1. 美团
1.1 笔试 3.19
5道编程题,两个小时
第一道:打银花,简单,两组数分别排序后输出最大的三个数;
第二道:找出最长上升子序列,可以删除一个数,求删除的最长序列:
利用双指针i, j,令k记录当前可以删除数目,当k为0时,记录当前数组长度,之后i指针向前移动找到离他最近的不符合上升序列的数,j跳过该数,继续遍历:
i, j = 0, 0
k = 0
while i<=j and j0:
k -= 1
j += 1
else:
maxlen = max(maxlen, j-i)
while i<=j and vec[i] 第三题:dp问题,但是没有完整思路
一共有n个任务待完成,每个任务有k个子任务,第i个子任务需要花ti时间;
每个任务不能重复完成
完成一个子任务得p分,k个子任务都完成得pk+q分
现在共有m的时间,求最大得分
dp, 对时间排序,看成nxk的二维矩阵,最后的结果肯定是完成i行,完成j列,加上j+1列的一部分
第四题:跑步:图+最短路径
晨晨爱跑步,这天他准备跑k米, 城市可以看成n个点,m条无向边,每条边长度固定。
要求去往一个目的地一定要走最短路,求正好跑k米能走到的目的地的个数,目的地可是是点和边。
总结:开始太慌,没有很好分析题,最短路径直接就用了广度遍历,但对于有权边,应该用dirichlet方法。
第五题:求序列最长不下降子序列,序列有0,1组成,可以对序列进行更改
这道题纯属代码习惯和粗心大意,面壁······
def query(s:str, n: int):
dp = [[0, 0] for i in range(n+1)]
for i in range(n):
if s[i]=='0':
dp[i+1][0]=dp[i][0]+1
dp[i+1][1]=max(dp[i][1], dp[i][0])
else:
dp[i+1][1]=max(dp[i][0], dp[i][1]) + 1
dp[i+1][0] = dp[i][0]
return max(dp[n][0], dp[n][1])
def change(s:str, l:int, r:int):
tmp = ""
for i in range(l-1, r):
if s[i]=='0':
tmp += '1'
else:
tmp += '0'
s = s[:l] + tmp + s[r:]
return s
nm = [int(x) for x in input().split()]
n, m = nm[0], nm[1]
strs = input()
for i in range(m):
memo = [i for i in input().split()]
if memo[0]=='q':
print(query(strs, n))
elif memo[0]=='c':
l = int(memo[1])
r = int(memo[2])
strs = change(strs, l, r)
数据结构
https://www.cnblogs.com/mr-wuxiansheng/p/8688946.html
快手
笔试 3.22
求一定的K个数最大乘积:给两个整数k, n 求将n分成k份后的最大乘积
class Solution:
def __init__(self,maxx,K,N):
self.maxx=maxx
self.N=N
self.K=K
def back(self,ans,loc,right):
if loc==self.K-1 or right==1:
self.maxx=max(self.maxx,ans*right)
return
for i in range(1,right):
self.back(ans*i,loc+1,right-i)
p=list(map(int,input().split()))
K=p[0]
N=p[1]
maxx=0
ans=1
loc=0
right=N
s=Solution(maxx,K,N)
s.back(ans,loc,right)
print(s.maxx)
- [[1,2,3],[4,5,6],[7,8,9]]
最短路径:求二维矩阵从左上角到左下角的最小路径
class Solution:
def find_best_path_cost(self , A ):
# write code here
if not A:
return 0
row=len(A)
col=len(A[0])
dp=[[0 for j in range(col+1)] for i in range(row+1)]
for i in range(1,row+1):
dp[i][1]=dp[i-1][1]+A[i-1][0]
for j in range(1,col+1):
dp[1][j]=dp[1][j-1]+A[0][j-1]
for i in range(2,row+1):
for j in range(2,col+1):
dp[i][j]=min(dp[i-1][j],dp[i][j-1])+A[i-1][j-1]
return dp[row][col]
if __name__ == '__main__':
s=Solution()
A=[[1,2,3],[4,5,6],[7,8,9]]
print(s.find_best_path_cost(A))
- 给定S, A, B, P, 初始arr[0] = S, 接下来arr[i+1] = (arr[i] * A + B) % P, 并且arr数组里的每个数字最多出现两次,当某个数字出现3次时,终止序列生成。给定两组S, A, B, P分别生成两个序列,求两个序列的最长公共子序列
3.1 最开始想到的就是LCS算法,本来觉得应该有规律但是找不到···写完之后果然超时:
def longest(s1, s2):
m, n = len(s1), len(s2)
if m==0 or n==0:
return 0
dp = [[0] * (1+n) for _ in range(m+1)]
for i in range(m):
for j in range(n):
if s1[i]==s2[j]:
dp[i+1][j+1]=dp[i][j]+1
else:
dp[i+1][j+1]=max(dp[i][j+1], dp[i+1][j])
return dp[m][n]
def generate(line):
l = [int(x) for x in line.split()]
S, A, B, P = l[0], l[1], l[2], l[3]
res = [S]
while 1:
x = (res[-1]*A+B)%P
if x not in res:
res.append(x)
else:
j = 0
while res[j]!=x:
j+=1
n=len(res)
while j3.2 参考https://www.nowcoder.com/discuss/388827?toCommentIpt=1
- 三维坐标系下半径为1的求,然后与椭球:(x-a)2/d2 + (y-b)2/e2 + (z-c)2/f2 = 1相较,求相较后椭球内部和在椭球外部的表面积分别是多少
完全没思路...
