本章涉及到的知识点清单:
1、条件概率
2、贝叶斯定理
3、目标概率映射
4、目标概率映射的极大似然估计
5、朴素定义—条件独立性假设
6、分类逻辑
7、优化分类器
8、朴素贝叶斯分类器实战—英文评论留言分类
9、文档切词—构造词条列表
10、构造词汇表—定义特征值和特征向量
11、python编程实战实现朴素贝叶斯分类器
12、分类器结果展示和总结
一、条件概率
假设有下列两个事件A和B
事件A:早上乘坐地铁却没有赶上8点钟的地铁
事件B:上班迟到
如果我们需要统计:在所有上班迟到的人之中,有多少人是因为早上没有赶上8点钟的地铁?那么可以用来表示这个概率结果—条件概率
条件概率的定义:在事件B发生的条件下,量化事件A发生的概率
同理,即表示:在所有没有赶上8点钟地铁的人之中,有多少人上班迟到了?
由条件概率的定义,可以得到其计算方式为
其中,表示事件A和B共同发生的概率—联合概率
表示事件B单独发生的概率—边缘概率
二、贝叶斯定理
我们写出两个条件概率:和
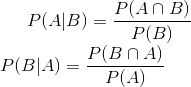
由于,则联立两个式子,得
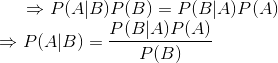
上式就是贝叶斯定理,它告诉我们如何交换条件概率中的条件与结果,即如果计算困难,那么可以先计算
三、目标概率映射
令X表示一个样本实例的特征向量,其是由一系列特征值构成的n维向量,即
其中x1,x2等代表特征值,则X是一个n维特征向量,代表一个样本实例的量化结果
令C表示所有样本的分类集合
一个样本属于一个类别,即一个特征向量Xi和一个具体的类别ck具有一组映射关系。而这组映射关系,可以用条件概率来这样描述
:表示任意一个n维特征向量X,属于类别ck的条件概率
而根据贝叶斯定理
通过观察,上式中Xi属于c1、c2或者ck的概率,分母都会存在Xi的边缘概率,即Xi属于任何类别的概率和其边缘概率无关,为此我们可以得到
即我们要计算条件概率,需要先从样本集合中学习到以下两个概率映射:
(1)条件概率:
(2)边缘概率:
四、目标概率映射的极大似然估计
接下来我们需要计算要学习的目标概率,可以用统计计数(极大似然估计)来计算这两个概率
假设有M个样本(M个特征向量),则边缘概率的极大似然估计为:
即M个样本中,各个样本类别c=ck发生的次数,除以样本总数
条件概率的极大似然估计为:

即M个样本中,各个样本X=Xi且类别c=ck共同发生的次数,除以各个样本类别c=ck发生的次数
五、朴素定义—条件独立性假设
计算完和这两个概率映射后,对于任意一个新样本的特征向量X,我们只需要将其带入映射计算,最后用贝叶斯定理计算出,不过这里会存在一个问题:
我们将的特征向量X展开为n个特征值表示
假设每一个特征值都是二值化(binary),则X共有种可能的取值
再假设类别集合C总共只有2个类别,那么总共就有种可能性的组合
即上述概率乘积面临“组合爆炸”的可能性非常大,为了降低参数可能的组合总数,就需要用到朴素贝叶斯假设
朴素贝叶斯假设:也称条件独立性假设,指当在c=ck这个条件(事件)的情况下,不同特征值之间的取值互相独立
即:

上述翻译为:在类别为ck的条件下,特征值x1取值的条件概率与其余特征值的取值无关
六、分类逻辑
应用朴素贝叶斯假设,我们将待分类的特征向量X带入概率映射计算,得
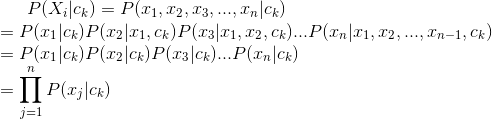
可以看到,当xj和ck都是binary的时候,通过应用朴素贝叶斯假设,组合参数的个数由减少到了
接下来用贝叶斯定理计算出待分类的特征向量X属于ck的条件概率,即
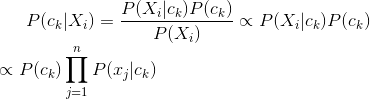
最后统计出X属于分类集合C=c1|c2...|ck中条件概率最大的类别,就是X的分类结果,即
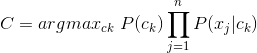
至此,我们就利用贝叶斯定理和朴素贝叶斯假设,完成了朴素贝叶斯分类器
七、优化分类器
上述分类器存在2点需要优化的地方:
(1)由于计算过程中存在连乘运算,则当某一个特征值xj的条件概率为0时,会使得整个连乘运算的结果为0
优化方法:将每个特征值xj的条件概率都初始化为1
(2)还是由于连乘运算可能会使得一些列小数的乘积结果下溢出
优化方法:可以利用对数的乘积运算转化为对数之和
分别对和取对数,即可防止计算结果下溢出
八、朴素贝叶斯分类器实战—英文评论留言分类
接下来我们分析一个实际的文本分类例子—在线社区的留言板
为了不影响社区的正面发展,从产品的角度,希望社区可以自动屏蔽带有侮辱类(负面)的留言,让社区只保留非侮辱类(正面)的留言
那么从技术的角度,利用监督式学习,我们希望从历史留言中选取部分样本来学习一个留言分类器,用来对新留言进行逻辑推理,判断新留言是否属于侮辱性类别的留言,这里我们采用朴素贝叶斯模型训练分类器
则对此问题建立两个类别:侮辱类和非侮辱类,分别使用1和0来表示,为此,我们列出该场景下使用朴素贝叶斯训练分类器的步骤:
(1)收集数据:获取留言和其分类结果
(2)量化数据:将留言解析量化为词条向量(特征值的定义)
(3)分析数据:检查词条向量确保量化的正确性
(4)训练分类器:计算特征向量中不同特征值的条件概率
(5)使用分类器:根据计算好的条件概率,通过朴素贝叶斯计算新留言属于每个类别的概率
(6)测试算法:交叉验证分类器
假设已经有了样本留言,则我们从量化数据开始一步步构造分类器
九、文档切词—构造词条列表
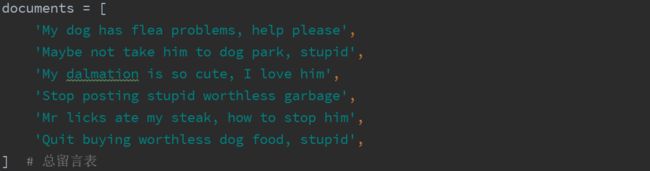
首先,我们对每个句子进行英文语法的切词,定义切词的规则如下:
(1)以标准英文单词的空格语法来切分句子(使用正则表达式过滤标点符号)
(2)统一所有单词为小写单词
(3)切分的单词长度均大于3
(4)切分单词没有出现在停词表中(排除冠词、量词、语气词等无用词)
PS:根据不同场景,切词的规则可以很复杂
用以上切词规则,我们将样本句子切分为下列词条列表

十、构造词汇表—定义特征值和特征向量
接下来我们整理词条列表中的每一个单词,排除重复出现的单词,构造出样本的词汇表
可以看到去重后有14个单词组成词汇表,而这14个单词可以反映描述到所有句子中
词汇表的意义为将句子翻译为特征值和特征向量(词条向量)
(1)特征值的定义:词汇表中的单词依次是否出现在当前句子中,出现为1,没有出现为0
(2)特征向量的定义:由所有特征值组成的词向量
根据上述定义,我们用词汇表作为翻译标准,将词条列表翻译为下列词向量

至此,我们用这个14维的词向量来描述一个句子的所有特征—单词的分布和出现情况,即完成了句子到向量的量化过程
PS:文本处理的特征值一般有两个模型
(1)词集模型:单词在句子中是否出现
(2)词袋模型:单词在句子中出现的总次数
案例里我们使用了词集模型来定义特征值,接下来只要使用词向量来训练分类器即可
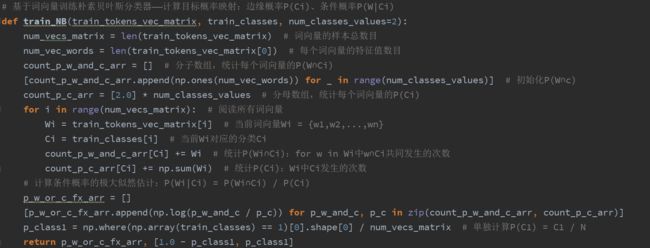
十一、python编程实战实现朴素贝叶斯分类器




十二、分类器结果展示和总结
最后用训练好的分类器来测试新留言句子的分类结果为
至此,我们可以总结出使用朴素贝叶斯作为分类器的几个特点
(1)朴素贝叶斯是一个通用的分类器,通过监督学习可以处理文本分类、公司上市质量、股票质量等多分类问题
(2)利用条件独立性假设,降低了对数据量组合的需求,虽然这个假设过于简单,甚至有时不正确,可是朴素贝叶斯仍然是一种有效的分类器
(3)对于文本分类问题的朴素贝叶斯分类器的优化空间主要有:
a:特征值的定义,如词袋模型的效果高于词集模型,停用词表的优化等
b:切词的规则
案例代码见:英文评论留言分类