Halcon学习笔记(九)——OCR实战练习 倾斜日期检测、倒着的字符检测
第四-八讲 OCR实战练习
在基于之前的例程分析之上,这里做具体应用,比如,食品包装袋上倾斜的日期识别,温度计上倒着的字符识别等。
倾斜日期识别
首先,对于这样一幅图片,怎样实现对日期的提取?

法一:矫正—分割—识别
第一步:矫正
在上一篇博客(OCR识别字符排列圆形或字体倾斜的处理办法)中我们分析了如何矫正倾斜的字符,这里直接上代码。这里推荐了两种方法实现,最终实现的识别效果都是一样的。
第一种方法,直接将其看做倾斜字符,利用单位矩阵和倾斜角度,保持y轴固定不动进行仿射得到的图像如下,这种方法得到的图形y轴是竖直的,但x轴不是水平的,如果想要x轴水平,将hom_mat2d_slant的参数``x改为’y’`即可。
* 加载图片,注意更改文件名
read_image (Image, 'ImageName')
text_line_slant (Image, Image, 60, rad(-45), rad(45), SlantAngle)
hom_mat2d_identity (HomMat2DIdentity)
hom_mat2d_slant (HomMat2DIdentity, -SlantAngle, 'x', 0, 0, HomMat2DSlant)
affine_trans_image (Image, ImageAffineTrans, HomMat2DSlant, 'constant', 'false')

第二种方法,利用区域定位gen_rectangle1和强制转换vector_angle_to_rigid在几何定位+仿射+车牌识别中有说明,和第一种方法不同的是,这里采用的是旋转变换,固定位置不变的点是(Height/2, Width/2),这样得到的仿射变换后的图形x, y都是水平或竖直的。代码如下。
get_image_size (Image, Width, Height)
gen_rectangle1 (ROI_0, 258.724, 388.308, 645.626, 1209.03)
text_line_orientation (ROI_0, Image, 75, -0.4, 0.4, OrientationAngle)
vector_angle_to_rigid (Height/2, Width/2, OrientationAngle, Height/2, Width/2, 0, HomMat2D)
affine_trans_image (Image, ImageAffineTrans1, HomMat2D, 'constant', 'false')

第二步:分割
同样分析两种方法,第一种方法是常规操作,由于背景简单,我们直接借助直方图工具做阈值化,然后通过选择区域、腐蚀、膨胀、打散、求交集等一系列操作,由于这一部分在之前的笔记中都多次提到,且对于每个图片的操作都要“因图制宜”,基本思路一样,即把感兴趣的区域想方设法拎出来,并且单个字符属于一个连通域,参数或者步骤不尽相同,这里给出参考程序。
threshold (ImageAffineTrans, Regions, 0, 215)
connection (Regions, ConnectedRegions)
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 0, 35498.5)
erosion_circle (SelectedRegions, RegionErosion, 3.5)
dilation_circle (RegionErosion, RegionDilation, 9)
union1 (RegionDilation, RegionUnion)
connection (RegionUnion, ConnectedRegions1)
intersection (ConnectedRegions1, ConnectedRegions, RegionIntersection)
select_shape (RegionIntersection, SelectedRegions1, 'area', 'and', 333.08, 5000)
partition_dynamic (SelectedRegions1, Partitioned, 50, 20)
sort_region (Partitioned, SortedRegions, 'character', 'true', 'row')

第二种方法是考虑到数字是点状的,因此我们调用dots_image算子直接实现对点状图形的提取。
dots_image (ImageAffineTrans, DotImage, 15, 'dark', 0)
得到

