static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //数组默认初始容量:16
static final int MAXIMUM_CAPACITY = 1 << 30; //数组最大容量2 ^ 30 次方
static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认负载因子的大小:0.75
static final int MIN_TREEIFY_CAPACITY = 64; //树形最小容量:哈希表的最小树形化容量,超过此值允许表中桶转化成红黑树
static final int TREEIFY_THRESHOLD = 8; //树形阈值:当链表长度达到8时,将链表转化为红黑树
static final int UNTREEIFY_THRESHOLD = 6; //树形阈值:当链表长度小于6时,将红黑树转化为链表
transient int modCount; // hashmap修改次数
int threshold; //可存储key-value 键值对的临界值 需要扩充时;值 = 容量 * 加载因子
transient int size; //已存储key-value 键值对数量
final float loadFactor; // 负载因子
transient Set< Map.Entry< K,V >> entrySet; //缓存的键值对集合
transient Node< K,V>[] table; //链表数组(用于存储hashmap的数据)
构造方法
空构造方法
Map map = new HashMap<>();
- 底层调用
public HashMap() {
//默认是0.75f
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
put方法
链表形式
map.put("aaa",111);
-
首先调用putVal
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } -
key的hash值的计算
可以看多对key求hash,让key的hashCode的(key的hashCode右移16位)次方来做key的hash值
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } 第一次调用put方法时,也就是第一次调用putVal方法
内部的数组是空的 所以去初始化数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
接下来我们看到resize方法:
- 第一次因为数组是空的,所以oldCap=0,oldThr=0
- 进入else方法,然后初始化默认Cap大小16,阈值newThr=(int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY),也就是0.75f*16=12,所以此时newThr=12,
threshold = newThr; threshold = 12 - 初始化节点数组 Node
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
因为resize方法初始化了数组,接着就会走这个方法
去创建节点,将要put的key喝值放进node节点,然后把这个阶段放到数组的位置
当然是根据key的hash值和数组的长度-1来计算出数组存储索引位置(i = (n - 1) & hash)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
afterNodeInsertion(evict);方法是为了继承HashMap的LinkedHashMap类服务的
LinkedHashMap 是 HashMap 的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用 LinkedHashMap
LinkedHashMap中被覆盖的afterNodeInsertion方法,用来回调移除最早放入Map的对象
后续在LinkedHashMap再做介绍
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
第一次put完成
- 第二次调用put方法并且key不是重复时,也就是调用putVal方法
数组不是空的,所以不会再走初始化数组的分支了,而且如果key的hash值在数组中不存在,直接执行下面方法
,创建一个节点,放到数组
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
结束put
- 第二次put并且key是重复时,key的hash值也相等,调用putVal
这次直接走else方法
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
直接将节点p赋给节点e
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
在执行下面方法,新值覆盖旧值,并返回旧值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
- 第二次put并且不是重复时,key的hash值相等,调用putVal
如:
Stringa="Aa";
Stringb="BB";
这次直接走else方法
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
然后再进入else的else方法
这个方法不会进入,因为这个阈值是8,binCount>=7,则会以红黑树的形式存储,当前我们是以链表形式存储
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
已经存在的节点的下一个指向直到当前插入的节点,也就是p.next = newNode(hash, key, value, null);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
这样就完成put操作了
- 当容量不够,且新的key的hash已经存在,需要扩容时,调用put方法,创新的node让hash的旧值的next指向新值,然后调用resize方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
.......
else {
....
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
.....
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
.....
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
容量翻倍,阈值重新计算,然后将旧数组的数据拷贝到新数组中,这里采用两条链表,当key的hash相同的时候,hash和旧容量取与运算为0时候则用lo的链表,lo的头结点指向旧的数据,lo的尾结点指向新的数据,然后把lo的头结点放到数组。当(e.hash & oldCap) != 0的时候
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
.....
