一.了解淘宝Kafka架构
在ActiveMQ、RabbitMQ、RocketMQ、Kafka消息中间件之间,我们为什么要选择Kafka?下面详细介绍一下,2012年9月份我在支付宝做余额宝研发,2013年6月支付宝正式推出余额宝,2013年8月担任支付宝淘宝彩票项目经理带领兄弟们一起做研发,期间需要与淘宝和500万对接竞彩接口数据,业余时间与淘宝的同事沟通,了解天猫在电商节如何处理这些大数据的?技术架构上采用了哪些策略呢?
一、应用无状态(淘宝session框架)
二、有效使用缓存(Tair)
三、应用拆分(HSF)
四、数据库拆分(TDDL)
五、异步通信(Notify)
六、非结构化数据存储 ( TFS,NOSQL)
七、监控、预警系统
八、配置统一管理
天猫的同事把大致的架构跟我描述了一番,心有感悟。咱们来看一下2018年双11当天的成交额。

二.kafka实现天猫亿万级数据统计架构

Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力
Data Access:数据通道
Computing:计算
Persistence:执行保存方式
spout:表示一个流的源头,产生tuple
bolt:处理输入流并产生多个输出流,可以做简单的数据转换计算,复杂的流处理一般需要经过多个bolt进行处理
为什么不能用分布式文件HDFS集群?
1、实时性:hdfs的实时性没有kafka高。
2、消费量的记录:hdfs不会记录你这个块文件消费到了哪里,而基于zookeeper的kafka会记录你消费的点。
3、并发消费:hdfs不支持并发消费,而kafka支持并发消费,即多个consumer.
4、弹性且有序:当数据量会很大,而且处理完之后就可以删除时,频繁的读写会对hdfs中NameNode造成很大的压力。而kafka的消费点是记录在zookeeper的,并且kafka的每条数据都是有“坐标”的,所以消费的时候只要这个“坐标”向后移动就行了,而且删除的时候只要把这个“坐标”之前的数据删掉即可。
三.什么是Kafka?
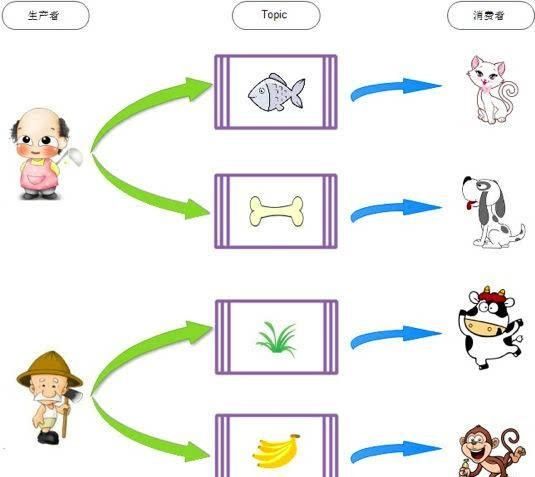
通过上图就可以了解到,生产者Producers(农民和厨师),消费主题top(鱼,骨头,草,香蕉),消费者Comsumer(猫,狗,老牛,猴子),生产者根据消费主题获取自己想要的食物
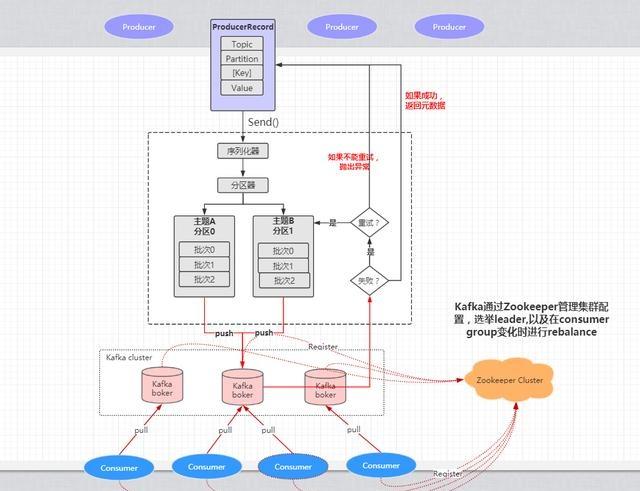
四.Kafka架构原理
五.Kafka能帮我们解决什么问题?
请高手指明一下kafka解决了什么问题,什么场景下使用?消息订阅和发布吗,好像redis也支持,功能是否有重叠?