然后对得到的DotImage进行快速阈值化,(因为灰度分布区别显著),然后膨胀,使得单个字符之间全部连接,再打散,注意是先连接后打散,然后做形状转换,主要是为了更好的利用面积选择区域,除去噪声点,最后分割单个字符并求交集。
binary_threshold (DotImage, Region, 'max_separability', 'light', UsedThreshold)
dilation_rectangle1 (Region, RegionDilation2, 10, 10)
connection (RegionDilation2, ConnectedRegions2)
shape_trans (ConnectedRegions2, RegionTrans, 'rectangle1')
select_shape (RegionTrans, SelectedRegions2, 'area', 'and', 2260.48, 15673.7)
partition_dynamic (SelectedRegions2, Partitioned1, 50, 20)
intersection (Partitioned1, Region, RegionIntersection1)
得到和第一种方法相同的结果

第三步:识别
即读取OCR分类器,做识别测试,这里需要注意的是,图片中的字体是点状的打印字体,所以应该加载DotPrint_0-9A-Z_NoRej.omc字体。
read_ocr_class_mlp ('DotPrint_0-9A-Z_NoRej.omc', OCRHandle)
do_ocr_multi_class_mlp (SortedRegions, ImageAffineTrans, OCRHandle, Class, Confidence)
识别结果可以在控制变量窗口看到:
![]()
法二:借助OCR助手
借助OCR助手实现字符识别,我们在几何定位+仿射+车牌识别中实现了对车牌号的识别,下面进一步分析OCR助手的应用。
打开助手,选择打开新的OCR,配置设置页面,使用一个矩形框在图像中标记出需要识别文本的位置绘制文本位置(右击鼠标确定),选择字符特点,并输入希望读取的文本,选择图像窗口,最后应用快速设置,得到识别结果

那么实现的原理是什么呢?
转到分割页面
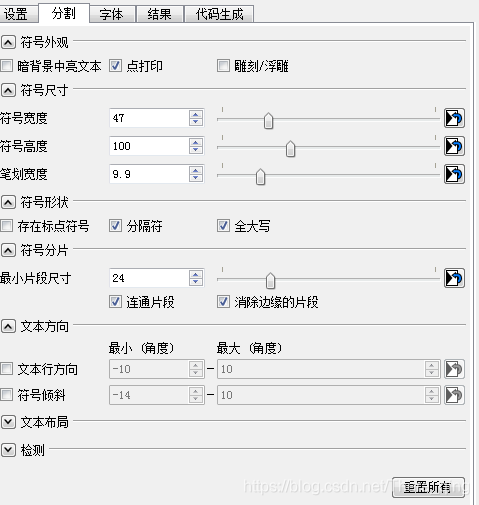
我们可以看到实际上就是根据识别符号的这些特征在预训练分类器(自动识别,可在字体页面查看)中进行测试得到的结果。
下面我们来查看利用OCR助手生成的代码是什么样子的
第一步:创建文本模板并设置模板参数
我们在OCR识别初步 利用文本模板识别与生成训练文件的第一个示例中分析了,这里大同小异,实际上就是设置刚刚我们在分割页面看到的那些参数。
create_text_model_reader ('manual', [], TextModel)
set_text_model_param (TextModel, 'manual_is_dotprint', 'true')
set_text_model_param (TextModel, 'manual_char_width', 47)
set_text_model_param (TextModel, 'manual_char_height', 100)
set_text_model_param (TextModel, 'manual_stroke_width', 9.9)
set_text_model_param (TextModel, 'manual_return_punctuation', 'false')
set_text_model_param (TextModel, 'manual_uppercase_only', 'true')
set_text_model_param (TextModel, 'manual_fragment_size_min', 24)
set_text_model_param (TextModel, 'manual_eliminate_border_blobs', 'true')
set_text_model_param (TextModel, 'manual_base_line_tolerance', 0.2)
set_text_model_param (TextModel, 'manual_max_line_num', 2)
第二步:加载分类器
read_ocr_class_mlp ('DotPrint_NoRej.omc', OcrHandle)
第三步:切割文本部分
通过我们刚刚绘制的矩形和图像做差得到我们文本所在的区域
copy_obj (Image, Image, 1, 1)
gen_rectangle2 (ROI_OCR_01_0, 417.862, 717.78, rad(6.76665), 349.965, 157.831)
access_channel (Image, TmpObj_Mono, 1)
reduce_domain (TmpObj_Mono, ROI_OCR_01_0, TmpObj_MonoReduced_OCR_01_0)