牛客上大佬解法:随机数生成
from math import pi
from random import random
from random import uniform
num = [float(x) for x in input().split()]
a, b, c, d, e, f = num[0], num[1], num[2], num[3], num[4], num[5]
ball_area = 4 * pi
part_area = [0] * 2
#假设共有n个数
n = 10000
for i in range(n):
x= random() * (-1 if random()<0.5 else 1)
y = uniform(0, 1 - x**2) * (-1 if random()<0.5 else 1)
z = (1 - x**2 - y**2) * (-1 if random()<0.5 else 1)
def is_ball(x, y, z):
X = (x-a)/d
Y = (y-b)/e
Z = (z-c)/f
return X**2 + Y**2 + Z**2<1
if is_ball(x, y, z):
part_area[0] += 1
else:
part_area[1] += 1
A1 = (part_area[0]/n) * ball_area
A2= (part_area[1]/n) * ball_area
print(A1, A2)
微软3.26 zz
- 击鼓传花
嗯…突发奇想给这题起了个名
N个人每个人编号1-N,编号能整除的两个人互相连通,从编号为i的人开始传,最后要传回i手上,要在T次之内传完,问最多有几种传法?
回溯算法
- 最少射击几次
N个瓶子都有编号,每次能射击1个或多个瓶子,如果是回文的就能一次性击倒。最少几次能全击倒?
测试
输入:[1, 2]
输出:2
输入:[1,3,4,1,5]
输出:3
说明:第一次先射3,变成[1,3,1,5],因为有[1,3,1]回文可以一次击倒,剩下[5]再一次
#include
#include
#include
using namespace std;
int main() {
int N = 6;
vector > scores(N, vector(N));
int bottles[6]={ 1, 2, 3, 4, 5, 6 };
for (int i = 0; i < N; i++) {
scores[i][i] = 1;
}
for (int i = 1; i < N; i++) {
for (int j = 0; j < N - i; j++) {
int min_score = INT_MAX;
if (bottles[j] == bottles[j + i]) {
min_score = i > 1 ? scores[j + 1][j + i - 1] : 1;
}
for (int k = 0; k < i; k++) {
int temp = scores[j][j + k] + scores[j + k + 1][j + i];
if (temp < min_score) {
min_score = temp;
}
}
scores[j][j + i] = min_score;
}
}
cout << scores[0][N - 1];
return 0;
}
排队
N个人排队编号1-N,可能3种情况:
E1: 排在队首的人离开
E2: 队伍中编号为K的人离开
E3: 返回编号为X的人在队伍中的位置
输入一组query,返回所有E3累加的结果
测试
N=5 query=3
[1,0] [2,3] [3,2]
输出:1
说明:第一次队首编号1的人走了,第二次编号为3的人走了,第三次编号2的人排在队伍中的第一个蜜蜂采蜜
蜜蜂从家里出发,有几朵花和几处仓库(有坐标),每朵花有一份蜂蜜,蜜蜂一次只能带一份蜂蜜,可以先把采好的蜂蜜送到仓库,最后要回到家里。蜜蜂飞一单位的距离就会消耗一单位的时间(欧式距离),在限定时间T内,蜜蜂最多能采多少蜂蜜?