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
红黑树形式
调用下面方法,dir是指针直到的节点和要插入的节点做比较的结果,dir节点插入节点挂在哪里,是在左边还是右边
final TreeNode putTreeVal(HashMap map, Node[] tab,
int h, K k, V v) {
Class kc = null;
boolean searched = false;
TreeNode root = (parent != null) ? root() : this;
for (TreeNode p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node xpn = xp.next;
TreeNode x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
看到左旋方法,对着图理解
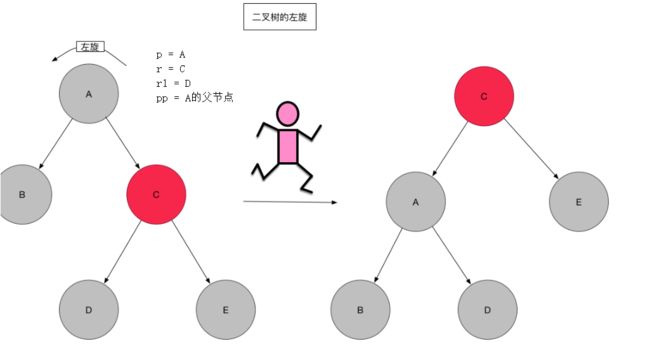
/**
* 左旋
*/
static TreeNode rotateLeft(TreeNode root,
TreeNode p) {
//这里的p即上图的A节点,r指向右孩子即C,rl指向右孩子的左孩子即D,pp为p的父节点
TreeNode r, pp, rl;
if (p != null && (r = p.right) != null) {
if ((rl = p.right = r.left) != null)
rl.parent = p;
//将p的父节点的孩子节点指向r
if ((pp = r.parent = p.parent) == null)
(root = r).red = false;
else if (pp.left == p)
pp.left = r;
else
pp.right = r;
//将p置为r的左节点
r.left = p;
p.parent = r;
}
return root;
}
看到右旋方法,对着图理解
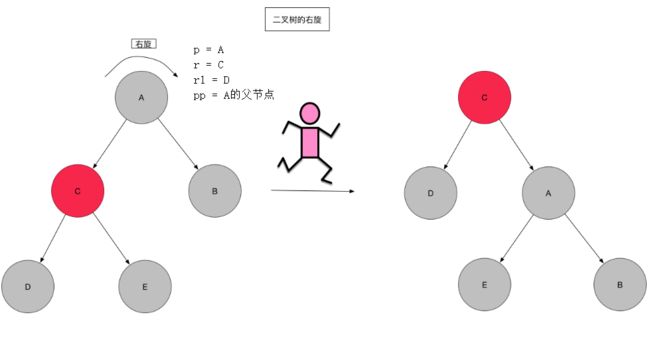
/**
* 右旋
*/
static TreeNode rotateRight(TreeNode root,
TreeNode p) {
//这里的p即上图的A节点,l指向左孩子即C,lr指向左孩子的右孩子即E,pp为p的父节点
TreeNode l, pp, lr;
if (p != null && (l = p.left) != null) {
if ((lr = p.left = l.right) != null)
lr.parent = p;
if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
l.right = p;
p.parent = l;
}
return root;
}
接着看到方法balanceInsertion
现在来看看一个比较麻烦一点的操作,红黑树的插入,首先找到这个节点要插入的位置,即一层一层比较,大的放右边,小的放左边,直到找到为null的节点放入即可,但是如何在插入的过程保持红黑树的特性呢,想想好像比较头疼,但是再仔细想想其实就会发现,其实只有这么几种情况:
1.插入的为根节点,则直接把颜色改成黑色即可。
2.插入的节点的父节点是黑色节点,则不需要调整,因为插入的节点会初始化为红色节点,红色节点是不会影响树的平衡的。
3.插入的节点的祖父节点为null,即插入的节点的父节点是根节点,直接插入即可(因为根节点肯定是黑色)。
4.插入的节点父节点和祖父节点都存在,并且其父节点是祖父节点的左节点。这种情况稍微麻烦一点,又分两种子情况:
i.插入节点的叔叔节点是红色,则将父亲节点和叔叔节点都改成黑色,然后祖父节点改成红色即可。
ii.插入节点的叔叔节点是黑色或不存在:
a.若插入节点是其父节点的右孩子,则将其父节点左旋,
b.若为左孩子,则将其父节点变成黑色节点,将其祖父节点变成红色节点,然后将其祖父节点右旋。
5.插入的节点父节点和祖父节点都存在,并且其父节点是祖父节点的右节点。这种情况跟上面是类似的,分两种子情况:
i.插入节点的叔叔节点是红色,则将父亲节点和叔叔节点都改成黑色,然后祖父节点改成红色即可。
ii.插入节点的叔叔节点是黑色或不存在:
a.若插入节点是其父节点的左孩子,则将其父节点右旋
b.若为右孩子,则将其父节点变成黑色节点,将其祖父节点变成红色节点,然后将其祖父节点左旋。
然后重复进行上述操作,直到变成1或2情况时则结束变换。说半天,可能还是云里雾里,一图胜千言,让我们从无到有构建一颗红黑树,假设插入的顺序为:10,5,9,3,6,7,19,32,24,17(数字是我拍脑袋瞎想的。)
