毕昇 JDK:“传奇再现”华为如何打造 ARM 上最好用的 JDK?
文章目录
- 前言
- 一、什么是毕昇 JDK?
-
- 1.1、毕昇 JDK 发展历程
- 1.2、毕昇 JDK 的支持架构
- 1.3、毕昇 JDK、OpenJDK 和 Oracle JDK 区别
- 二、为什么要做毕昇 JDK?
-
- 2.1、Oracle JDK 授权方式发生变化
- 2.2、高版本 JDK 有价值特性的渴望
- 2.3、应用的定制化优化诉求
- 三、毕昇 JDK 现状
-
- 3.1、毕昇 JDK 研发现状
- 3.2、毕昇 JDK 性能提升实例
- 四、毕昇 JDK 的 GC 算法优化
-
- 4.1、并行复制算法的概念
- 4.2、架构对并行复制算法的影响
- 4.3、并行复制算法的流程
- 4.4、算法优化减少 membar 之 Q&A
- 4.5、G1、GC 的优化
- 4.6、ZGC 的优化
- 五、JIT 优化——SVE 算法优化
-
- 5.1、SVE 算法优化相关介绍
- 5.2、SVE 算法优化成果
- 六、软硬协同——鲲鹏 KAE 硬件加速
- 七、毕昇 JDK 还能带来什么价值?
- 八、毕昇 JDK 的未来发展
-
- 8.1、即将面世的功能
- 8.2、未来方向
- 九、如何获得毕昇 JDK 及帮助?
-
- 9.1、JDK 8 的代码仓
- 9.2、JDK 11 的代码仓
- 总结
前言
不知道大家是否听说过亦或是使用过毕昇 JDK,是否从事 Java 工作?是否从事 JVM 底层开发?绝大多数 Java 开发者使用的都是 Oracle 的 JDK 或者是 OpenJDK,本文我们将介绍华为的毕昇 JDK 以及我们所做的相关技术优化,希望能在除上述两者之外提供给大家新的选择。
一、什么是毕昇 JDK?
1.1、毕昇 JDK 发展历程
毕昇 JDK 是华为基于 OpenJDK 定制的开源版本,是一款高性能、可用于生产环境的 OpenJDK 发行版。稳定运行在华为内部 500 多个产品上,在华为内部广泛使用毕昇 JDK,团队积累了丰富的开发经验,解决了实际业务运行中遇到的多个疑难问题。如 crash 等相关问题,我们已经在内部解决。
1.2、毕昇 JDK 的支持架构
- 目前仅支持 Linux/AArch64 架构。欢迎广大开发者小伙伴们下载使用。
- 目前毕昇 JDK 支持 8 和 11 两个 LTS 版本,并且已经全部开源。
1.3、毕昇 JDK、OpenJDK 和 Oracle JDK 区别
我们通过对比和分析毕昇 JDK、OpenJDK 和 Oracle JDK,来帮助大家在挑选 JDK 时有更好的选择。
如下图所示,我们用蓝色的区域代表 OpenJDK,浅黄色和红色分别代表 Oracle JDK 和毕昇 JDK。

以上图为参考,我们可以发现:
- 毕昇 JDK 和 Oracle JDK 一样,都是基于 OpenJDK 定制得到,但是又同时赋予了各自不同的商业特性。比如,我们都知道 OpenJDK 12 添加了一个的新垃圾收集(GC)算法——Shenandoah,但是在 Oracle JDK 的发行中是没有附带的。
- 毕昇 JDK 在基于 OpenJDK 定制的基础上,存在的些许区别,主要来源于对产品功能的一些增强、问题的修复以及和上游特性的合入。
二、为什么要做毕昇 JDK?
2.1、Oracle JDK 授权方式发生变化
- 除去大家“众所周知”的原因之外,不知道大家是否知道,Oracle JDK 在 8u212 版本之后是收费的。于公司而言,结合 JDK 自身存在的安全漏洞问题,综合商业因素考虑的结果就是研发符合自身发展的 JDK。