一.消息队列
假设你意气风发,要开发新一代的互联网应用,以期在互联网事业中一展宏图。借助云计算,很容易开发出如下原型系统:
Web应用:部署在云服务器上,为个人电脑或者移动用户提供的访问体验。
SQL数据库:为Web应用提供数据持久化以及数据查询。
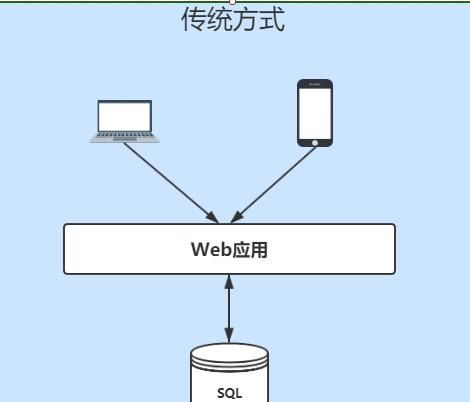
这套架构简洁而高效,很快能够部署到百度云等云计算平台,以便快速推向市场。互联网不就是讲究小步快跑嘛!
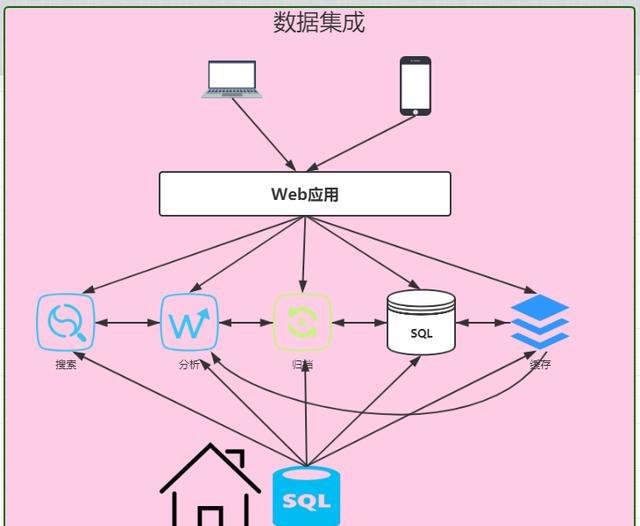
好景不长。随着用户的迅速增长,所有的访问都直接通过SQL数据库使得它不堪重负,不得不加上缓存服务以降低SQL数据库的荷载;为了理解用户行为,开始收集日志并保存到Hadoop上离线处理,同时把日志放在全文检索系统中以便快速定位问题;由于需要给投资方看业务状况,也需要把数据汇总到数据仓库中以便提供交互式报表。此时的系统的架构已经盘根错节了,考虑将来还会加入实时模块以及外部数据交互,真是痛并快乐着……
这时候,应该跑慢一些,让灵魂跟上来。
本质上,这是一个数据集成问题。没有任何一个系统能够解决所有的事情,所以业务数据根据不同用途存而放在不同的系统,比如归档、分析、搜索、缓存等。数据冗余本身没有任何问题,但是不同系统之间像意大利面条一样复杂的数据同步却是挑战。
这时候就轮到Kafka出场了。
Kafka可以让合适的数据以合适的形式出现在合适的地方。Kafka的做法是提供消息队列,让生产者单往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。之前连接的复杂度是O(N^2),而现在降低到O(N),扩展起来方便多了:
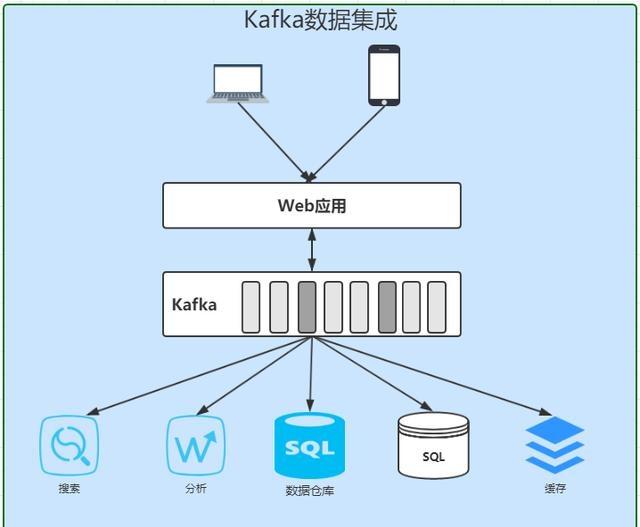
在Kafka的帮助下,你的互联网应用终于能够支撑飞速增长的业务,成为下一个BAT指日可待。
以上故事说明了Kafka主要用途是数据集成,或者说是流数据集成,以Pub/Sub形式的消息总线形式提供。但是,Kafka不仅仅是一套传统的消息总线,本质上Kafka是分布式的流数据平台,因为以下特性而著名:
提供Pub/Sub方式的海量消息处理。
以高容错的方式存储海量数据流。
保证数据流的顺序。
二.日志采集
随着互联网的不断发展,用户所产生的行为数据被越来越多的网站重视,如何对于用户信息进行采集则越来越受到重视,下面就为大家介绍基于Kafka的服务端用户行为日志采集方式。
1. 技术选型
服务端日志采集主要通过在Controller的接口中进行埋点,然后通过AOP技术、Kafka消息系统以及logback对用户行为进行采集。
之所以使用AOP技术是因为AOP的以下重要特定:
代码的侵入性小。对于业务代码的侵入性小,只需要在Controller的接口上添加注解,然后在其他模块对用户行为进行采集。
重用性。对于相同作用的代码可以进行重用。
扩展性。能够很好的对系统进行扩展。
由于使用异步方式对用户行为信息进行收集,因此需要使用消息中间件。目前消息中间件非常多,比较流行的有ActiveMQ、ZeroMQ、RabbitMQ、Kafka等。每个消息中间件都有各种的优势劣势,之所以使用Kafka消息中间件,是因为以下几点因素:
高性能。每秒钟可以处理数以千计生产者生成的消息。
高扩展性。可以通过简单的增加服务器横向扩展Kafka集群的容量。
分布式。消息来自数以千计的服务,使用分布式来解决单机处理海量数据的瓶颈。
持久性。Kafka中的消息可以持久化到硬盘上,这样可以防止数据的丢失。
因为用户的行为数据最终是以日志的形式持久化的,因此使用logback对日志持久化到日志服务器中。
2.总体架构
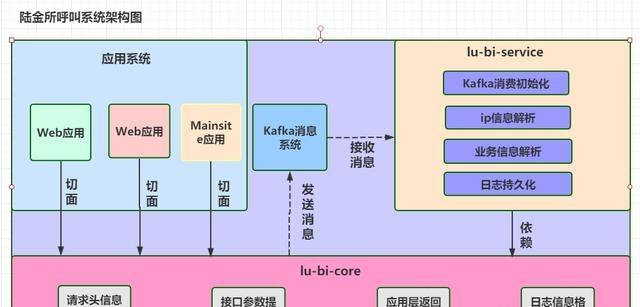
图1 总体架构图
服务端日志采集系统主要由两个工程组成:陆金所-bi-core和lu-bi-service。由于中国平安陆金所使用dubbo框架,因此有服务提供方和服务消费方。lu-bi-core被web、wap和mainsite服务消费方依赖。此外,lu-bi-service也依赖于lu-bi-core,主要是依赖于其中的一些实体类及工具类。
lu-bi-core工程为Kafka消息的生产者,主要封装实现切面的具体逻辑,其主要职责如下:
解析用户请求的Request信息:从Request中提取用户的基本信息,如设备型号、用户的供应商、ip、设备的分辨率、设备平台、设备的操作系统、设备id、app渠道等。
接口对应的参数:通过切面可以提取接口的参数值,从而知道用户的业务信息。
应用层返回的结果信息:因为切面使用AfterReturning方式,因此可以获取用层的返回结果,从返回结果中可以提取有用的信息。
用户的基本信息:用户的id信息。
信息格式化:将信息转化成JSON字符串。
发送消息:将最终需要发送的消息放入本地阻塞队列中,通过另一个线程异步从阻塞队列中获取消息并发送到Kafka Broker中。
lu-bi-service工程为Kafka消息的消费者,其主要职责如下:
实时从Kafka中拉取最新的数据。
将JSON字符串转化成,方便进一步对用信息进行加工。
对用户的ip进行解析,获取ip对应的地区以及经纬度信息。
将加工好的最终信息持久化到log文件中。
3.部署图

图2 部署图
上图为陆金所与日志系统系统相关的部署图,App、Wap和Mainsite服务器集群分别对应不同终端的应用。Kafka集群使用杭研的集群,目前有10个Broker。日志服务器有两台,通过Kafka的均衡策略对日志进行消费。
4.日志采集的流程
日志采集流程图如下所示:
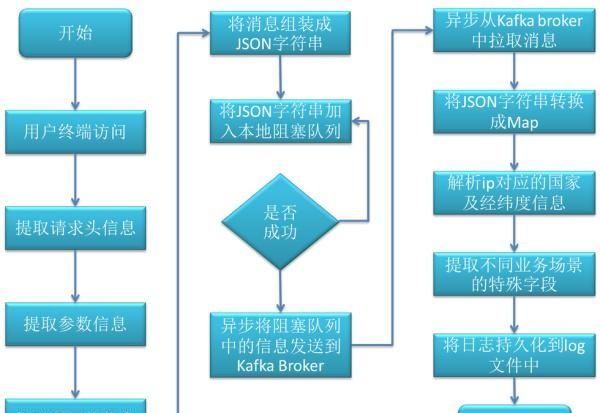
图3 日志打点流程图
上图为消息生产者和消息消费者共同组成的流程图。
消息生产者的具体步骤如下:
通过切面拦截用户的请求。
从切面中提取请求头的基本信息,如设备信息,cookie信息,ip信息等。
提取请求的接口参数信息。
从接口返回值中提取相关信息,如id,pvid等。
将提取的信息封装成JSON字符串,放到阻塞队列中,假如阻塞队列溢出会有三次重试机制。
异步线程从本地阻塞队列中获取数据,并将信息组装发送到Kafka的Broker中,此时消息生产者结束。
消息消费者的具体步骤如下:
实时从Kafka Broker中批量拉取消息。
将拉取的消息转化成对象。
解析ip对应的国家、省份、城市、经纬度信息。
对不同业务场景的信息进一步解析。