第四步:旋转矫正
定义偏移的角度,利用单位矩阵做旋转仿射变换。
TmpCtrl_Orientation := 0.1181
hom_mat2d_identity (TmpCtrl_MatrixIdentity)
hom_mat2d_rotate (TmpCtrl_MatrixIdentity, -TmpCtrl_Orientation, 0, 0, TmpCtrl_MatrixRotation)
affine_trans_image (TmpObj_MonoReduced_OCR_01_0, ImageOCR, TmpCtrl_MatrixRotation, 'constant', 'false')
第五步:读取文本信息并识别
find_text (ImageOCR, TextModel, TextResultID)
get_text_object (Characters, TextResultID, 'all_lines')
dev_display (ImageOCR)
dev_set_draw ('fill')
dev_set_colored (3)
dev_display (Characters)
do_ocr_multi_class_mlp (Characters, ImageOCR, OcrHandle, Class1, Confidence1)
最后得到识别结果为


但是事实上,OCR助手给出的第四步和第五步完整程序如下:
TmpCtrl_Orientation := 0.1181
* OCR 01: Build rotation matrix
hom_mat2d_identity (TmpCtrl_MatrixIdentity)
hom_mat2d_rotate (TmpCtrl_MatrixIdentity, -TmpCtrl_Orientation, 0, 0, TmpCtrl_MatrixRotation)
* OCR 01: Apply transformation to image and domain
get_domain (TmpObj_MonoReduced_OCR_01_0, TmpObj_Domain)
get_system ('clip_region', TmpCtrl_ClipRegion)
set_system ('clip_region', 'false')
dilation_circle (TmpObj_Domain, TmpObj_DomainExpanded, 49)
affine_trans_region (TmpObj_DomainExpanded, TmpObj_DomainTransformedRaw, TmpCtrl_MatrixRotation, 'true')
smallest_rectangle1 (TmpObj_DomainTransformedRaw, TmpCtrl_Row1, TmpCtrl_Col1, TmpCtrl_Row2, TmpCtrl_Col2)
hom_mat2d_translate (TmpCtrl_MatrixIdentity, -TmpCtrl_Row1, -TmpCtrl_Col1, TmpCtrl_MatrixTranslation)
hom_mat2d_compose (TmpCtrl_MatrixTranslation, TmpCtrl_MatrixRotation, TmpCtrl_MatrixComposite)
affine_trans_region (TmpObj_Domain, TmpObj_DomainTransformed, TmpCtrl_MatrixComposite, 'true')
affine_trans_image (TmpObj_MonoReduced_OCR_01_0, TmpObj_ImageTransformed, TmpCtrl_MatrixComposite, 'constant', 'true')
dilation_circle (TmpObj_Domain, TmpObj_DomainExpanded, 49)
expand_domain_gray (TmpObj_ImageTransformed, TmpObj_ImageTransformedExpanded, 49)
reduce_domain (TmpObj_ImageTransformed, TmpObj_DomainTransformed, TmpObj_ImageTransformedReduced)
crop_part (TmpObj_ImageTransformedReduced, TmpObj_MonoReduced_OCR_01_0, 0, 0, TmpCtrl_Col2-TmpCtrl_Col1+1, TmpCtrl_Row2-TmpCtrl_Row1+1)
set_system ('clip_region', TmpCtrl_ClipRegion)
find_text (TmpObj_MonoReduced_OCR_01_0, TextModel, TmpCtrl_ResultHandle_OCR_01_0)
* OCR 01:
* OCR 01: Read text (classification step)
get_text_object (Symbols_OCR_01_0, TmpCtrl_ResultHandle_OCR_01_0, 'manual_all_lines')
dev_display (TmpObj_MonoReduced_OCR_01_0)
dev_set_draw ('fill')
dev_set_colored (3)
dev_display (Symbols_OCR_01_0)
do_ocr_multi_class_mlp (Symbols_OCR_01_0, TmpObj_MonoReduced_OCR_01_0, OcrHandle, SymbolNames_OCR_01_0, Confidences_OCR_01_0)
* OCR 01:
* OCR 01: Do something with the results
这里它主要区别在第四步,通过不断地变换,把其他区域剪裁掉只剩下文本区域,太费周折,最后显示为