注:以上数据来自 Oracle 官网。
2.2、高版本 JDK 有价值特性的渴望
JDK 每六个月发行一次新版本,JDK 版本众多,不同功能/特性在不同 JDK 版本。程序员期望在最熟悉的 JDK 上尽可能多的使用高版本中有价值的特性。例如 G1 GC 在 JDK12 中引入了一个特性,把不使用的内存归还给操作系统,该特性在云场景中非常有价值,目前主流使用的还是 JDK8,自研 JDK 中 Blckport 特性能快速满足需求。
2.3、应用的定制化优化诉求
应用在运行的硬件、场景有特殊的诉求,但这些诉求短期难以进入到社区。例如大数据应用在数学方面有较高诉请求,在自研 JDK 中可以针对数学计算做循环开展、指令优化等编译优化技术,加速计算。
三、毕昇 JDK 现状
3.1、毕昇 JDK 研发现状
- 毕昇 JDK 和 Oracle JDK 一样,都是基于开源 OpenJDK 定制得到。同时团队为上游社区贡献了不少有价值的
Patch,涉及到:垃圾回收、JIT、运行时内容等。 - 毕昇 JDK 遵循 GPLv2 版权进行开源,并且可以从官方免费下载二进制。
- 毕昇 JDK采用社区化开发和运营,双周会议,目前有 ARM、宝兰德、麒麟等小伙伴一起参与。毕昇 JDK 社区不仅仅支持 ARM 平台,任何关于 JDK 的问题都可以在毕昇 JDK 社区讨论,都会在第一时间得到回复。
- 在上游社区中,团队目前有 Reviewer 1 名,Committer 1名,Author 8 名共 10 余名同事往社区提交代码。
- 毕昇 JDK 在 ARM 上性能、稳定性表现优异。
3.2、毕昇 JDK 性能提升实例
我们通过在测试环境下运行毕昇 JDK 来分析其优势何在,测试环境如下:
- Model:Taishan 2280V2
- OS:openEuler20.09
- HW:kenpeng 920-6426 2600MHz,128 cores
- JDK:JDK8U262
我们通过比较在 SPECjbb 上的数据可以发现毕昇 JDK 在 critical 和 max 上均有较大的提升:critical 提升 55%,max 提升 16%。

另一方面,在 SPECjvm 上的数据虽然说与上面相比并不是特别明显,但是仍平均提升 4.6%。

四、毕昇 JDK 的 GC 算法优化
4.1、并行复制算法的概念
我们都知道复制是 GC 算法里面很重要的一部分,特别是对于新生代的复制:将 from 区中的活跃对象复制到 to 区中,串行复制算法是仅有一个线程负责这个事情,而这无法满足我们的需要。所以我们用到了并行复制算法,那么什么是并行复制算法呢?

- 对象 A 和 B 在并行复制算法中被不同的线程复制,可能由于:对象 A 和 B 有不同到达路径,不同的线程复制。因为任务均衡的问题,线程可以窃取其他线程的复制任务。
- 例如有两个线程 T1 和 T2 分别复制对象 A 和 B,T1:A→A´;T2:B→B´。
- 在复制时除了复制对象的内容外,还需要使用一个指针(Forwarding Pointer)记录对象转移后地址,防止对象被重复复制。

4.2、架构对并行复制算法的影响
- 多线程的并行工作需要考虑不同架构的内存模型。X86 是一种强内存序架构,ARM 则是一种弱内存序,它们的内存序如下表所示:

- 对于并行复制算法来说,在弱内存序架构下,由于内存序的设计,其他线程可能先观测到转移指针已经更新,但是对象尚未复制。为保证一致性,需要在复制和更新对象头之间插入 membar,在 JVM 关于对象头更新统一抽象为 CAS 函数。
- CAS 在不同的体系结构实现不同,X86 中采用 cmpxchgl 指令;ARM 中采用 Ldaxr/Stlxr 指令。
4.3、并行复制算法的流程
并行复制算法的流程图如下图所示:

- 拷贝对象 obj 到新的对象位置 new_obj;
- 插入 Memory Barrier,对象 obj 通过 CAS 设置转移指针,若成功则执行(3),失败执行(4);
- 将 new_obj 的引用压入栈中,返回 new_obj;
- 撤销之前分配的对象,将 cas 成功线程的 new_obj 返回。
在热点分析中,我们发现复制操作的 60% CPU 消耗在插入 Memory Barrier 上。
4.4、算法优化减少 membar 之 Q&A
Q:如果不插入 Memory barrier,多个线程观察到内存不一致的情况,在什么情况下会引入问题?
A:
- T1:尚未完成对象复制,但是已经将对象入栈。
- T2:从 T1 的线程栈窃取待复制的对象,并对尚未完成复制的对象进行成员变量的复制更新,导致数据不一致。
Q:对于不需要复制成员变量的对象(例如:对象的成员变量全部是非引用类型;对象的成员变量其引用类型全部为NULL,对象本身是原始类型的数组),还有必要使用 Memory Barrier?
A: NO!
Q: 如何识别这些对象?
A:
- 静态分析对象:可以发现对象的成员变量全部是非引用类型、原始类型的数组。已经开源。
- 动态分析对象:通过屏障技术识别。
通过对于并行复制算法的优化,我们分别在 SPECjbb 和 SPECjvm 达到了较好的预期成果,如下图所示:

4.5、G1、GC 的优化
针对 G1 Full GC 优化,Full GC 分为 4 个阶段,分别是:
- Mark:标记整个堆空间的活跃对象,并记录活跃对象。
- Prepare:计算每个活跃对象在就地压缩后的位置。
- Adjust:根据对象新的地址,调整对象成员变量的引用位置。
- Compact:复制对象的内存数据。
Compact 阶段一般是最为耗时的,涉及到内存数据的移动。那么 能否在允许一定浪费空间的前提下,对于活跃对象多的部分分区不移动或者少移动,从而提高算法效率? 我们对活跃对象作下图:

我们可以发现:
- 分区活跃对象占比符合 U 型分布。
- 对 Benchmark 进行研究,有 41.27% 分区活跃对象占比在 98%。
- 减少对象的移动在一定程度上也符合强分代理论的假设。
- 测试发现,对于类似的应用性能有 3~5% 的提高。
我们已经将相关代码贡献到社区,欢迎大家前往查看。
4.6、ZGC 的优化
- 毕昇 JDK 11 是第一个在 ARM 架构中支持 ZGC 的 JDK。
- ZGC 的目标是管理 TB 级内存,且垃圾回收的停顿时间控制在 10 毫秒。ZGC 的回收过程包括 3 步,分别是:并发标记(Mark)、并发转移(Relocate)和并发重定位(Remap)。在转移的过程,为了提高转移的效率,只有当页面的垃圾回收空间达到一定比例才会参与转移。目前的实现中比例通过参数 ZFragmentLimit 控制,该参数的默认值为 25。
- 如何设置 ZFragmentLimit?过大,内存浪费;过小,回收效率低下。
- 在 GC 执行的过程中收集转移的信息(内存转移的速率、转移耗时),并预测下一次 GC 可以转移的内存,使用预测值来控制哪些页面可以参与转移。如下图所示:

- 计算内存的转移速率:

- 预测本次 GC 的转移速率:

- 使用正态分布,并辅以 99% 的置信度。
- 预测本次 GC 的转移耗时:

- 预测本次 GC 的转移字节:

- 对于 Benchmark 的测试表明,效果 3~5% 的提升,代码已经开源,正在往社区同步。
五、JIT 优化——SVE 算法优化
5.1、SVE 算法优化相关介绍
SVE(Scalable Vector Extension)是 ARM AArch64 架构的下一代 SIMD 指令集。
- 支持 SVE1 指令集。
- 自动判断适应 SVE1/NEON
- 支持 Z0~Z31 寄存器。
- 支持从 128~2048 bits 全尺寸 SVE 寄存器。
- 支持 PO~P7 谓词寄存器。
- 支持大部分自动向量化(SuperWord)Node。
5.2、SVE 算法优化成果
VectorAPI 新增 Node 全部贡献到上游社区,毕昇 JDK 目前暂未合入。到目前为止,SVE一共向上游社区提交了 11 个patch,相关代码超过 3000 行。
public static float sumReductionImplement(float[] a, float[] b, float[] c, float[] d, float total) {
for (int i = 0; i < a.length; i++) {
d[i] = (a[i] * b[i]) + (a[i] * c[i]) + (b[i] * c[i]);
total += d[i];
}
return total;
}
优化之后的 NEON 机器代码如下图所示:

优化之后的 SVE 机器代码如下图所示:

六、软硬协同——鲲鹏 KAE 硬件加速
- KAE(Kunpeng Accelerator Engine)是华为鲲鹏服务器提供的硬件加速器,在鲲鹏芯片中有一个独立的 I/O DIE 用于处理加解密功能。
- 毕昇 JDK 提供了 KAEProvider,充分发挥硬件能力,应用只需要简单的适配,无须代码开发,即可使用鲲鹏服务器的硬件能力,提供应用的运行效率。
- 在毕昇 JDK 最新的版本,发布了 4 款加解密算法(AES、Digest、HMAC、RSA),在针对 Benchmark 的测试中,部分算法可以加速 40%,在安全领域将大大节约运行时间。目前和宝兰德正在进行联合开发。第二批算法的支持将于 Q2 发布。
- 加解密方案是基于 JCA(Java Cryptography Architecture,Java 加密架构),是 Java 平台的重要组成部分。KAE 是基于 JCA 来提供加解密服务,在毕昇 JDK 中称为 KAEProvider。流程如下图所示:

- JCA 提供 2 种方式选择不同的 provider,通过代码指定或者配置文件。如下:
- 方式 1:使用 Security API 添加 KAE Provider,并设置其优先级。
- 方式 2:修改 jre/lib/security/java.security 文件,添加 KAE Provider,并设置其优先级。
七、毕昇 JDK 还能带来什么价值?
- 经过评估和测试,毕昇 JDK 目前还以社区的特性为基础 Backport 了一批有价值的特性。
- G1 NUMA一Aware,该特性能充分发挥 NUMA 的优势,在多核的硬件平台中效果更佳。毕昇 JDK 中还在社区的基础上修复了一些问题:例如因为操作系统的线程调度导致线程在多个节点迁移,迁移在 NUMA 特性上会导致一些内存分区无法得到有效回收;增强了大对象的 NUMA一Aware 功能。效果提升如下图所示:

- 在 JDK 10 中 AppCDS 的特性,其思路是将 String 对象,类元数据对象存放到一个共享文件中,让多个 JVM 进程能够通过共享信息,减少类元数据对象的加载、解析。
- 毕昇 JDK 通过移植该特性,测试发现取得良好的效果,对于大数据的一些场景可以优化接近 10%。
- G1 Uncommit,在内存使用较低的情况下,会通过周期性的触发 GC 进行垃圾回收,并将回收后的内存归还给操作系统,该特性对于云场景中,能明显的降低内存的私有量。毕昇 JDK 在社区版本基础上,将串行的内存释放修改为并发(在最新的 JDK 16 中也采用了相同的实现)。
在开启 G1 Uncommit 后,我们可以在下图中看到,在内存不使用的场景中会稳步下降:
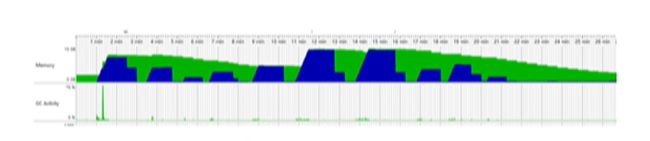
而在实际的业务场景中,效果更是显而易见的,如下图所示:

- 并行任务窃取机制优化,在一些应用发现任务窃取占比很高。对于并行任务窃取 Google 对社区贡献了一个有价值的设计,极大的优化了并行任务窃取。在毕昇 JDK 中,PS、ParNew、G1、Shenandoah 等都因此而受益。

- 目前我们正在针对多核的服务器优化任务窃取,待成熟后会继续开源。
八、毕昇 JDK 的未来发展
8.1、即将面世的功能
- 完善 KAE 硬件加速算法,预计 Q2 发布。
- G1 GC 中并行 NUMA-Aware、Full GC 将落地于毕昇 JDK8,Q2。
- jmap 增强,针对 CMS 做并行 dump。
8.2、未来方向
- 积极参与社区中 SVE、Vector API 特性的开发、演进。目前提交代码超 3000 行。
- 优化内存管理,正在进行:ZGC 分代、Thread Local GC、AOT 等项目。
九、如何获得毕昇 JDK 及帮助?
下载 JDK 8 和 JDK 11:https://kunpeng.huawei.com/#/developer/devkit/complier?data=JDK

9.1、JDK 8 的代码仓
https://gitee.com/openeuler/bishengjdk-8

9.2、JDK 11 的代码仓
https://gitee.com/openeuler/bishengjdk-11

总结
本文我们给大家介绍了何为毕昇 JDK,整体的发展史如何,是在什么样的形势下华为要做毕昇 JDK,在底层的优化方面又做到了哪些?同时又潜藏了哪些值得开发的价值?正为华为编译器资深技术专家彭成寒老师所讲,把数字世界带入每个人、每个家庭、每个组织,构建万物互联的智能世界,这是我们的追求!
我是白鹿,一个不懈奋斗的程序猿。望本文能对你有所裨益,欢迎大家的一键三连!若有其他问题、建议或者补充可以留言在文章下方,感谢大家的支持!