
- cd $DEMO_HOME
- # compressed version
- wget https://s3.amazonaws.com/alluxio-sample/datasets/sample-1g.gz
- gunzip sample-1g.gz
- # uncompressed version
- wget https://s3.amazonaws.com/alluxio-sample/datasets/sample-1g
使用Spark
开启 spark-shell,如下面从Spark目录中启动。 可以在交互的shell中操作不通来源的数据,就像本地文件系统一样。
- cd $DEMO_HOME/spark-1.6.1-bin-hadoop2.4
- bin/spark-shell
在Spark中处理文件,统计文件中有多少行, 确认下载的示范数据文件在指定的目录中。
- val file = sc.textFile("/path/to/sample-1g")
- file.count()
使用Alluxio
Alluxio 也可以作为数据源。 你可以保存文件到Alluxio 或者在Alluxio上的数据运行其他的数据操作, 就像使用本地文件存储系统一样。
- val file = sc.textFile("/path/to/sample-1g")
- file.saveAsTextFile("alluxio://localhost:19998/sample-1g")
- val alluxioFile = sc.textFile("alluxio://localhost:19998/sample-1g")
- alluxioFile.count()
你可以看到两个操作的结果的性能很接近,但在大文件时Alluxio的表现会更好。
与Alluxio存储数据在内存然后存取处理一样,Spark 也使用Spark的 application memory,通过cache() API实现。但是,与Alluxio对比,优劣势是不一样的。
如果你使用一个 1 GB 文件, 你将看到一个提示:缓存RDD在内存的空间不够。这是因为spark-shell缺省启动时使用 1 GB 内存,并且仅仅分配那么大的空间用于存储。
- val file = sc.textFile("/path/to/sample-1g")
- file.cache()
- file.count()
- file.count()
你可以增加驱动的内存,然后重试:
- cd $DEMO_HOME/spark-1.6.1-bin-hadoop2.4
- bin/spark-shell --driver-memory 4g
你可以看见第二个count的执行更快一些。但是,Spark缓存的好处是有限的,因为数据存储在 JVM 内存中。在特殊情况下, 数据集更大的情况下, 还有可能引起下降。除此之外,cache 操作不能存储 raw data, 因此你将需要比文件要大的内存。
你可以下载一个 2 GB 的示范数据文件:
- cd $DEMO_HOME
- # compressed version
- wget https://s3.amazonaws.com/alluxio-sample/datasets/sample-2g.gz
- gunzip sample-2g.gz
- # uncompressed version
- wget https://s3.amazonaws.com/alluxio-sample/datasets/sample-2g
Spark中缓存数据
作为一个简单的例子, 我们在 spark-shell 分配4 GB内存,然后处理这个 2 GB 文件. 由于存储在JVM堆上的Java对象比实际数据要大, Spark 将不能存储全部数据集在内存中。这将显著降低job的执行性能,甚至比从磁盘上读取还要花费更长的时间。
- val file = sc.textFile("/path/to/sample-2g")
- file.cache()
- file.count()
- file.count()
一个变通的方案是将对象以序列化方式存储,将比 Java objects占用更少的存储空间。 第二个count 明显更快一些, 数据必须存储在Spark process中,并且退出后将不再可用。此外, 这很难完全得到Spark’s 存储和执行的分片优势,除非根据处理工作情况手动调节配置参数。
- import org.apache.spark.storage.StorageLevel
- val file = sc.textFile("/path/to/sample-2g")
