1、运用haproxy实现nginx服务负载均衡
测试环境:
Nginx1: 172.16.100.151 port:80
Nginx2:172.16.100.155 port:80
Haproxy:172.16.100.156
安装环境
1.Nginx安装过程略
2.配置nginx方便测试效果
修改nginx安装目录下/html/index.html文件的内容,方便测试效果
172.16.100.155--index.html
172.16.100.151--index.html
检查nginx配置文件,并启动/重启
3.安装haproxy
这里采用的是yum安装haproxy1.5
haproxy-1.5
4.配置haproxy
Yum安装haproxy在默认目录/etc/haproxy下,配置文件为haproxy.cfg
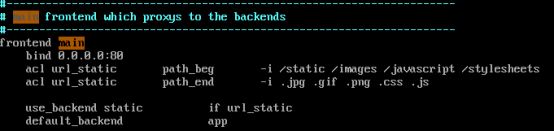
修改配置文件端口
修改bind ip:端口
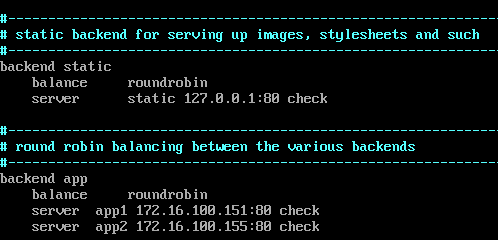
修改backend app地址
修改backend app地址
此处仅做测试,所以backend static没有做过多修改,直接改为本机地址。
5.测试负载
访问172.16.100.156,可以看到结果
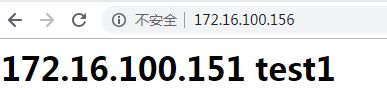
强制刷新后
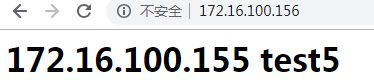
反复刷新可以发现实现了轮询效果
6.测试高可用
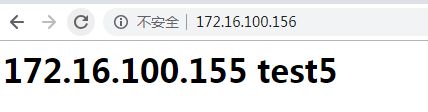
保持其他设置不变,关掉172.16.100.151的nginx,刷新172.16.100.156发现页面停留在172.16.100.155
2、搭建haproxy实现mysql负载均衡
1.Mysql安装过程略过
2.配置mysql
配置172.16.100.151的mysql
编辑/etc/my.cnf文件,在mysqld模块加入以下内容:
server-id=1 #server的唯一标识
auto_increment_offset=1 #自增id起始值
auto_increment_increment=2 #每次自增数字
log-bin = mysql-bin #打开二进制功能,MASTER主服务器必须打开此项
max_binlog_size=1024M #binlog单文件最大值
replicate-ignore-db = mysql #忽略不同步主从的数据库
replicate-ignore-db = information_schema
replicate-ignore-db = performance_schema
replicate-ignore-db = test
保存修改,重启mysql服务,检查端口,服务等是否正常
进入mysql,为mysql添加主从同步用账户
mysql> grant replication slave on *.* to 'repl'@'172.16.100.155' identified by '123456';
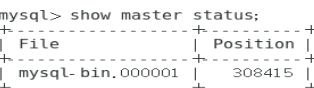
mysql> show master status; 在172.16.100.151上查看master状态
在151机的mysql内再执行:
mysql> change master to master_host='172.16.100.155',\
master_port=3306,master_user='repl',master_password='123456',\
master_log_file='mysql-bin.000001',master_log_pos=120;
Mysql-bin二进制文件对应155的二进制文件,master_log_pos对应155的position
mysql> start slave; 开启主从服务
mysql> show slave status\G; 查看状态
主从同步成功。
配置172.16.100.155的mysql
两者过程大致相同
编辑/etc/my.cnf文件,在mysqld模块加入以下内容:
server-id=2 #server的唯一标识,不可重复
auto_increment_offset=1 #自增id起始值
auto_increment_increment=2 #每次自增数字,一共有几台mysql则为几,此处一共两台mysql,故而设为2
log-bin = mysql-bin #打开二进制功能,MASTER主服务器必须打开此项
max_binlog_size=1024M #binlog单文件最大值
replicate-ignore-db = mysql #忽略不同步主从的数据库
replicate-ignore-db = information_schema
replicate-ignore-db = performance_schema
replicate-ignore-db = test
保存修改,重启mysql服务,检查端口,服务等是否正常
进入mysql,为mysql添加主从同步用账户
mysql> grant replication slave on *.* to 'repl'@'172.16.100.151' identified by '123456';
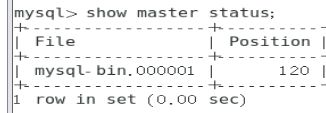
mysql> show master status; 在172.16.100.155上查看master状态
在155机的mysql内再执行:
mysql> change master to master_host='172.16.100.151',\
master_port=3306,master_user='repl',master_password='123456',\
master_log_file='mysql-bin.000001',master_log_pos=308415;
Mysql-bin二进制文件对应151的二进制文件,master_log_pos对应151的position
mysql> start slave; 开启主从服务
mysql> show slave status\G; 查看状态
备注:
如果出现slave_IO_running:NO的情况,在确保网络,数据库权限都正常的情况下,一般是由于所要连接的主库position值发生变化,导致在建立主从时没有对应上正确的position,一般原因是主库数据库存在读写过程。
3.配置haproxy实现mysql负载均衡
在haproxy机172.16.100.156上
修改haproxy配置文件内容:global
daemon
nbproc 1
pidfile /var/run/haproxy.pid
defaults
mode tcp #默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK
retries 2 #两次连接失败就认为是服务器不可用,也可以通过后面设置
option redispatch #当serverId对应的服务器挂掉后,强制定向到其他健康的服务器
option abortonclose #当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
maxconn 4096 #默认的最大连接数
timeout connect 5000ms #连接超时
timeout client 30000ms #客户端超时
timeout server 30000ms #服务器超时
#timeout check 2000 #=心跳检测超时
log 127.0.0.1 local0 err #[err warning info debug]
########test1配置#################
listen test1
bind 0.0.0.0:3306
mode tcp
#maxconn 4086
#log 127.0.0.1 local0 debug
server s1 172.16.100.151:3306
server s2 172.16.100.155:3306
########frontend配置##############
重新启动haproxy,连接mysql测试即可
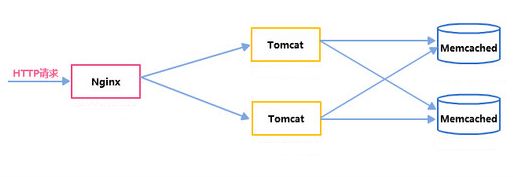
3、搭建tomcat服务器,并通过nginx反向代理访问
https://www.jianshu.com/p/a3713dc1fd38
4、搭建Tomcat,并基于memcached实现会话共享
Memcached是一款免费、开源、分布式的内存对象缓存系统, 用于减少数据库的负载, 加快web应用程序的访问. Memcached简单并且强大, 其简单的设计加快了部署, 易于开发, 缓存解决了面临的大量数据时很多的问题.
[root@mem-node1 ~]# yum -y install libevent libevent-devel
[root@mem-node1 ~]# cd /usr/local/src/
[root@mem-node1 src]# ll memcached-1.4.34.tar.gz
-rw-r--r-- 1 root root 391131 Jun 27 07:41 memcached-1.4.34.tar.gz
[root@mem-node1 src]# tar -zvxf memcached-1.4.34.tar.gz
[root@mem-node1 src]# cd memcached-1.4.34
[root@mem-node1 memcached-1.4.34]# ./configure --prefix=/usr/local/memcached
[root@mem-node1 memcached-1.4.34]# make && make install
启动memcached,端口11211可以根据自己需要修改不同端口
[root@mem-node1 ~]# /usr/local/memcached/bin/memcached -d -m 512 -u root -p 11211 -c 1024 -P /var/lib/memcached.11211pid
查看memcached进程是否起来
[root@mem-node1 ~]# ps -ef|grep memcached
root 1340 1 0 14:34 ? 00:00:00 /usr/local/memcached/bin/memcached -d -m 512 -u root -p 11211 -c 1024 -P /var/lib/memcached.11211pid
root 1400 16303 0 14:35 pts/0 00:00:00 grep memcached
[root@mem-node1 ~]# lsof -i:11211
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
memcached 1340 root 26u IPv4 18958545 0t0 TCP *:memcache (LISTEN)
memcached 1340 root 27u IPv6 18958546 0t0 TCP *:memcache (LISTEN)
memcached 1340 root 28u IPv4 18958549 0t0 UDP *:memcache
memcached 1340 root 29u IPv4 18958549 0t0 UDP *:memcache
memcached 1340 root 30u IPv4 18958549 0t0 UDP *:memcache
memcached 1340 root 31u IPv4 18958549 0t0 UDP *:memcache
memcached 1340 root 32u IPv6 18958550 0t0 UDP *:memcache
memcached 1340 root 33u IPv6 18958550 0t0 UDP *:memcache
memcached 1340 root 34u IPv6 18958550 0t0 UDP *:memcache
memcached 1340 root 35u IPv6 18958550 0t0 UDP *:memcache
测试一下memcached连接,如下说明成功(输入quit退出)
[root@mem-node1 ~]# telnet 192.168.10.203 11211
Trying 192.168.10.203...