有点兜圈子的感觉,博主觉得脑袋不够转,所以没有仔细研究它的每步变换。
最后补充一点,我们还可以借助OCR助手进行训练并形成omc文件,具体方法是在刚刚OCR助手的字体
页面,将预训练分类器改为训练文件,然后写入需要训练的数据,点击加入训练数据,下面按步骤梳理一遍。
1、配置设置页面并应用
2、配置字体页面,选择训练文件,在空白框处添加训练数据
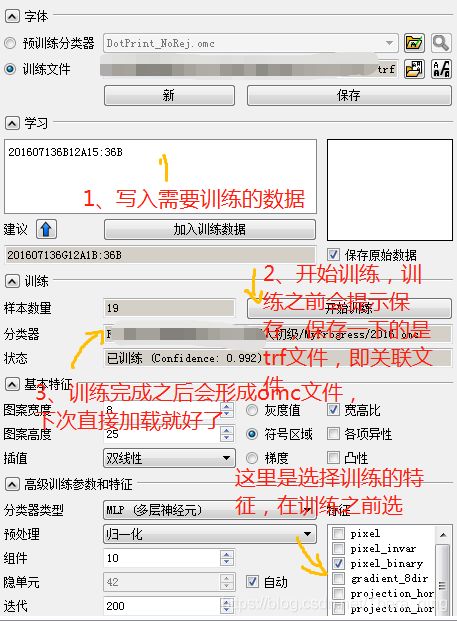
3、添加训练的特征
4、开始训练,形成omc文件
5、下次使用时直接加载刚刚训练的OMC文件就好了
倒着的字符检测
刚刚完成了倾斜字符检测,那么倒着的怎么办?如下

我们的思路还是一样的,首先是矫正,其次是把字符抠出来,最后是识别。
第一步:矫正
这里的矫正很简单,字符是倒挂着的,所以我们就用镜像可以搞定。连续两次镜像便完成了。
mirror_image (Image, ImageMirror, 'row')
mirror_image (ImageMirror, ImageMirror1, 'column')
参数是row表示基于行镜像,即上下镜像,反之左右镜像。
第二步:分割字符
有两个思路,第一个思路是手动把那个矩形区域画出来,然后reduce_domain把区域抠出来,第二个思路就是我们常用的基于Blob分析,也是博主采用的方式。
我们发现这里直接用灰度直方图工具分割很难将矩形区域或者字符分割出来,因为它们之间的灰度相差很近,所以我们想到如果能够提高它们的灰度对比度,在用灰度直方图就很轻松了。这里介绍一个能实现我们想法的工具——缩放。
在镜像后的图像页面,然后还是打开灰度直方图工具,然而不是点击阈值,而是下拉菜单的缩放。

滑动光标,你会发现图像的对比度随着光标的移动而移动,找到你认为合理的位置,即矩形区域与它周围的区域相差很大,外围没关系,等一下选择区域就可以搞定,主要是周围的区域。这是博主选的范围

然后类似的,插入代码即可,(生成的代码调用了scale_image进行图像缩放)接下来就是中规中矩的阈值化threshold,然后想方设法地把26单独抠出来,并且单个字符形成单独的连通域。
首先我们要把字符选择出来,所以阈值化之后打散成单个连通域,通过面积选择先把矩形区域选择出来,通过做差得到矩形区域。
scale_image (ImageMirror1, ImageScaled, 9.10714, -1739)
threshold (ImageScaled, Regions, 0, 142)
connection (Regions, ConnectedRegions)
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 169940, 2.38293e+006)
reduce_domain (ImageMirror1, SelectedRegions, ImageReduced)
最后得到的矩形区域,在一系列操作和你手动画个矩形然后抠图的效果是一样的~~