先来插个10,为情景1,直接改成黑色即可,再插入5,为情景2,比10小,放到10的左孩子位置,插入9,比10小,但是比5大,放到5的右孩子位置,此时,为情景4iia,左旋后变成了情景4iib,变色右旋即可完成转化。插入3后为情景4i,将父节点和叔叔节点同时变色即可,插入6不需要调整,插入7后为情景5i,变色即可。插入19不需要调整,插入32,变成了5iib,左旋变色即可,插入24,变成5iia,右旋后变成5i,变色即可,最后插入17,完美
static TreeNode balanceInsertion(TreeNode root,
TreeNode x) {
x.red = true;
for (TreeNode xp, xpp, xppl, xppr;;) {
//情景1:父节点为null
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
//情景2,3:父节点是黑色节点或者祖父节点为null
else if (!xp.red || (xpp = xp.parent) == null)
return root;
//情景4:插入的节点父节点和祖父节点都存在,并且其父节点是祖父节点的左节点
if (xp == (xppl = xpp.left)) {
//情景4i:插入节点的叔叔节点是红色
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
//情景4ii:插入节点的叔叔节点是黑色或不存在
else {
//情景4iia:插入节点是其父节点的右孩子
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
//情景4iib:插入节点是其父节点的左孩子
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
//情景5:插入的节点父节点和祖父节点都存在,并且其父节点是祖父节点的右节点
else {
//情景5i:插入节点的叔叔节点是红色
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
//情景5ii:插入节点的叔叔节点是黑色或不存在
else {
· //情景5iia:插入节点是其父节点的左孩子
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
//情景5iib:插入节点是其父节点的右孩子
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
红黑树数据节点移除
讲完插入,接下来我们来说说删除,删除的话,比插入还要复杂一点,请各位看官先深呼吸,做好阅读准备
之前已经说过,红黑树是一颗特殊的二叉搜索树,所以进行删除操作时,其实是先进行二叉搜索树的删除,然后再进行调整。所以,其实这里分为两部分内容:1.二叉搜索树的删除,2.红黑树的删除调整
二叉搜索树的删除主要有这么几种情景:
情景1:待删除的节点无左右孩子。
情景2:待删除的节点只有左孩子或者右孩子。
情景3:待删除的节点既有左孩子又有右孩子。
对于情景1,直接删除即可,情景2,则直接把该节点的父节点指向它的左孩子或者右孩子即可,情景3稍微复杂一点,需要先找到其右子树的最左孩子(或者左子树的最右孩子),即左(右)子树中序遍历时的第一个节点,然后将其与待删除的节点互换,最后再删除该节点(如果有右子树,则右子树上位)。总之,就是先找到它的替代者,找到之后替换这个要删除的节点,然后再把这个节点真正删除掉。
其实二叉搜索树的删除总体来说还是比较简单的,删除完之后,如果替代者是红色节点,则不需要调整,如果是黑色节点,则会导致左子树和右子树路径中黑色节点数量不一致,需要进行红黑树的调整,跟上面一样,替代节点为其父节点的左孩子与右孩子的情况类似,所以这里只说其为左孩子的情景(PS:上一步的寻找替换节点使用的是右子树的最左节点,所以该节点如果有孩子,只能是右孩子):
情景1:只有右孩子且为红色,直接用右孩子替换该节点然后变成黑色即可
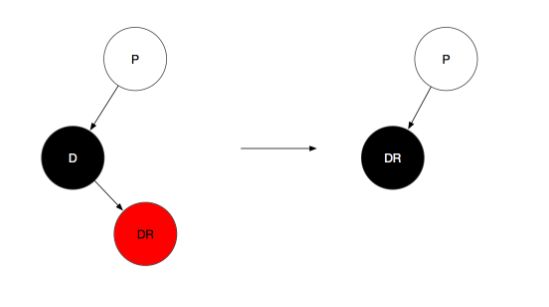
(D代表替代节点,即要被删除的节点,之前在经过二叉搜索树的删除后,D节点其实已经被删除了,这里为了方便理解这个变化过程,所以把这个节点也画出来了,所以当前的初始状态是待删除节点与其替换节点互换位置与颜色之后的状态)
情景2:只有右孩子且为黑色,那么删除该节点会导致父节点的左子树路径上黑色节点减一,此时只能去借助右子树,从右子树中借一个红色节点过来即可,具体取决于右子树的情况,这里又分成两种:
i.兄弟节点是红色,则此时父节点是黑色,且兄弟节点肯定有两个孩子,且兄弟节点的左右子树路径上均有两个黑色节点,此时只需将兄弟节点与父节点颜色互换,然后将父节点左旋,左旋后,兄弟节点的左子树SL挂到了父节点p的右孩子位置,这时会导致p的右子树路径上的黑色节点比左子树多一,此时再SL置为红色即可。

ii.兄弟节点是黑色,那么就只能打它孩子的主意了,这里主要关注远侄子(兄弟节点的右孩子,即SR)的颜色情况,这里分成两种情况:
a.远侄子SR是黑色,近侄子任意(白色代表颜色可为任意颜色),则先将S转为红色,然后右旋,再将SL换成P节点颜色,P涂成黑色,S也涂成黑色,再进行左旋即可。其实简单说就是SL上位,替换父节点位置。
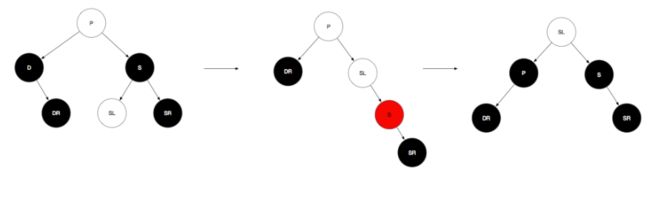
b.远侄子SR为红色,近侄子任意(该子树路径中有且仅有一个黑色节点),则先将兄弟节点与父节点颜色互换,将SR涂成黑色,再将父节点左旋即可。
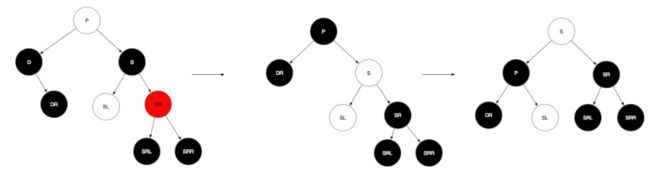
- TreeNode的删除节点
final void removeTreeNode(HashMap map, Node[] tab, boolean movable) {
......
//p是待删除节点,replacement用于后续的红黑树调整,指向的是p或者p的继承者。
//如果p是叶子节点,p==replacement,否则replacement为p的右子树中最左节点
if (replacement != p) {
//若p不是叶子节点,则让replacement的父节点指向p的父节点
TreeNode pp = replacement.parent = p.parent;
if (pp == null)
root = replacement;
else if (p == pp.left)
pp.left = replacement;
else
pp.right = replacement;
p.left = p.right = p.parent = null;
}
//若待删除的节点p时红色的,则树平衡未被破坏,无需进行调整。
//否则删除节点后需要进行调整
TreeNode r = p.red ? root : balanceDeletion(root, replacement);
//p为叶子节点,则直接将p从树中清除
if (replacement == p) { // detach
TreeNode pp = p.parent;
p.parent = null;
if (pp != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
}
}
}
麻烦的地方就在删除节点后的调整了,所有逻辑都在balanceDeletion函数里,两个参数分别表示根节点和删除节点的继承者,来看看它的具体实现:
static TreeNode balanceDeletion(TreeNode root, TreeNode x) {
for (TreeNode xp, xpl, xpr;;) {
//x为空或x为根节点,直接返回
if (x == null || x == root)
return root;
//x为根节点,染成黑色,直接返回(因为调整过后,root并不一定指向删除操作过后的根节点,如果之前删除的是root节点,则x将成为新的根节点)
else if ((xp = x.parent) == null) {
x.red = false;
return x;
}
//如果x为红色,则无需调整,返回
else if (x.red) {
x.red = false;
return root;
}
//x为其父节点的左孩子
else if ((xpl = xp.left) == x) {
//如果它有红色的兄弟节点xpr,那么它的父亲节点xp一定是黑色节点
if ((xpr = xp.right) != null && xpr.red) {
xpr.red = false;
xp.red = true;
//对父节点xp做左旋转
root = rotateLeft(root, xp);
//重新将xp指向x的父节点,xpr指向xp新的右孩子
xpr = (xp = x.parent) == null ? null : xp.right;
}
//如果xpr为空,则向上继续调整,将x的父节点xp作为新的x继续循环
if (xpr == null)
x = xp;
else {
//sl和sr分别为其近侄子和远侄子
TreeNode sl = xpr.left, sr = xpr.right;
if ((sr == null || !sr.red) &&
(sl == null || !sl.red)) {
xpr.red = true; //若sl和sr都为黑色或者不存在,即xpr没有红色孩子,则将xpr染红
x = xp; //本轮结束,继续向上循环
}
else {
//否则的话,就需要进一步调整
if (sr == null || !sr.red) {
if (sl != null) //若左孩子为红,右孩子不存在或为黑
sl.red = false; //左孩子染黑
xpr.red = true; //将xpr染红
root = rotateRight(root, xpr); //右旋
xpr = (xp = x.parent) == null ?