Connected to 192.168.10.203.
Escape character is '^]'.
[root@Tomcat-node1 ~]# cd /usr/local/src/MSM_Software
[root@Tomcat-node1 MSM_Software]# ll
total 1212
-rw-rw-r--. 1 root root 53259 Aug 27 09:53 asm-5.2.jar
-rw-rw-r--. 1 root root 323740 Aug 27 09:51 kryo-4.0.0.jar
-rw-rw-r--. 1 root root 85217 Aug 27 09:51 kryo-serializers-0.38.jar
-rw-rw-r--. 1 root root 152401 Aug 27 09:49 memcached-session-manager-1.9.7.jar
-rw-rw-r--. 1 root root 10788 Aug 27 09:49 memcached-session-manager-tc8-1.9.7.jar
-rw-rw-r--. 1 root root 5711 Aug 27 09:52 minlog-1.3.0.jar
-rw-rw-r--. 1 root root 37160 Aug 27 09:51 msm-kryo-serializer-1.9.7.jar
-rw-rw-r--. 1 root root 51287 Aug 27 09:53 objenesis-2.4.jar
-rw-rw-r--. 1 root root 20883 Aug 27 09:52 reflectasm-1.11.3.jar
-rw-rw-r--. 1 root root 472838 Aug 27 09:50 spymemcached-2.12.2.jar
特别注意:
memcached-session-manager-tc8-1.9.7.jar中的tc8为tomcat的版本号。
一定要注意:不同版本号的tomcat,对应的msm包也不同。此处为tomcat8的jar包。
需要把上面这些MSM依赖的jar包下载后全部上传到两台机器的tomcat安装路径的lib/ 目录下
[root@Tomcat-node1 MSM_Software]# \cp -rf /usr/local/src/MSM_Software/* /usr/local/tomcat8/lib/
接下来进行序列化tomcat配置,序列化tomcat配置的方法有很多种:
java默认序列化tomcat配置、javolution序列化tomcat配置、xstream序列化tomcat配置、flexjson序列化tomcat配置和kryo序列化tomcat配置。
官网介绍说 使用kryo序列化tomcat的效率最高,所以这里只介绍kryo序列化。
在No-Stick模式和Stick模式下context.xml文件配置也有所不同(一般用的是No-Stick模式)
只需要修改conf/context.xml文件:
[root@Tomcat-node1 ~]# cd /usr/local/tomcat8/conf/
[root@Tomcat-node1 conf]# cp context.xml context.xml.bak
a)No-Stick模式
记住:多个tomcat实例时 需要选择Non-Sticky模式,即sticky="false"
[root@Tomcat-node1 conf]# vim context.xml #在
.......