- file.persist(StorageLevel.MEMORY_ONLY_SER)
- file.count()
- file.count()
Alluxio缓存数据
Alluxio可以解决使用Spark的执行存储遇到的上述问题。 在Alluxio上运行同样的例程, 我们首先需要增加Alluxio管理的内存总量。修改 Alluxio’的行 conf/alluxio-env.sh 从 1GB 到 3GB。 这基本上与spark-shell 中的 4 GB 内存相当 (Alluxio 3 GB + spark-shell 1 GB). 然后重新启动 Alluxio 让配置参数生效。
- cd $DEMO_HOME/alluxio-1.0.1
- vi conf/alluxio-env.sh
- # Modify the memory size line to 3GB in the file, then save and exit
- export ALLUXIO_WORKER_MEMORY_SIZE=${ALLUXIO_WORKER_MEMORY_SIZE:-3GB}
- bin/alluxio-start.sh local
然后, 我们加载同样的文件到 Alluxio 系统。可以通过 Alluxio shell来容易地完成, 或者通过spark-shell 来进行。
- cd $DEMO_HOME/alluxio-1.0.1
- bin/alluxio fs copyFromLocal ../sample-2g /sample-2g
- cd $DEMO_HOME/spark-1.6.1-bin-hadoop2.4
- bin/spark-shell
尝试运行之前同样的例子, 但使用这个更大的文件。
- val alluxioFile2g = sc.textFile("alluxio://localhost:19998/sample-2g")
- alluxioFile2g.count()
- val alluxioFile1g = sc.textFile("alluxio://localhost:19998/sample-1g")
- alluxioFile1g.count()
结果对比
这里是运行的结果,使用 1 GB spark-shell 和 3 GB Alluxio,与只使用Spark时 4 GB spark-shell (lower is better)的情况对比。


远程数据访问
现在,我们已经突破了将 Alluxio 和 Spark整合在一起的障碍, 我们将进一步尝试更接近生产环境下的例子。这个例子中,我们将使用Amazon的 S3 存储服务作为数据源, 这也很容易替换为其他的存储系统。
很多时候, 数据并不在本地计算机上而是保存在共享存储上。这种情况下, Alluxio 可以透明地连接到远程存储的优势立刻体现出来。这意味使用另一个客户端或者改变文件路径的时候,可以接着使用 Alluxio path,就像保存在一个命名空间下一样。
除此以外, 很多人可能查询同一个数据集, 例如一个数据团队的成员。 使用 Alluxio 摊销了从S3获取数据的昂贵成本,可以将其保存在Alluxio的存储空间中,并且减少了内存消耗。采用这种方法,只要一个人访问了数据,后续的调用都会在Alluxio的内存中进行。
访问S3中的数据集
我们来看一下如何访问S3中的数据集。
首先, 更新Alluxio使用想要的数据仓储。 一个公共的,只读的 S3 bucket中的样本数据集位于 s3n://alluxio-sample/datasets。
然后, 指定S3 credentials参数 到 Alluxio,通过在 alluxio-env.sh 中设置环境变量来实现。
访问S3 bucket这个数据不需要权限, 但需要 AWS 用户账号才能访问 S3. 保存您的keys 环境变量 AWS_ACCESS_KEY 和 AWS_SECRET_KEY, 然后更新 alluxio-env.sh.
- cd $DEMO_HOME/alluxio-1.0.1
- export AWS_ACCESS_KEY=YOUR_ACCESS_KEY
- export AWS_SECRET_KEY=YOUR_SECRET_KEY
- vi conf/alluxio-env.sh
- # Modify the ALLUXIO_JAVA_OPTS to add the two parameters
- export ALLUXIO_JAVA_OPTS+="
- -Dlog4j.configuration=file:${CONF_DIR}/log4j.properties
- ...
