本文为作者原创,转载请注明地址链接Android消息机制原理,重要性,使用和优化
想写这篇博客很久了,但是一直感觉到自己的不足,很怕自己会去误导别人,所以一直拖到现在,但是我仍然相信会有很多东西是我没想到,了解到的,所以有不足的地方欢迎指正。
关于消息机制博客有太多了,具体有多少,反正我不知道,哈哈哈。但是大部分博客都只分析了原理,讲解了如何使用,对于很多人仍然是一头雾水,所以我从原理,重要性,使用和优化4部分来讲解消息机制
一、消息机制原理
这部分有太多的人去讲解了,有很多人的博客都分析的很好,我这里就不去讲解了,如果大家感兴趣的话,我可以推荐一篇我感觉讲解的最好的:Android消息机制1-Handler(Java层) 博主的其他博客也都很好,基本都是讲解Android原理的,很崇拜大神。在这里主要给大家看根据我自己的理解画的流程图:
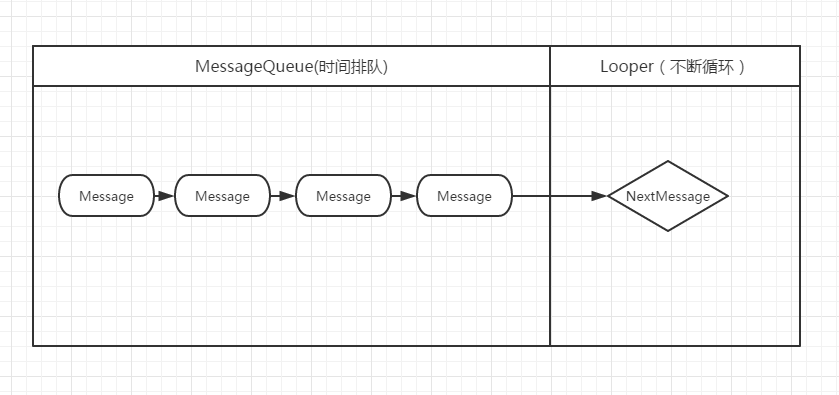
流程图很简单,有些人甚至会很奇怪,因为这里面没有大家很熟悉的Handler,这是故意的,因为他其实不是消息机制的重要组成部分,他其实仅仅是Message的一个属性而已。现在不去看Handler你就会发现消息机制很好理解:Looper循环调用Next去取消息消息队列的第一条消息,消息队列是一个按照时间去排列的消息链表。Handler仅仅是用来将Message加入到MessageQueue和Looper取到消息后执行消息处理的逻辑而已。除此之外有几点仍然要提出来:
- 一个线程只有一个消息队列和一个Looper
- 线程是由有Looper才能有Handler
- NextMessage是阻塞的
以上3点是比较重要的,很多博客都讲到了,1和2就不说了,稍微说下第3点:
- 第一、大家都知道
Message是有执行时间的,如果说头部的消息没有到执行时间线程是处于睡眠状态,当到达头部消息的时间或者消息队列发生改变后线程会被唤醒,这部分代码的控制是Native层的。 - 第二、很多人会有疑问如果阻塞主线程的话程序不就会直接报
ANR了吗?这个问题首先要明白ANR是怎么发生的,是具体原因,不是主线程5s原则,因为疑问本身就是因5s原则来的。好在有先行者已经解释了这个,直接借用传送门,从博客中可以看出是否发生ANR是由Handler判断得出的,所以MessageQueue阻塞不会发生ANR。
二、Handler的重要性
程序的运行是靠消息机制来维持的
开始的时候我比较纠结是先说重要性还是先说原理,因为其实他们差别并不是太大,而且相互关联。
首先说一个面试中会被问到的问题:App程序的入口是什么?JAVA基础好的人或者对源码了解的人都知道,是main方法,不清楚的人才会想到是Application。先来看一下main方法:
public static void main(String[] args) {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "ActivityThreadMain");
SamplingProfilerIntegration.start();
// CloseGuard defaults to true and can be quite spammy. We
// disable it here, but selectively enable it later (via
// StrictMode) on debug builds, but using DropBox, not logs.
CloseGuard.setEnabled(false);
Environment.initForCurrentUser();
// Set the reporter for event logging in libcore
EventLogger.setReporter(new EventLoggingReporter());
// Make sure TrustedCertificateStore looks in the right place for CA certificates
final File configDir = Environment.getUserConfigDirectory(UserHandle.myUserId());
TrustedCertificateStore.setDefaultUserDirectory(configDir);
Process.setArgV0("");
Looper.prepareMainLooper();
ActivityThread thread = new ActivityThread();
thread.attach(false);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
if (false) {
Looper.myLooper().setMessageLogging(new
LogPrinter(Log.DEBUG, "ActivityThread"));
}
// End of event ActivityThreadMain.