null : xp.right; //右旋后,xpr指向xp的新右孩子,即上一步中的sl
}
if (xpr != null) {
xpr.red = (xp == null) ? false : xp.red; //xpr染成跟父节点一致的颜色,为后面父节点xp的左旋做准备
if ((sr = xpr.right) != null)
sr.red = false; //xpr新的右孩子染黑,防止出现两个红色相连
}
if (xp != null) {
xp.red = false; //将xp染黑,并对其左旋,这样就能保证被删除的X所在的路径又多了一个黑色节点,从而达到恢复平衡的目的
root = rotateLeft(root, xp);
}
//到此调整已经完毕,进入下一次循环后将直接退出
x = root;
}
}
}
//x为其父节点的右孩子,跟上面类似
else { // symmetric
if (xpl != null && xpl.red) {
xpl.red = false;
xp.red = true;
root = rotateRight(root, xp);
xpl = (xp = x.parent) == null ? null : xp.left;
}
if (xpl == null)
x = xp;
else {
TreeNode sl = xpl.left, sr = xpl.right;
if ((sl == null || !sl.red) &&
(sr == null || !sr.red)) {
xpl.red = true;
x = xp;
}
else {
if (sl == null || !sl.red) {
if (sr != null)
sr.red = false;
xpl.red = true;
root = rotateLeft(root, xpl);
xpl = (xp = x.parent) == null ?
null : xp.left;
}
if (xpl != null) {
xpl.red = (xp == null) ? false : xp.red;
if ((sl = xpl.left) != null)
sl.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateRight(root, xp);
}
x = root;
}
}
}
}
}
get方法
调用getNode方法获取数据,如果getNode放法不为空就返回数据
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
看到getNode方法,用要找的key的hash与数组的长度做与运算确定数据是否在数组中,判断数组不为空,并且有头节点
- 当头节点的key是不是与获取的key相等,相等就返回头结点
- 当头节点后面还有节点的情况,又分为链表形式和红黑树形式
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
链表形式
如果要找的key和头结点后面的节点的hash相等,并且key的指向的内存地址相等或者key的名称相等则返回这个节点,否则一直迭代链表
final Node getNode(int hash, Object key) {
//此处省略些代码
........
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
return null;
}
红黑树形式
final Node getNode(int hash, Object key) {
//此处省略些代码
.........
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
.........
return null;
}
看到getTreeNode方法,如果parent节点不为空就调用root找根节点方法,否则调用已经是根节点就用find方法去寻找
final TreeNode getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}
root方法是从根节点找起,用for循环找到最根的节点
final TreeNode root() {
for (TreeNode r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
find方法查找想要的值,就是要找的key和当前key作比较,比当前key小就是在左节点,大则在右节点,依次遍历查找
/*获取红黑树指定节点*/
final TreeNode find(int h, Object k, Class kc) {
TreeNode p = this;// 见213行,此节点p就是根节点,进入循环后p代表当前节点
do {
int ph, dir; K pk;// 定义当前节点p的hash值ph、相对位置dir、key
TreeNode pl = p.left, pr = p.right, q// 获取当前节点的左子节点、右子节点
if ((ph = p.hash) > h)// 表明目标节点在当前节点的左子节点
p = pl;
else if (ph < h)// 表明目标节点在当前节点的右子节点
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))// 当前节点的hash值与目标节点hash值相等,且当前节点的key与目标key相等(equals)
return p;
else if (pl == null)// 当前节点的hash值与目标节点hash值相等,且当前节点的key与目标key不相等(equals)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)// 当前节点的hash值与目标节点hash值相等,且当前节点的key与目标key不相等(equals),且左子节点与右子节点均不为null,目标key实现Comparable接口,且与当前节点比较不为0
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)// 当前节点的hash值与目标节点hash值相等,且当前节点的key与目标key不相等(equals),且左子节点与右子节点均不为null,目标key没有实现Comparable接口,则直接在右子树中查询,这个方法并没有在左子树中循环,因为这是一个递归方法,先遍历右子树并判断是否查找到,若无则将左子树根节点作为当前节点,不用遍历左子树依然可以覆盖全部情况
return q;
else
p = pl;
} while (p != null);
return null;// 未找到,返回null
}