- -Dfs.s3n.awsAccessKeyId=$AWS_ACCESS_KEY
- -Dfs.s3n.awsSecretAccessKey=$AWS_SECRET_KEY
- "
现在重启 Alluxio 系统让Alluxio Server获得需要的授权信息。然后,你可以直接通过 Alluxio 连接到 S3 bucket,通过使用 mount 操作来实现。这将使任何对 Alluxio 路径 /s3 的访问直接连接到S3 bucket。
- cd $DEMO_HOME/alluxio-1.0.1
- bin/alluxio-start local
- bin/alluxio fs mount /s3 s3n://alluxio-sample/datasets
你将需要添加 S3 credentials 到Spark 环境。如下,在 conf/spark-env.sh中添加下面的行:
- cd $DEMO_HOME/spark-1.6.1-bin-hadoop2.4
- vi conf/spark-env.sh
- export SPARK_DAEMON_JAVA_OPTS+="
- -Dfs.s3n.awsAccessKeyId=$AWS_ACCESS_KEY
- -Dfs.s3n.awsSecretAccessKey=$AWS_SECRET_KEY
- "
如果只是简单地使用Spark,你可以如下方式在spark-shell中使用数据。你可能注意到,速度比本地磁盘慢了不少,因为这是通过网路远程访问的。 为了避免在后续调用中出现这个问题, 您可以缓存这个数据,但Spark memory需要至少与数据集一样大 (在使用serialized cache时需要更大), 并且数据需要缓存在每一个Spark context中,不能在不同的应用和用户间共享。注意,运行下面的例子将需要几分钟,取决于网络带宽的大小。您可以使用 100 MB 示例文件,在 s3n://alluxio-sample/datasets/sample-100m。
- val file = sc.textFile("s3n://alluxio-sample/datasets/sample-1g")
- file.count()
- val cachedFile = sc.textFile("s3n://alluxio-sample/datasets/sample-1g")
- cachedFile.cache()
- cachedFile.count()
使用 Alluxio, 你可以存取在S3 下的数据。你也许注意到,执行效率一样, 因为在两种情况下都是第一次读取远程S3上的数据。但是, 对于后续的读取来说, 在Alluxio效率更好,因为数据存储在本地内存上了。 你可以想象,对于那些非同寻常的计算负荷如数据处理流水线或者递归的机器学习, 数据存取的次数会远远多于一次。
S3中的数据预取
为了减少第一次读取的成本,您可以预取远程的数据,通过Alluxio shell的load命令来完成,如下所示。
- cd $DEMO_HOME/alluxio-1.0.1
- bin/alluxio fs load /s3/sample-1g
如果不预取数据, 直接从 S3 装入数据到 Alluxio 将设置 partition size 为1,以确保文件被载入到Alluxio。但是,当读数据时, 可以按照适合的方式分区文件。
- val file = sc.textFile("alluxio://localhost:19998/s3/sample-1g", 1)
- file.count()
- val file = sc.textFile("alluxio://localhost:19998/s3/sample-1g", 8)
- file.count()
数据访问性能对比
这里的执行性能是通过 10 MB/s 网络连接到 S3测试的结果。Alluxio 和 Spark 设置为分配内存 3 GB 给Alluxio 和 1 GB 给 spark-shell, 与Spark 独立分配 4 GB 的结果 (下图中,数值越低越好)。

