OpenVINO开发教程之八 – 道路分割
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自:opencv学堂
模型介绍
基于OpenVINO预训练模块中的道路分割模型,实现像素级别的图像分割,把像素划分为如下四个类别
背景
道路
车道线
标志
输入数据
要求输入图像BGR通道顺序的彩色图像,blob的大小为
BCHW = Nx3x512x896,其中
B表示批次数目
C表示图像通道
H表示图像高度
W表示图像宽度
输出数据
输出数据是四通道blob对象,格式为BCHW
其中C=4表示输出的四个分类得分,H表示feature map的高度, W表示featuremap的宽度,对输出blob进行解析可以得到输出的分割mask,对mask进行配色之后,得到最终的输出结果。
代码实现
1. 基于OpenVINO SDK开发完成演示程序,模型加载与创建推断请求的代码如下:
C++版本
// 加载道路分割网络
CNNNetReader network_reader;
network_reader.ReadNetwork(model_xml);
network_reader.ReadWeights(model_bin);
// 请求网络输入与输出信息
auto network = network_reader.getNetwork();
InferenceEngine::InputsDataMap input_info(network.getInputsInfo());
InferenceEngine::OutputsDataMap output_info(network.getOutputsInfo());
// 设置输入精度
InputInfo::Ptr& input = input_info.begin()->second;
auto inputName = input_info.begin()->first;
input->setPrecision(Precision::U8);
input->getInputData()->setLayout(Layout::NCHW);
/** 设置输出精度与内容**/
DataPtr& output = output_info.begin()->second;
auto outputName = output_info.begin()->first;
const SizeVector outputDims = output->getTensorDesc().getDims();
output->setPrecision(Precision::FP32);
output->setLayout(Layout::NCHW);
size_t N = outputDims[0];
size_t C = outputDims[1];
size_t H = outputDims[2];
size_t W = outputDims[3];
size_t image_stride = W*H*C;
// 创建可执行网络对象
auto executable_network = plugin.LoadNetwork(network, {});
// 请求推断图
InferRequest::Ptr async_infer_request_next = executable_network.CreateInferRequestPtr();
InferRequest::Ptr async_infer_request_curr = executable_network.CreateInferRequestPtr();Python版本
# 加载IR
log.info("Reading IR...")
net = IENetwork(model=model_xml, weights=model_bin)
# 获取输入输出层
input_blob = next(iter(net.inputs))
out_blob = next(iter(net.outputs))
log.info("Loading IR to the plugin...")
# 创建可执行网络
exec_net = plugin.load(network=net, num_requests=2)
# Read and pre-process input image
n, c, h, w = net.inputs[input_blob].shape
del net
# 开始视频文件或者摄像头
cap = cv2.VideoCapture("D:/images/video/CarsDrivingUnderBridge.mp4")
# cap = cv2.VideoCapture(0)
cur_request_id = 0
next_request_id = 1
log.info("Starting inference in async mode...")
log.info("To switch between sync and async modes press Tab button")
log.info("To stop the demo execution press Esc button")
is_async_mode = True
render_time = 0
# 读取视频流
ret, frame = cap.read()
initial_w = cap.get(3)
initial_h = cap.get(4)2. 检查异步返回与解析输出数据的代码如下
C++版本
if (OK == async_infer_request_curr->Wait(IInferRequest::WaitMode::RESULT_READY)) {
const Blob::Ptr output_blob = async_infer_request_curr->GetBlob(outputName);
const float* output_data = output_blob->buffer().as();
Mat result = Mat::zeros(Size(W, H), CV_8UC3);
for (size_t h = 0; h < H; ++h) {
for (size_t w = 0; w < W; ++w) {
int index = 0;
float max = -100;
for (size_t ch = 0; ch < C; ++ch) {
float data = output_data[W * H * ch + W * h + w];
if (data > max) {
index = ch;
max = data;
}
}
result.at(h, w) = lut[index];
}
}
// 计算FPS
auto t1 = std::chrono::high_resolution_clock::now();
ms dtime = std::chrono::duration_cast(t1 - t0);
std::ostringstream out;
out << "Detection time : " << std::fixed << std::setprecision(2) << dtime.count()
<< " ms (" << 1000.f / dtime.count() << " fps)";
resize(result, result, curr_frame.size());
putText(curr_frame, out.str(), Point(20, 20), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(0, 0, 255), 2, 8);
addWeighted(result, 0.2, curr_frame, 0.8, 0, curr_frame);
} Python版本
if exec_net.requests[cur_request_id].wait(-1) == 0:
# 解析mask输出
res = exec_net.requests[cur_request_id].outputs[out_blob]
# 降维
res = np.squeeze(res, 0)
# 矩阵转置
res = res.transpose((1, 2, 0))
# 获取类别 index,
# 0 - 表示背景,
# 1 - 道路,
# 2 - 车道线 ,
# 3 - 交通标志
res = np.argmax(res, 2)
hh, ww = res.shape
mask = np.zeros((hh, ww, 3), dtype=np.uint8)
mask[np.where(res > 0)] = (0, 255, 255)
mask[np.where(res > 1)] = (255, 0, 255)
# 显示mask
cv2.imshow("segmentation mask", mask)
mask = cv2.resize(mask, dsize=(frame.shape[1], frame.shape[0]))
# print("final shape : ", res.shape)
frame = cv2.addWeighted(mask, 0.4, frame, 0.6, 0)
inf_end = time.time()
det_time = inf_end - inf_start
# 显示绘制文本
inf_time_message = "Inference time: {:.3f} ms, FPS:{:.3f}".format(det_time * 1000, 1000 / (det_time * 1000 + 0.1))
render_time_message = "OpenCV rendering time: {:.3f} ms".format(render_time * 1000)
async_mode_message = "Async mode is on. Processing request {}".format(cur_request_id) if is_async_mode else \
"Async mode is off. Processing request {}".format(cur_request_id)
cv2.putText(frame, inf_time_message, (15, 15), cv2.FONT_HERSHEY_COMPLEX, 0.5, (255, 255, 0), 1)
cv2.putText(frame, render_time_message, (15, 30), cv2.FONT_HERSHEY_COMPLEX, 0.5, (10, 10, 200), 1)
cv2.putText(frame, async_mode_message, (10, int(initial_h - 20)), cv2.FONT_HERSHEY_COMPLEX, 0.5,
(10, 10, 200), 1)运行效果
输入视频帧

道路分割模型输出mask
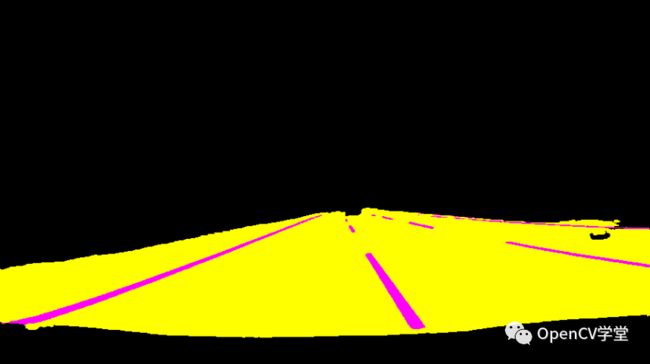
最终显示效果

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