腾讯
3.30 一面 1h左右
- 问题:sickit-learn求你了别说错了
-
主要围绕lstm自动生成全唐诗,可不可以做到n对n,1对n的生成
具体的生成策略
相关参数:两层lstm, embedding, linner: embedding_size=128, hidden_size= 256, max_len=125
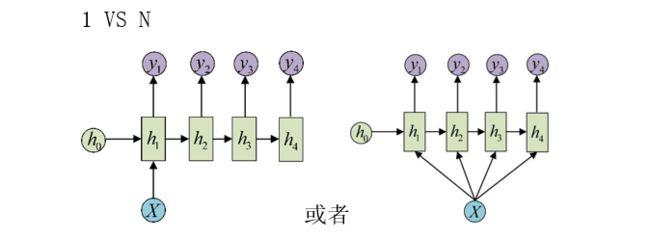
lstm 1vs n 与 n vs n
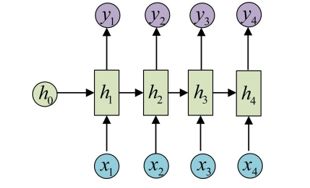 n vs n
n vs n
- 围绕研究生期间的具体工作,边缘计算,论文是否自己写成
- 介绍tf-idf, word2vec,区别,(答得不太好,应该说tf-idf忽略了上下文语义以及相似度),word2vec用了哪种工具包,在哪些数据集上进行了实验
https://blog.csdn.net/stupid_3/article/details/83184807
tf-idf:
term-frequency表示单词在文本中出现的频率
inverse-document-frequency表示出现这个单词的文档在总文档中的个数的倒数
工具包:
class sklearn.feature_extraction.text.TfidfTransformer(norm=’l2’, use_idf=True, smooth_idf=True, sublinear_tf=False)
norm:词向量归一化
Word2vec: word embedding: cbow skip-gram
skip-gram在大数据集上表现良好,采用负采样训练时可以看成softmax做二分类模型
tf-idf word2vec区别:
word2vec不会出现维度爆炸,是单词的稠密表示,训练过程考虑了上下文环境,更好的表达单词语义。 - 详细地问了kaggle分类竞赛,SVM的数据特征,7折bert?(面试官表示疑惑?这个说法不对吗?)
用bert与transformer+SVM对比表示疑惑,我说内存不够,表示fine
问到可以如何继续提高效果 - 开放问题:在比如地图这样的场景,输入前几个词预测接下来的词,如何做?
以及在线生成的情况?(我不知道,面试官表示你们没有机会见到这种情况可以理解,人超级随和)
对hadoop, spark这些有没有了解
是不是了解linux
(感觉后面都是结合岗位需要) - 三道算法题,大概用时30min
1)给定一个字符串如abcABF, 去掉重复词,忽略大小写,输出去除重复词后的字符串abcF,返回字符串长度;
2)求最长公共子序列:太常见了所以问我会不会,之后只说了思路;
3)给定一个排序二叉树,返回第k大节点:我感觉最麻烦的在于自己建树,以及输入样例的过程,利用排序二叉树的中序遍历生成;
4.02 腾讯二面 30min
面试小哥没开摄像头,但是态度很好,主要是问项目,问的很细
考虑三个项目重新捋一遍
包括细节、模型搭建、参数设置和调参过程,(原论文)
没做好准备,太惨了
手撕代码:C++手写python split函数
京东
3.31 京锐夏令营 推荐算法 30min
我也不知道当时怎么投了这个,是想把Nlp结合推荐来做,答得很乱
开放性问题:比如给定部分物品和相关文案,如何生成一个新物品的文案
进一步可以得到用户评论,应该怎么做
小姐姐提示说,可以对用户评论提取关键字,取频率最高的k种,对这些进行分类,选取优质评论从而生成新文案。
但是让我过了,小姐姐真是个好人。
明天继续转锦鲤
京锐夏令营 二面 35min
主要问的是项目和相关的基础问题
- 自我介绍
- 唐诗生成项目:lstm的结构,相比rnn有什么优势,为什么?
了解batch norm/layer norm这些吗?具体怎么实现的 - 文本序列标注:bert起什么作用?有多少层?crf如何解码?具体说一下维特比算法?损失函数怎么设计的?
- 表述有点模糊,其实就是问各种优化算法sgd、adam这些
- 为什么会出现梯度消失和梯度爆炸?(主要从激活函数这方面说的)怎么解决呢?(激活函数的变种balabala)还有吗?
- 过拟合怎么解决?