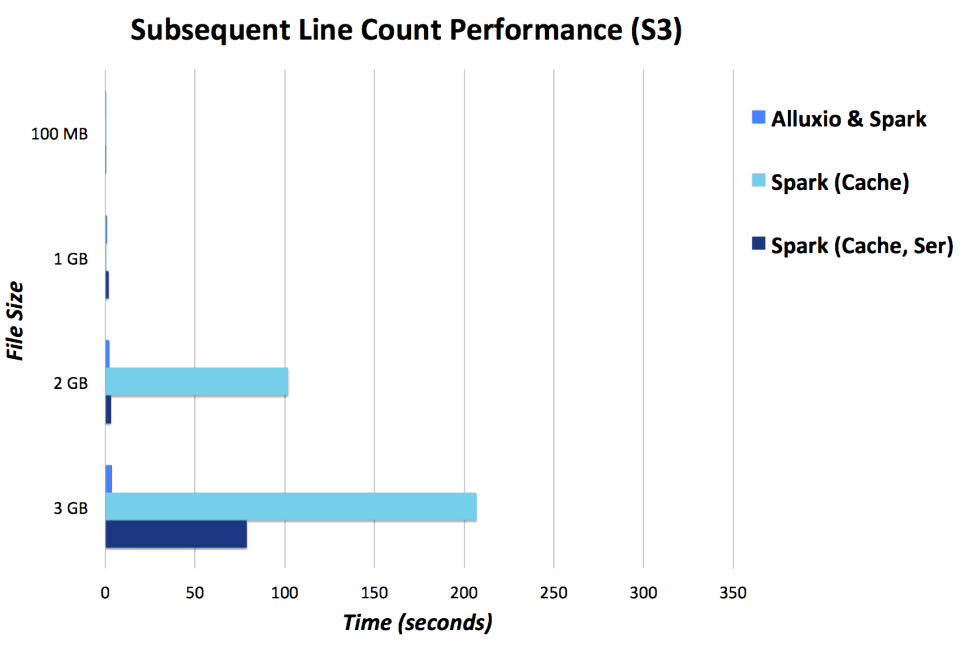
结论
这里介绍了 Alluxio 在 Spark上的运行和使用。后续将进行一些更深入的案例和 Alluxio 类似于 Spark的计算框架。 你希望下次看到那些内容,和哪些对你有帮助,可以电邮告诉我们: [email protected]。
一、Alluxio由来起因
Alluxio(之前名为Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。 应用只需要连接Alluxio即可访问存储在底层任意存储系统中的数据。此外,Alluxio的以内存为中心的架构使得数据的访问速度能比现有常规方案快几个数量级。
在大数据生态系统中,Alluxio介于计算框架(如Apache Spark,Apache MapReduce,Apache Flink)和现有的存储系统(如Amazon S3,GlusterFS,HDFS等等)之间。
Alluxio与Hadoop是兼容的。这意味着已有的Spark和MapReduce程序可以不修改代码直接在Alluxio上运行的。
Alluxio可以是独立的集群(推荐)。同时,Alluxio与yarn,mesos目前也是兼容的。这也意味着Alluxio可以作为一个普通的App运行在yarn或者mesos上面,这种方式是方便管理的,但是就实用性方面还是不足,定制集群的选择空间太窄,不容易使用。
二、Alluxio在spark中应用主要场景
Spark 的运行以 JVM 为基础,所以 Spark 的 Job 需要将数据存入 JVM 堆中。随着计算的迭代,JVM 堆中存放的数据会迅速增大。第一、对于 Spark 而言,计算引擎(堆)跟存储引擎(堆外。注意:和off-heap不是一个概念)都处在 JVM 中,所以会有重复的 GC 开销。这就响应了实时系统的低延时特性。其二,当 JVM 崩溃时,缓存在 JVM 堆中的数据也会丢失。这里 Spark 就不得不根据数据的 Lineage,重新计算丢失的数据。其三,当 Spark 需要跟 Hadoop 的 MapReduce 共享数据时,就必须通过第三方来共享,比如 HDFS。因为要借助第三方,就必须面对额外的开销,例如 HDFS 的 Disk IO。
随着基于内存计算框架的发展,以及以上的问题,促进了内存分布式文件系统的出现,也就是 Alluxio。对于 Spark 而言,计算数据存放于 Alluxio(内存中) 之中,首先会减少 Spark 的 GC 开销。再而当 Spark 的 JVM 进程奔溃时,存放在 Alluxio的数据不会受影响。如果 Spark 需要跟别的计算框架进行数据共享时,只要通过 Alluxio的 Client 就可以做到了,并且延迟远低于 HDFS 等文件系统。
三、Alluxio的设计原理
1. Alluxio的基本架构:
Alluxio是主从架构的Master(master-slaves),一个主节点(AlluxioMaster),多个从节点Worker(AlluxioWorker)。

当 Alluxio的 Worker 节点启动之后,Worker 会向 Master 注册。注册成功之后,Master 会和 Worker 之间维护一个心跳。Alluxio会将内存映射为 Block 设备,也就是 RamDisk。然后,Alluxio会将数据存放于每个 Worker 的 Ramdisk,也就是内存中。Alluxio可以以内存的速度去读写 Ramdisk 中存放的数据。Master 是存放媒体信息的,例如文件的大小,以及文件在哪个 Worker。这里的设计其实类似于 HDFS 得 NameNode 和 DataNode。Worker 会在心跳中将数据信息传递给 Master,Master 会更新数据的媒体信息。对于一个集群来说,内存总是有限的,因此 Alluxio还需要支持硬盘的文件系统,这里称之为 UnderFS。Alluxio会将一些持久性的文件存在 UnderFS 中。这里的 UnderFS 可以是 OS 的文件系统,也可以是 HDFS、GlusterFS、S3 之类的分布式文件系统。
