前言
大家好,这一篇文章是MyBatis系列的最后一篇文章,前面两篇文章《MyBatis源码解析(一)—构建篇》和《MyBatis源码解析(二)—执行篇》,主要说明了MyBatis是如何将我们的xml配置文件构建为其内部的Configuration对象和MappedStatement对象的,然后在第二篇我们说了构建完成后MyBatis是如何一步一步地执行我们的SQL语句并且对结果集进行封装的。那么这篇作为MyBatis系列的最后一篇,自然是要来聊聊MyBatis中的一个不可忽视的功能,一级缓存和二级缓存。
何谓缓存?
虽然这篇说的是MyBatis的缓存,但是我希望正在学习计算机的小伙伴即使还没有使用过MyBatis框架也能看明白今天这篇文章。
缓存是什么?我来说说个人的理解,最后再上比较官方的概念。
缓存(Cache),顾名思义,有临时存储的意思。计算机中的缓存,我们可以直接理解为,存储在内存中的数据的容器,这与物理存储是有差别的,由于内存的读写速度比物理存储高出几个数量级,所以程序直接从内存中取数据和从物理硬盘中取数据的效率是不同的,所以有一些经常需要读取的数据,设计师们通常会将其放在缓存中,以便于程序对其进行读取。但是,缓存是有代价的,刚才我们说过,缓存就是在内存中的数据的容器,一条64G的内存条,通常可以买3-4块1T-2T的机械硬盘了,所以缓存不能无节制地使用,这样成本会剧增,所以一般缓存中的数据都是需要频繁查询,但是又不常修改的数据。
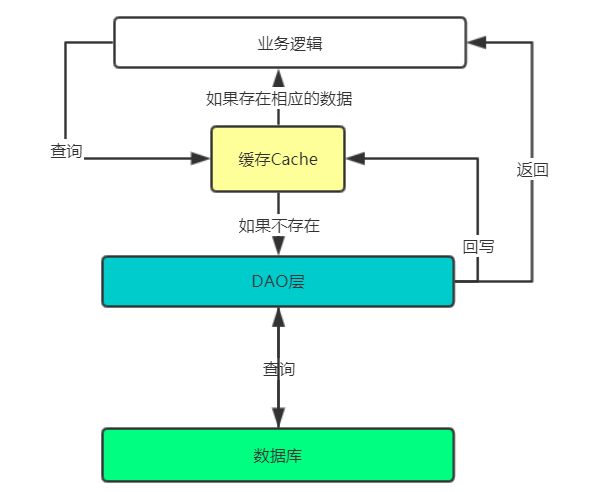
而在一般业务中,查询通常会经过如下步骤。
读操作 --> 查询缓存中已经存在数据 -->如果不存在则查询数据库,如果存在则直接查询缓存-->数据库查询返回数据的同时,写入缓存中。
写操作 --> 清空缓存数据 -->写入数据库
比较官方的概念:
☞ 缓存就是数据交换的缓冲区(称作:Cache),当某一硬件要读取数据时,会首先从缓存汇总查询数据,有则直接执行,不存在时从内存中获取。由于缓存的数据比内存快的多,所以缓存的作用就是帮助硬件更快的运行。 ☞ 缓存往往使用的是RAM(断电既掉的非永久存储),所以在用完后还是会把文件送到硬盘等存储器中永久存储。电脑中最大缓存就是内存条,硬盘上也有16M或者32M的缓存。 ☞ 高速缓存是用来协调CPU与主存之间存取速度的差异而设置的。一般CPU工作速度高,但内存的工作速度相对较低,为了解决这个问题,通常使用高速缓存,高速缓存的存取速度介于CPU与主存之间。系统将一些CPU在最近几个时间段经常访问的内容存在高速缓存,这样就在一定程度上缓解了由于主存速度低造成的CPU“停工待料”的情况。 ☞ 缓存就是把一些外存上的数据保存在内存上而已,为什么保存在内存上,我们运行的所有程序里面的变量都是存放在内存中的,所以如果想将值放入内存上,可以通过变量的方式存储。在JAVA中一些缓存一般都是通过Map集合来实现的。
MyBatis的缓存
在说MyBatis的缓存之前,先了解一下Java中的缓存一般都是怎么实现的,我们通常会使用Java中的Map,来实现缓存,所以在之后的缓存这个概念,就可以把它直接理解为一个Map,存的就是键值对。
-
一级缓存简介
MyBatis中的一级缓存,是默认开启且无法关闭的,一级缓存默认的作用域是一个SqlSession,解释一下,就是当SqlSession被构建了之后,缓存就存在了,只要这个SqlSession不关闭,这个缓存就会一直存在,换言之,只要SqlSession不关闭,那么这个SqlSession处理的同一条SQL就不会被调用两次,只有当会话结束了之后,这个缓存才会一并被释放。
虽说我们不能关闭一级缓存,但是作用域是可以修改的,比如可以修改为某个Mapper。
一级缓存的生命周期:
1、如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用。
2、如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用。
3、SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用。
节选自:https://www.cnblogs.com/happyflyingpig/p/7739749.html
 MyBatis一级缓存简单示意图
MyBatis一级缓存简单示意图 -
二级缓存简介
MyBatis的二级缓存是默认关闭的,如果要开启有两种方式:
-
在mybatis-config.xml中加入如下配置片段
-
在mapper.xml中开启
二级缓存的作用域与一级缓存不同,一级缓存的作用域是一个SqlSession,但是二级缓存的作用域是一个namespace,什么意思呢,你可以把它理解为一个mapper,在这个mapper中操作的所有SqlSession都可以共享这个二级缓存。但是假设有两条相同的SQL,写在不同的namespace下,那这个SQL就会被执行两次,并且产生两份value相同的缓存。
