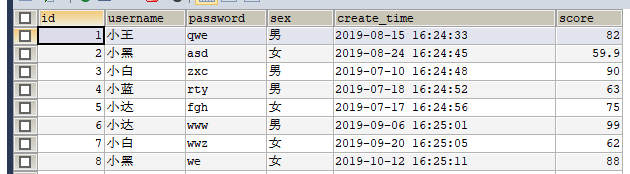
数据库数据:
CONCAT和CONCAT_WS:
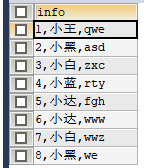
#把信息用CONCAT连接
SELECT CONCAT (id, ',', username, ',', PASSWORD) AS info FROM my_test;
#使用CONCAT_WS,分割符连接,第一个不会加上,最后一个也不会加上!
SELECT CONCAT_WS(',', id,username,PASSWORD) AS info FROM my_test;
GROUP_CONCAT 和GROUP BY:
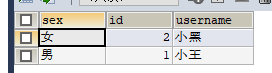
#group by 性别,名字和id会显示不全,并且不能用select *
SELECT sex, id, username FROM my_test GROUP BY sex;
#GROUP_CONCAT解决上面的,按照性别分组后,想要选出这个性别下面的所有名字,可以采用这种方式:select要有sex 然后group by也是sex
#如果不用group by 只有n显示男的! 一般都是结合使用
#注意:GROUP_CONCAT里面可以写distinct order by 这些,还可以决定使用哪种分隔符:username separator ';'
SELECT sex, GROUP_CONCAT(id) AS ids, GROUP_CONCAT(DISTINCT username) AS NAMES FROM my_test GROUP BY sex;

GROUP BY 结合聚合函数:
- group by 从英文里理解就是分组。必须有聚合函数来配合才能使用,使用时至少需要一个分组标志字段
要不然没有意义!除非分组的那个列对应数据刚好只有一个! - 当使用group by子句时则select中关于表的原始属性名只能是被"by"的属性,如上例中的SNO。若想输出其他属性列,则应在select子句后加上相应的聚合函数(count(*),count(列名),sum(列名),avg(列名),max(列名),min(列名))。其实这也很容易理解,当参照SNO被分组后,每一个SNO的具体实例与其他任意一个属性都变成一对一或一对多的关系,只有通过聚合函数将每组其他想要的属性的多个实例算成一个值,即SNO与其形成一对一的关系后才能列出。而且一旦SQL语句中使用了group by子句后聚合函数都变成分别对每组起作用
顺序:先执行group by分组后再执行聚合函数进行对应的计算
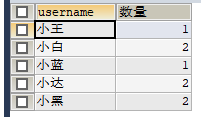
#统计博客种类数量
SELECT username,COUNT(username) AS 数量 FROM my_test GROUP BY username
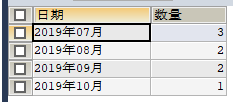
#统计日期归档数量
SELECT DATE_FORMAT(create_time,'%Y年%m月') AS 日期 ,COUNT(create_time) AS 数量 FROM my_test GROUP BY DATE_FORMAT(create_time,'%Y%m')
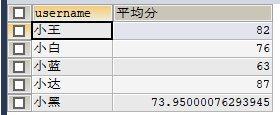
#计算小王所有成绩的的平均分
SELECT username,AVG(score) AS 平均分 FROM my_test GROUP BY username
having和where的用法区别
where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
- having只能用在group by之后,对分组后的结果进行筛选(即使用having的前提条件是分组)。
- where肯定在group by 之前。
- where后的条件表达式里不允许使用聚合函数,而having可以。
比如上面的数据:
SELECT DATE_FORMAT(create_time,'%Y年%m月') AS 日期 ,COUNT(create_time) AS 数量 FROM my_test GROUP BY DATE_FORMAT(create_time,'%Y%m')
如果要筛选出日期归档后 数量大于1的数据:在group by后面加上HAVING COUNT(create_time)>1,
一般来说这个having 后面的条件对应的就是前面选出来的字段基础上加上条件
SELECT DATE_FORMAT(create_time,'%Y年%m月') AS 日期 ,COUNT(create_time) AS 数量 FROM my_test GROUP BY DATE_FORMAT(create_time,'%Y%m') HAVING COUNT(create_time)>1
当一个查询语句同时出现了where,group by,having,order by的时候,执行顺序和编写顺序是:
查询选修了3门以上课程,且所有课程成绩都高于60分的学生学号及课程数
select sno , count(cno),sum(grade) sum_grade
from sc
where grade > 60
group by sno having count(cno) > 3
order by sum_grade desc
1.执行where xx对全表数据做筛选,返回第1个结果集。
2.针对第1个结果集使用group by分组,返回第2个结果集。
3.针对第2个结果集中的每1组数据执行select xx,有几组就执行几次,返回第3个结果集。
4.针对第3个结集执行having xx进行筛选,返回第4个结果集。
5.针对第4个结果集排序order by。
一条SQL语句个子句的先后作用过程:
from→where→group by→select(含聚合函数)→order by
时间分组格式化函数
按年月日分组:
- DATE_FORMAT(create_time,'%Y%m') 也可以加上%Y年%m月
- DATE_FORMAT(create_time,'%Y%m%d')