memcachedNodes="n1:192.168.10.203:11211,n2:192.168.10.205:11211" lockingMode="auto" sticky="false" sessionBackupAsync="false" sessionBackupTimeout= "1000" copyCollectionsForSerialization="true" requestUriIgnorePattern=".*\.(ico|png|gif|jpg|css|js)$" transcoderFactoryClass="de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory" /> 第一台tomcat节点的congtext.xml配置好之后,再将该文件拷贝到另一台tomcat节点的相同路径下 b) Stick模式。 故障转移配置节点(failoverNodes),不能使用在Non-Sticky模式,多个使用空格或逗号分开,配置某个节点为备份节点。 当其他节点都不可用时才会存储到备份节点,适用于sticky模式(即一台tomcat,多台memcached)。 [root@Tomcat-node1 conf]# vim context.xml ...... memcachedNodes="n1:192.168.10.203:11211,n2:192.168.10.205:11211" #多个memcached之间用空格或逗号隔开都可以的 sticky="true" failoverNodes="n2" requestUriIgnorePattern=".*\.(png|gif|jpg|css|js|swf|flv)$" transcoderFactoryClass="de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory" copyCollectionsForSerialization="true" /> 第一台tomcat节点的congtext.xml配置好之后,再将该文件拷贝到另一台tomcat节点的相同路径下,并将failoverNodes后面的参数改为n1 配置好之后,一定要记得重启两台机器的tomcat服务! [root@Tomcat-node1 ~]# /usr/local/tomcat8/bin/shutdown.sh #或者直接使用kill杀死 [root@Tomcat-node1 ~]# lsof -i:8080 [root@Tomcat-node1 ~]# /usr/local/tomcat8/bin/startup.sh ====================================================================================== Manager 各参数说明: memcachedNodes 必选项,memcached的节点信息,多个memcached节点,中间需要使用空格 failoverNodes="n2" 表示当前session保持到n1的memcached节点上 failoverNodes 可选项,不能使用在non-sticky sessions模式。故障转移配置节点,多个使用空格或逗号分开,配置某个节点为备份节点, 当其他节点都不可用时才会存储到备份节点,官方建议配置为和tomcat同服务器的节点。 理由如下: 假如有两台服务器m1,m2,其中m1部署tomcat和memcached节点n1,m2部署memcached节点n2。 如果配置tomcat的failoverNodes值为n2或者不配置,则当服务器m1挂掉后n1和tomcat中保存的session会丢失,而n2中未保存或者只保存了部分session, 这就造成 部分用户状态丢失。 如果配置tomcat的failoverNodes值为n1,则当m1挂掉后因为n2中保存了所有的session,所以重启tomcat的时候用户状态不会丢失。 为什么n2中保存了所有的session? 因为failoverNodes配置的值是n1,只有当n2节点不可用时才会把session存储到n1,所以这个时候n1中是没有保存任何session的。 lockingMode 可选值,默认none,只对non-sticky有效。 requestUriIgnorePattern 可选值,制定忽略那些请求的session操作,一般制定静态资源如css,js一类的。 sessionBackupAsync 可选值,默认true,是否异步的方式存储到memcached。 sessionBackupTimeout 可选项,默认100毫秒,异步存储session的超时时间。 如果memcached session manager的会话共享配置后,重启tomcat服务没有报错,但是访问页面的时候报错,页面访问失败,如下在logs/catalina.out日志里发现的错误:SEVERE [http-nio-8080-exec-1] org.apache.coyote.http11.AbstractHttp11Processor.process Error processing request java.lang.NoSuchFieldError: attributes 5、haproxy开启日志功能 修改haproxy配置文件 vi /etc/haproxy/haproxy.cfg 可以看到如下行,把这个开启 log 127.0.0.1 local2 没有指定端口,默认为udp 514 修改rsyslog配置文件 vi /etc/rsyslog.conf #启用在udp 514端口接收日志消息 $ModLoad imudp $UDPServerRun 514 #在rules(文本最末)节中添加如下信息 local2.* /var/log/haproxy.log #表示将发往facility local2的消息写入haproxy.log文件中,"local2.* "前面的local2表示facility,预定义的。*表示所有等级的 重启rsyslog服务 #重启 rsyslog systemctl restart rsyslog #重启haproxy systemctl restart haproxy 查看/var/log/haproxy.log文件应该能看到日志信息 查看日志 tail -f /var/log/haproxy.log syslog 通过 Facility 的概念来定义日志消息的来源,以便对日志进行分类,Facility 的种类有: 类别 解释 kern 内核消息 user 用户信息 mail 邮件系统消息 daemon 系统服务消息 auth 认证系统 authpriv 权限系统 syslog 日志系统自身消息 cron 计划安排 news 新闻信息 local0~7 由自定义程序使用 而另外一部分 priority 也称之为 serverity level,除了日志的来源以外,对统一源产生日志消息还需要进行优先级的划分,而优先级的类别有一下几种: 类别 解释 emergency 系统已经无法使用了 alert 必须立即处理的问题 critical 很严重了 error 错误 warning 警告信息 notice 系统正常,但是比较重要 informational 正常 debug debug的调试信息 panic 很严重但是已淘汰不常用 none 没有优先级,不记录任何日志消息 6、开启haproxy监控页面 在/etc/haproxy/haproxy.cfg中进行配置: listen admin_stats mode http stats enable bind *:8080 // 监听端口 stats refresh 30s stats uri /admin // 统计页面访问的url stats realm haproxy stats auth root:root // 认证用户与密码 stats hide-version 保存配置,重启haproxy服务