-
MyBatis缓存的执行流程
依旧是用前两篇的测试用例,我们从源码的角度看看缓存是如何执行的。
public static void main(String[] args) throws Exception {
String resource = "mybatis.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
//从调用者角度来讲 与数据库打交道的对象 SqlSession
DemoMapper mapper = sqlSession.getMapper(DemoMapper.class);
Map map = new HashMap<>();
map.put("id","2121");
//执行这个方法实际上会走到invoke
System.out.println(mapper.selectAll(map));
sqlSession.close();
sqlSession.commit();
}
这里会执行到query()方法:
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//二级缓存的Cache,通过MappedStatement获取
Cache cache = ms.getCache();
if (cache != null) {
//是否需要刷新缓存
//在 可以看到首先MyBatis在查询数据时会先看看这个mapper是否开启了二级缓存,如果开启了,会先查询二级缓存,如果缓存中存在我们需要的数据,那么直接就从缓存返回数据,如果不存在,则继续往下走查询逻辑。
接着往下走,如果二级缓存不存在,那么就直接查询数据了吗?答案是否定的,二级缓存如果不存在,MyBatis会再查询一次一级缓存,接着往下看。
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List list;
try {
queryStack++;
//查询一级缓存(localCache)
list = resultHandler == null ? (List) localCache.getObject(key) : null;
if (list != null) {
//对于存储过程有输出资源的处理
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//如果缓存为空,则从数据库拿
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
/**这个是queryFromDatabase的逻辑
* //先往缓存中put一个占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//往一级缓存中put真实数据
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
*/
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
一级缓存和二级缓存的查询逻辑其实差不多,都是先查询缓存,如果没有则进行下一步查询,只不过一级缓存中如果没有结果,那么就直接查询数据库,然后回写一级缓存。
讲到这里其实一级缓存和二级缓存的执行流程就说完了,缓存的逻辑其实都差不多,MyBatis的缓存是先查询一级缓存再查询二级缓存。
但是文章到这里并没有结束,还有一些缓存相关的问题可以聊。
缓存事务问题
不知道这个问题大家有没有想过,假设有这么一个场景,这里用二级缓存举例,因为二级缓存是跨事务的。
假设我们在查询之前开启了事务,并且进行数据库操作:
1.往数据库中插入一条数据(INSERT)
2.在同一个事务内查询数据(SELECT)
3.提交事务(COMMIT)
4.提交事务失败(ROLLBACK)
我们来分析一下这个场景,首先SqlSession先执行了一个INSERT操作,很显然,在我们刚才分析的逻辑基础上,此时缓存一定会被清空,然后在同一个事务下查询数据,数据又从数据库中被加载到了缓存中,此时提交事务,然后事务提交失败了。考虑一下此时会出现什么情况,相信已经有人想到了,事务提交失败之后,事务会进行回滚,那么执行INSERT插入的这条数据就被回滚了,但是我们在插入之后进行了一次查询,这个数据已经放到了缓存中,下一次查询必然是直接查询缓存而不会再去查询数据库了,可是此时缓存和数据库之间已经存在了数据不一致的问题。
问题的根本原因就在于,数据库提交事务失败了可以进行回滚,但是缓存不能进行回滚。
我们来看看MyBatis是如何解决这个问题的。
-
TransactionalCacheManager