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
代码不多,主要有2部分:一部分是环境配置和日志信息设置,另外一部分就和Looper相关,包括主线程的Looper的初始化,Looper的运行。代码的最后一行是抛出RuntimeException异常,正常情况下是不会走到这一步的,走到这里程序就会退出,APP就无法运行了,所以Looper的主题代码是死循环。说到这里,会有人感觉Looper很重要,因为它维持这项目的运行,不让项目异常退出。但是你忽略了一点,代码如何运行的,是MessageQueue,它穿插于整个主线程,维持着项目的不断运行。举个栗子:ActivityThread里面的H,继承于Handler,里面几乎涵盖了四大组件和Application的调用,各个生命周期的代码都是通过他来调用运行的,MessageQueue不断的解析着每一个Message,维持着程序的不断运行。有人会提出View的各种事件,恩,你翻下源码就会发现,那也有Handler。
在一定程度上我们可以说,我们主线程的代码是运行在主线程的消息队列中。
三、消息机制的使用
这部分比较简单,大家对Handler的使用也比较熟悉,就不去讲使用方法了,来看下在源码和框架中的使用:
1、系统源码
在前面提到的Android ANR原理分析中就有关于Handler的延时消息使用方法,其实系统也是通过延时消息来判断你的动作有没有超过规定时间,超过的话系统就认定是ANR。在这里主要看一下AsyncTask中关于Handler的使用 。对于AsyncTask大家应该很熟悉,因为面试中会被大量的提及,其中的方法也比较常用,在源码中也有很明确的标记,doInBackground被添加了WorkThread的标记注解,onPreExecute和onPostExecute也被添加了MainThread的标记注解,表明了他们各自的工作线程。这里就主要看下他们之间的切换是如何进行的,先来看下AsyncTask的初始化:
public AsyncTask() {
mWorker = new WorkerRunnable() {
public Result call() throws Exception {
mTaskInvoked.set(true);
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
//noinspection unchecked
Result result = doInBackground(mParams);
Binder.flushPendingCommands();
return postResult(result);
}
};
mFuture = new FutureTask(mWorker) {
@Override
protected void done() {
try {
postResultIfNotInvoked(get());
} catch (InterruptedException e) {
android.util.Log.w(LOG_TAG, e);
} catch (ExecutionException e) {
throw new RuntimeException("An error occurred while executing doInBackground()",
e.getCause());
} catch (CancellationException e) {
postResultIfNotInvoked(null);
}
}
};
}
代码比较简单清楚,初始化了WorkerRunnable和FutureTask,在WorkerRunnable中我们看到了doInBackground,运行在Runnable(也就是工作线程)中,得到了结果Result ,然后发送出去,我们看下发送代码postResult:
private Result postResult(Result result) {
@SuppressWarnings("unchecked")
Message message = getHandler().obtainMessage(MESSAGE_POST_RESULT,
new AsyncTaskResult(this, result));
message.sendToTarget();
return result;
}
很熟悉的代码,构建Message然后发送出去,再来看下获取Handler的代码:
private static Handler getHandler() {
synchronized (AsyncTask.class) {
if (sHandler == null) {
sHandler = new InternalHandler();
}
return sHandler;
}
}
构建一个静态的Handler
private static class InternalHandler extends Handler {
public InternalHandler() {
super(Looper.getMainLooper());
}
@SuppressWarnings({"unchecked", "RawUseOfParameterizedType"})
@Override
public void handleMessage(Message msg) {
AsyncTaskResult result = (AsyncTaskResult) msg.obj;
switch (msg.what) {
case MESSAGE_POST_RESULT:
// There is only one result
// 这个mTask就是AsyncTask本身
result.mTask.finish(result.mData[0]);
break;
case MESSAGE_POST_PROGRESS:
result.mTask.onProgressUpdate(result.mData);
break;
}
}
}
super(Looper.getMainLooper()); 这个地方表明了这个Handler处理的是主线程的消息,如此就将子线程的结果发送到了主线程。
结果处理,onPostExecute的调用:
private void finish(Result result) {
if (isCancelled()) {
onCancelled(result);
} else {