得到这个区域之后,自然第一步是阈值化,考虑到要把两个字符单独形成连通域,所以我们在打散做形状选择之前先膨胀一下dilation_rectangle1,把字符中间断开的部分连起来,这样打散的时候字符就是一个连通域啦~

此时字符之间就完全连起来啦~
接下来就是打散,然后借助特征直方图根据面积和高度特征把字符选出来啦,这里的特征根据需求自定,一般常用的有area,height, width等,这部分我们在实现相机物体抓取已经展示过了,就不加赘述。然后把选择出来的字符和原来没有膨胀的区域做交集,得到我们需要识别的字符。这一步主要是保证我们识别的字符是原始图像中字符的形状大小。
threshold (ImageReduced, Regions1, 0, 138)
dilation_rectangle1 (Regions1, RegionDilation, 11, 11)
connection (RegionDilation, ConnectedRegions1)
select_shape (ConnectedRegions1, SelectedRegions1, ['height','area'], 'and', [191.99,15306.9], [245.13,21744])
erosion_rectangle1 (SelectedRegions1, RegionErosion, 11, 11)
intersection (RegionErosion, Regions1, RegionIntersection)

第三步:识别
读取分类器,注意选择的是OMC文件是Industrial_0-9_Rej.omc,然后识别,就OK了~
read_ocr_class_mlp ('Industrial_0-9_Rej.omc', OCRHandle)
do_ocr_multi_class_mlp (RegionIntersection, ImageReduced, OCRHandle, Class, Confidence)
识别结果
![]()
第四步:显示
先得到字符的位置
smallest_rectangle1 (RegionIntersection, Row1, Column1, Row2, Column2)
然后遍历显示就好了,注意在这之前要先打开一个窗口
count_obj (RegionIntersection, Number)
dev_display (ImageMirror1)
for Index := 1 to Number by 1
disp_message (WindowHandle, Class[Index-1], 'image', Row2[Index - 1], Column1[Index - 1], 'red', 'false')
endfor

贴一下完整的代码~
dev_close_window ()
read_image (Image, 'F:/字符.bmp')
get_image_size (Image, Width, Height)
dev_open_window (0, 0, Width/4, Height/4, 'black', WindowHandle)
set_display_font (WindowHandle, 60, 'mono', 'true', 'false')
dev_display (Image)
mirror_image (Image, ImageMirror, 'row')
mirror_image (ImageMirror, ImageMirror1, 'column')
scale_image (ImageMirror1, ImageScaled, 9.10714, -1739)
threshold (ImageScaled, Regions, 0, 142)
connection (Regions, ConnectedRegions)
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 169940, 2.38293e+006)
reduce_domain (ImageMirror1, SelectedRegions, ImageReduced)
threshold (ImageReduced, Regions1, 0, 138)
dilation_rectangle1 (Regions1, RegionDilation, 11, 11)
connection (RegionDilation, ConnectedRegions1)
select_shape (ConnectedRegions1, SelectedRegions1, ['height','area'], 'and', [191.99,15306.9], [245.13,21744])
erosion_rectangle1 (SelectedRegions1, RegionErosion, 11, 11)
intersection (RegionErosion, Regions1, RegionIntersection)
read_ocr_class_mlp ('Industrial_0-9_Rej.omc', OCRHandle)
do_ocr_multi_class_mlp (RegionIntersection, ImageReduced, OCRHandle, Class, Confidence)
smallest_rectangle1 (RegionIntersection, Row1, Column1, Row2, Column2)
count_obj (RegionIntersection, Number)
dev_display (ImageMirror1)
for Index := 1 to Number by 1
disp_message (WindowHandle, Class[Index-1], 'image', Row2[Index - 1], Column1[Index - 1], 'red', 'false')
endfor
至此,这个项目就算是告一段落了,下一篇博客进行~