将日志信息转化成JSON字符串,持久化到log文件中。
5. 相关配置
application-XXX.properties:该配置放Kafka的相关属性,包括topic、groupId、server等信息。
lu-log-msg.xml:该配置放在app-web,mainsite-web,wap-web的src/main/resources目录下,主要是初始化kafka生产者的信息。
lu-bi-service.xml:该配置放在lu-bi-service工程的src/main/resources目录下,主要用于加载kafka消费者的配置信息,并且启动kafka消费者服务。
logback.xml:该配置放在lu-bi-service工程的src/main/resources目录下,主要用于声明日志文件存放的目录,需要持久化的日志的package路径,以及日志持久化的格式。
ip_conf.txt:该配置放在lu-bi-service工程的src/main/resources目录下,用于解析ip对应的地域、经纬度等信息。
六.关于面试问题
1.Redis和Kafka区别?
作者跟大家举个例子:
老板有个好消息要告诉大家,公司要发放年终奖,有两个办法:
1.到会议室每个座位上挨个儿告诉每个人。什么?张三去上厕所了?那张三就只能错过好消息了!
2.老板把消息写到会议上的黑板报上,谁想知道就来看一下,什么?张三请假了?没关系,我一周之后才擦掉,总会看见的!什么张三请假两周?那就算了,我反正只保留一周,不然其他好消息没地方写了
redis用第一种办法,kafka用第二种办法,知道什么区别了吧
Redis PUB/SUB使用场景:
1. 消息持久性需求不高
2. 吞吐量要求不高
3. 可以忍受数据丢失
4. 数据量不大
Kafka使用场景:
上面以外的其他场景:)
1. 高可靠性
2. 高吞吐量
3. 持久性高
Kafka、RabbitMQ、RocketMQ等消息中间件的对比
有关测试结论
Kafka的吞吐量高达17.3w/s,不愧是高吞吐量消息中间件的行业老大。这主要取决于它的队列模式保证了写磁盘的过程是线性IO。此时broker磁盘IO已达瓶颈。
RocketMQ也表现不俗,吞吐量在11.6w/s,磁盘IO %util已接近100%。RocketMQ的消息写入内存后即返回ack,由单独的线程专门做刷盘的操作,所有的消息均是顺序写文件。
RabbitMQ的吞吐量5.95w/s,CPU资源消耗较高。它支持AMQP协议,实现非常重量级,为了保证消息的可靠性在吞吐量上做了取舍。我们还做了RabbitMQ在消息持久化场景下的性能测试,吞吐量在2.6w/s左右。
在服务端处理同步发送的性能上,Kafka>RocketMQ>RabbitMQ
写在最后
如今都在谈论寒冬有多可怕,笔者作为一个过来人,却有不同的看法:寒冬不可怕,在寒冬里没有生存能力,才是最可怕的。
因此小编总结了这几年在阿里的工作经验并结合目前互联网最主流的Java架构技术,最后录制了七大Java架构技术专题视频(源码阅读、分布式架构、微服务、性能优化、阿里项目实战、Devops、并发编程)分享在我的裙669275137中,并且每晚我都会在群内直播讲解这些架构技术的底层实现原理,感兴趣的程序员们可以加群找管理员获取。