onPostExecute(result);
}
mStatus = Status.FINISHED;
}
线程执行,onPreExecute的调用:
@MainThread
public final AsyncTask execute(Params... params) {
return executeOnExecutor(sDefaultExecutor, params);
}
@MainThread
public final AsyncTask executeOnExecutor(Executor exec,
Params... params) {
if (mStatus != Status.PENDING) {
switch (mStatus) {
case RUNNING:
throw new IllegalStateException("Cannot execute task:"
+ " the task is already running.");
case FINISHED:
throw new IllegalStateException("Cannot execute task:"
+ " the task has already been executed "
+ "(a task can be executed only once)");
}
}
mStatus = Status.RUNNING;
onPreExecute();
//线程池执行线程
mWorker.mParams = params;
exec.execute(mFuture);
return this;
}
通过上面就可以很清晰的看到由主线程(onPreExecute)到子线程(doInBackground)再到主线程(onPostExecute)的切换流程。
2、框架源码
上面我们分析了AsyncTask,这个地方我们也分析一个相对的网络框架,现在说到网络框架最火的应该是Retrofit了,就看下他是如何进行线程之间的切换的。这里换个方法,不先分析源码,用Debug的方式来看一下:
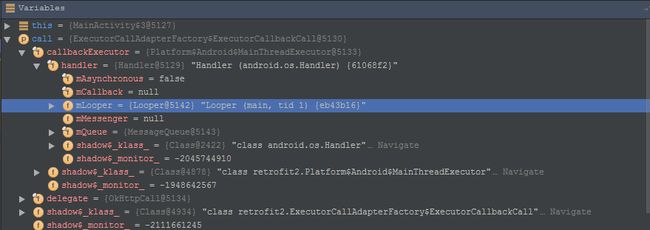
通过上面的Debug可以看到,在回调的时候也使用了基于MainLooper的Handler,所以切换原理也应该是相似的,再来看下源码,根据Debug图片我们能够很清晰的找到源码的路径:
static class Android extends Platform {
@Override public Executor defaultCallbackExecutor() {
return new MainThreadExecutor();
}
@Override CallAdapter.Factory defaultCallAdapterFactory(Executor callbackExecutor) {
return new ExecutorCallAdapterFactory(callbackExecutor);
}
static class MainThreadExecutor implements Executor {
private final Handler handler = new Handler(Looper.getMainLooper());
@Override public void execute(Runnable r) {
handler.post(r);
}
}
}
通过Looper.getMainLooper()就很明白了,这个地方也是在处理主线程的消息队列
另外稍微提一下RxAndroid,这个现在最有名的线程切换框架,直接看源码:
private AndroidSchedulers() {
RxAndroidSchedulersHook hook = RxAndroidPlugins.getInstance().getSchedulersHook();
Scheduler main = hook.getMainThreadScheduler();
if (main != null) {
mainThreadScheduler = main;
} else {
mainThreadScheduler = new LooperScheduler(Looper.getMainLooper());
}
}
class LooperScheduler extends Scheduler {
...
LooperScheduler(Looper looper) {
handler = new Handler(looper);
}
LooperScheduler(Handler handler) {
this.handler = handler;
}
....
}
这里只贴了关键代码,就不解释了,感兴趣的可以自己去看一看。
通过上面一系列的分析应该能了解线程之间如何切换,那么剩下的代码也仅仅是归类封装而已,大家如果有兴趣可以写一些自己的框架,那样就能有更加深刻的理解了。
四、消息机制的优化
在消息机制的重要性中就提到了它在整个程序中扮演的角色,因此合理的使用消息队列也能够优化自己的程序。在说优化之前,先推荐一篇博客Android消息机制2-Handler(Native层),本来这个应该放在第一部分原理中,但是这个比较适合想对消息机制进一步了解的人来看,之所以放在这个地方是因为博客中的一段话适合这一部分:
消息处理流程是先处理Native Message,再处理Native Request,最后处理Java Message。理解了该流程,也就明白有时上层消息很少,但响应时间却较长的真正原因。
看到这句话,在以后对程序的优化上面应该能有一定的帮助。
除此之外,关于相对于消息队列的优化部分,提一个MessageQueue的一个接口IdleHandler,关于这个我曾经写过:MessageQueue中的IdleHandler,这个接口会在MessageQueue空闲的时候调用执行,对于一些不是特别紧急的逻辑可以放在这里面执行。Google后来也专门出了相关的类:JobScheduler ,当然这个类更加全面,不仅仅有空闲时候,还监控了其他很多状态,感兴趣的朋友可以去了解一下,但是这个类是在5.0中加入的,如果想低版本支持,我建议大家直接使用IdleHandler自己去封装,具体代码可以参考Glide。
结语:转身看看了博客,发现没有什么太多原理性的东西,很多都是归纳总结别人的东西,真的是站在巨人的肩膀上面。说了这么多可能会有不正确的地方,肯定会有漏掉的地方,欢迎大家交流指正。