这个类是MyBatis用于缓存事务管理的类,我们可以看看其数据结构。
public class TransactionalCacheManager { //事务缓存 private final MapTransactionalCacheManager中封装了一个Map,用于将事务缓存对象缓存起来,这个Map的Key是我们的二级缓存对象,而Value是一个叫做TransactionalCache,顾名思义,这个缓存就是事务缓存,我们来看看其内部的实现。
public class TransactionalCache implements Cache { private static final Log log = LogFactory.getLog(TransactionalCache.class); //真实缓存对象 private final Cache delegate; //是否需要清空提交空间的标识 private boolean clearOnCommit; //所有待提交的缓存 private final Map在TransactionalCache中有一个真实缓存对象Cache,这个真实缓存对象就是我们真正的二级缓存,还有一个 entriesToAddOnCommit,这个Map对象中存放的是所有待提交事务的缓存。
我们在二级缓存执行的代码中,看到在缓存中get或者put结果时,都是叫tcm的对象调用了getObject()方法和putObject()方法,这个对象实际上就是TransactionalCacheManager的实体对象,而这个对象实际上是调用了TransactionalCache的方法,我们来看看这两个方法是如何实现的。
@Override public Object getObject(Object key) { // issue #116 Object object = delegate.getObject(key); if (object == null) { //如果取出的是空,那么放到未命中缓存,并且在查询数据库之后putObject中将本应该放到真实缓存中的键值对放到待提交事务缓存 entriesMissedInCache.add(key); } //如果不为空 // issue #146 //查看缓存清空标识是否为false,如果事务提交了就为true,事务提交了会更新缓存,所以返回null。 if (clearOnCommit) { return null; } else { //如果事务没有提交,那么返回原先缓存中的数据, return object; } } @Override public void putObject(Object key, Object object) { //如果返回的数据为null,那么有可能到数据库查询,查询到的数据先放置到待提交事务的缓存中 //本来应该put到缓存中,现在put到待提交事务的缓存中去。 entriesToAddOnCommit.put(key, object); }在getObject()方法中存在两个分支:
如果发现缓存中取出的数据为null,那么会把这个key放到entriesMissedInCache中,这个对象的主要作用就是将我们未命中的key全都保存下来,防止缓存被击穿,并且当我们在缓存中无法查询到数据,那么就有可能到一级缓存和数据库中查询,那么查询过后会调用putObject()方法,这个方法本应该将我们查询到的数据put到真是缓存中,但是现在由于存在事务,所以暂时先放到entriesToAddOnCommit中。
如果发现缓存中取出的数据不为null,那么会查看事务提交标识(clearOnCommit)是否为true,如果为true,代表事务已经提交了,之后缓存会被清空,所以返回null,如果为false,那么由于事务还没有被提交,所以返回当前缓存中存的数据。
那么当事务提交成功或提交失败,又会是什么状况呢?不妨看看commit和rollback方法。
public void commit() { if (clearOnCommit) { //如果为true,那么就清空缓存。 delegate.clear(); } //把本地缓存刷新到真实缓存。 flushPendingEntries(); //然后将所有值复位。 reset(); } public void rollback() { //事务回滚 unlockMissedEntries(); reset(); }先分析事务提交成功的情况,如果事务正常提交了,那么会有这么几步操作:
- 清空真实缓存。
- 将本地缓存(未提交的事务缓存 entriesToAddOnCommit)刷新到真实缓存。
- 将所有值复位。
我们来看看代码是如何实现的:
private void flushPendingEntries() { //遍历事务管理器中待提交的缓存 for (Map.Entry清空真实缓存就不说了,就是Map调用clear方法,清空所有的键值对。
将未提交事务缓存刷新到真实缓存,首先会遍历entriesToAddOnCommit,然后调用真实缓存的putObject方法,将entriesToAddOnCommit中的键值对put到真实缓存中,这步完成后,还会将未命中缓存中的数据一起put进去,值设置为null。
最后进行复位,将提交事务标识设为false,未命中缓存、未提交事务缓存中的所有数据全都清空。
如果事务没有正常提交,那么就会发生回滚,再来看看回滚是什么流程:
- 清空真实缓存中未命中的缓存。
- 将所有值复位
public void rollback() { //事务回滚 unlockMissedEntries(); reset(); } private void unlockMissedEntries() { for (Object entry : entriesMissedInCache) { //清空真实缓存区中未命中的缓存。 try { delegate.removeObject(entry); } catch (Exception e) { log.warn("Unexpected exception while notifiying a rollback to the cache adapter." + "Consider upgrading your cache adapter to the latest version. Cause: " + e); } } }由于凡是在缓存中未命中的key,都会被记录到entriesMissedInCache这个缓存中,所以这个缓存中包含了所有查询数据库的key,所以最终只需要在真实缓存中把这部分key和对应的value给删除即可。
-
缓存事务总结
简而言之,缓存事务的控制主要是通过TransactionalCacheManager控制TransactionCache完成的,关键就在于TransactionCache中的entriesToAddCommit和entriesMissedInCache这两个对象,entriesToAddCommit在事务开启到提交期间作为真实缓存的替代品,将从数据库中查询到的数据先放到这个Map中,待事务提交后,再将这个对象中的数据刷新到真实缓存中,如果事务提交失败了,则清空这个缓存中的数据即可,并不会影响到真实的缓存。
entriesMissedInCache主要是用来保存在查询过程中在缓存中没有命中的key,由于没有命中,说明需要到数据库中查询,那么查询过后会保存到entriesToAddCommit中,那么假设在事务提交过程中失败了,而此时entriesToAddCommit的数据又都刷新到缓存中了,那么此时调用rollback就会通过entriesMissedInCache中保存的key,来清理真实缓存,这样就可以保证在事务中缓存数据与数据库的数据保持一致。
 缓存事务
缓存事务
一些使用缓存的经验
-
二级缓存不能存在一直增多的数据
由于二级缓存的影响范围不是SqlSession而是namespace,所以二级缓存会在你的应用启动时一直存在直到应用关闭,所以二级缓存中不能存在随着时间数据量越来越大的数据,这样有可能会造成内存空间被占满。
-
二级缓存有可能存在脏读的问题(可避免)
由于二级缓存的作用域为namespace,那么就可以假设这么一个场景,有两个namespace操作一张表,第一个namespace查询该表并回写到内存中,第二个namespace往表中插一条数据,那么第一个namespace的二级缓存是不会清空这个缓存的内容的,在下一次查询中,还会通过缓存去查询,这样会造成数据的不一致。
所以当项目里有多个命名空间操作同一张表的时候,最好不要用二级缓存,或者使用二级缓存时避免用两个namespace操作一张表。
-
Spring整合MyBatis缓存失效问题
一级缓存的作用域是SqlSession,而使用者可以自定义SqlSession什么时候出现什么时候销毁,在这段期间一级缓存都是存在的。
当使用者调用close()方法之后,就会销毁一级缓存。但是,我们在和Spring整合之后,Spring帮我们跳过了SqlSessionFactory这一步,我们可以直接调用Mapper,导致在操作完数据库之后,Spring就将SqlSession就销毁了,一级缓存就随之销毁了,所以一级缓存就失效了。
那么怎么能让缓存生效呢?
1.开启事务,因为一旦开启事务,Spring就不会在执行完SQL之后就销毁SqlSession,因为SqlSession一旦关闭,事务就没了,一旦我们开启事务,在事务期间内,缓存会一直存在。
2.使用二级缓存。
结语
Hello world.
欢迎大家访问我的个人博客:Object's Blog