2. Alluxio的HA高级架构:(常用推荐)
Alluxio的容错通过多master实现。同一时刻,有多个master进程运行。其中一个被选举为leader,作为所有worker和 client的通信首选。其余master进入备用状态,和leader共享日志,以确保和leader维护着同样的文件系统元数据并在 leader失效时迅速接管leader的工作。当前leader失效时,自动从可用的备用master中选举一个作为新的leader,Alluxio继续正常运行。但在切换到备用 master时,客户端会有短暂的延迟或瞬态错误。

从架构图看以看出要实现一个容错的Alluxio集群需要两方面的准备:
- ZooKeeper
- 用于存放日志的可靠的共享底层文件系统。
Alluxio使用Zookeeper实现容错和leader选举,可以保证在任何时间最多只有一个leader。
Alluxio使用共享底层文件系统存放日志。共享文件系统必须可以被所有master访问,可以选择 HDFS(笔者使用)Amazon S3或 GlusterFS作为共享文件系统。leader master将日志写到共享文件 系统,其它(备用) master持续地重播日志条目与leader的最新状态保持一致。
3.Alluxio在yarn环境的部署
Alluxio在yarn上部署的架构图:
简述:具体的架构解释可以根据yarn本身使用的架构原理相比较。

注意的地方:如果要使用在yarn环境下面的部署,不能用之前部署使用的二进制tar包,必须先停止之前独立模式的Alluxio集群,指定Hadoop(yarn)的版本重新编译Alluxio,编译时指定”yarn”配置文件(以便Alluxio包含YARN client 和ApplicationMaster)。具体方法,见官网。(笔者不推荐使用这种方法,实际也没有测试过)
四、Alluxio在大数据生态系统的地位
由于Alluxio的设计以内存为中心,并且是数据访问的中心,所以Alluxio在大数据生态圈里占有独特地位,它居于传统大数据存储(如:Amazon S3,HDFS)和大数据计算框架(如Spark,Hadoop Mapreduce)之间。对于用户应用和计算框架,无论其是否运行在相同的计算引擎之上,Alluxio都可以作为底层来支持数据的访问、快速存储,以及多任务的数据共享和本地化。
因此,Alluxio可以为那些大数据应用提供一个数量级的加速,同时它还提供了通用的数据访问接口。对于底层存储系统,Alluxio连接了大数据应用和传统存储系统之间的间隔,并且重新定义了一组面向数据使用的工作负载程序。因Alluxio对应用屏蔽了底层存储系统的整合细节,所以任何底层存储系统都可以支撑运行在Alluxio之上的应用和框架。此外Alluxio可以挂载多种底层存储系统,所以它可以作为统一层为任意数量的不同数据源提供服务。
五、Alluxio集群部署
独立模式:
1、Alluxio local模式。
因为官方网站上面用的是local模式,加上网上有很多local的模式,部署也相当的简单,这里就不多介绍了。官方网址:http://www.alluxio.org/docs/master/cn/Running-Alluxio-Locally.html
2、Alluxio cluster模式(HA)。
这里默认使用者已经部署了Hadoop,spark的集群环境。并且对Linux各种操作命令也有一定的了解。
所以直接部署Alluxio的集群环境。在搭建Alluxio的环境的时候,最重要部署三个组件的配置:master,worker,client。
第一步:下载二进制包和JDK8版本(以后只支持JDK8),(如果有特殊的需要可以重新下载源码包maven打包编译)
wget http://downloads.alluxio.org/downloads/files/1.3.0/alluxio-1.3.0-cdh5-bin.tar.gz
访问官网下载地址:http://www.alluxio.org/download,选择你想下载的对应版本。如果使用的Hadoop环境是CDH的,那么下载相应的CDH版本就好。这样兼容性更好。(笔者一直使用的CDH5版本)

第二步:安装好JDK8,解压Alluxio并配置环境变量。
export JAVA_HOME=/opt/core/jdk1.8.0_102
export ALLUXIO_HOME=/opt/core/alluxio
export PATH=.:$JAVA_HOME/bin:$ALLUXIO_HOME/bin:$PATH
第三步:配置alluxio配置文件。
1)在目录$ALLUXIO_HOME/conf的目录下面找到配置文件alluxio-env.sh
编辑以及更改一下配置项:
ALLUXIO_RAM_FOLDER=/opt/data/ramdisk
解释:内存映射到磁盘下目录(读取文件的时候读的是内存,内存!!不是磁盘。) ALLUXIO_UNDERFS_ADDRESS=hdfs://serviceName/alluxio
解释:Alluxio底层存储的文件系统,可以是s3以及其他的文件系统,这里用HDFS。(官方配置的是namenode的地址和服务端口,这里直接用的serviceName,目的是支持多个Namenode HA的情况)
ALLUXIO_WORKER_MEMORY_SIZE=90GB
解释:这个是每台机器上面的worker节点所占用的内存大小,根据需求自动调整。
ALLUXIO_JAVA_OPTS="-Dalluxio.zookeeper.enabled=true -Dalluxio.zookeeper.address=zk1:2181,zk2:2181,zk3:2181 -Dalluxio.master.journal.folder=hdfs://serviceName/alluxio/journal"
解释:启用Alluxio高可用的配置项,启动用户必须有权限在HDFS上面写数据。这个配置项是全局的,也就是在master,worker,client上面都起作用 。
ALLUXIO_USER_JAVA_OPTS="-Dalluxio.zookeeper.enabled=true -Dalluxio.zookeeper.address=zk1:2181,zk2:2181,zk3:2181"
解释:配置客户端的配置项,全局已经配置,这里可以省略。
2)更加高级的配置项可以在$ALLUXIO_HOME/conf/alluxio-site.properties定制化配置。
如:启用多个存储策略(目前支持mem,SSD,disk),也可以定制存储的算法。
同时也可以配置用户的权限。
其他的配置项目可以参考官方网址:
第四步:把hadoop下面的core-site.xml,hdfs-site.xml拷贝到$ALLUXIO_HOME/conf/的目录下面。若没有拷贝可能造成解析不了hdfs的serviceName,最后把worker的配置文件配置你想要配置的worker节点。
第五步:启动master,worker节点。
alluxio-start.sh master
alluxio-start.sh worker
完成现在可以正常使用了。
第六步:集成spark,在$SPARK_HOME/conf/spark-defaults.conf配置中加上配置项,同步worker节点重启spark集群。
spark.driver.extraClassPath $ALLUXIO_HOME/core/client/target/alluxio-core-client-1.3.0-jar-with-dependencies.jar基本可以使用的,如果在使用的过程中有权限的问题还请读者根据自己的环境配置下面的几个配置项。
alluxio.security.login.username=
alluxio.security.authorization.permission.umask=
alluxio.security.authorization.permission.supergroup=