- 最后口述0-1背包问题的解决方法
crf那里有点模糊,然后一直在深究,感觉不太好。(真的很玄学,我前一天和早上刚看的各种归一化方法···)而且真的要练一练自己的表述能力···
字节
一面 1h 04.01
- 自我介绍
- 直接手撕代码
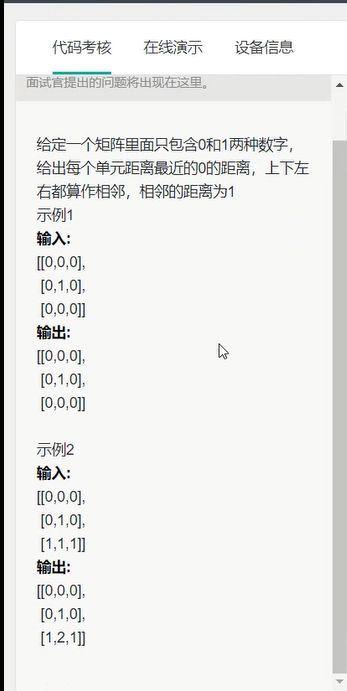
开始有点没思路,直接深度遍历找最小距离,之后面试官提示说可能会出现死循环,于是增加了一个二维矩阵记录已遍历节点,写完说可以;然后问时间复杂度,能不能优化;回答O((mn)^2)的复杂度,优化的方法想到可以遍历靠近0的节点,随后一步步包围,这种优化方法好像还挺满意的,问时间复杂度呢?脑子瘸说O(mnlogn), 其实应该是O(mn)
总共用时20min - 问了第一个项目,为什么要用bert+svm?还可以怎么做分类?
如果没有内存限制,怎么做会更好?
基于bert,提供抖音的评论,如何进行分类?
强调如果不限制资源可以怎么做?其实是想说可以从bert预训练开始,谷歌提供的预训练模型是基于自己的数据集,和评论不完全相符,因此可以自己从预训练开始训练模型。
就这一点问了bert的原理,为什么具有优势?(mlm and nsp, 因此下游可以从mlm开始预训练)
如果下游重点是要处理低俗的单词,可以怎么做?
(回答mask可以不再随机mask,而且有选择的重点选择低俗词语。)
还有吗?
(我开始瞎答了,用图像加入预训练balabala),提示可以增加其他预训练任务,可以利用举报、相关视频如美女视频等信息,在bert预训练两个任务的基础上,加上这一个分类任务,如视频的tag分成“美女”“性感”等分类,从而扩充低俗词汇。
(自我介绍说了一个文本预处理)你了解哪些文本预处理?
文本增强场景,(欠拟合?)可以去分析文本看是不是有错拼、这种情况下文本纠正和顺序置换是有效果的。
二面 1h
- 自我介绍
- 还是第一个项目,对方法犹疑, 叹息
- 介绍下transformer结构,这里可以说的更详细
- 展开说下word2vec(层次softmax, 怎么应用到fasttext, 在面对K类数目差不多的类别时会有什么效果?)
- 评估方法都有哪些,auc和其他的有什么区别(排序)
- 开放性问题:提供抖音评论,相比正常文本更短,应该怎么处理?
语句部分用户会用正常词替换违禁词或者低俗词汇,怎么做?
其他的,没录音,忘了···· - 手撕代码
写出二叉树非递归中序遍历,gg
换成装雨问题,开始用两个数组,之后要求o(1)空间复杂度,口述思路。
三面 04.03 40min
无自我介绍
- 手撕代码:给定两个由大到小的排序数组,输出最大的K个数,要求尽量严谨;
升级:m个由大到小的数组,输出最大的K个数;
开始自作聪明合并头尾,实际上和依次合并的时间复杂度是一样的 o(mk)
升级:减小时间复杂度
其实这个时候前面的时间复杂度没回答上来就down了,然后也没思路,面试官提示了很久,最后说是用最大堆,时间复杂度o(klogm)
总结:字节很爱问时间复杂度这种,而且心态绝对不能论 ············(冷知识,m个数据建堆的复杂度是o(m) - 基础知识
bert(应该好好把整个优势捋一遍,可惜心态有点炸了)
优化方法
如果样本不均衡,可以怎么做:
1)从采样角度,欠采样和过采样
如果数据集比较大,可以使用欠采样,减少丰富类的数目;
如果数据量比较小,可以过采样,通过使用重复、自举或合成少数类过采样等方法(SMOTE)来生成新的稀有样品。
过采样改进方法1
通过抽样方法在少数类样本中加入白噪声(比如高斯噪声)变成新样本一定程度上可以缓解这个问题。如年龄,原年龄=新年龄+random(0,1)
过采样代表算法:SMOTE 算法
SMOTE[Chawla et a., 2002]是通过对少数样本进行插值来获取新样本的。比如对于每个少数类样本a,从 a最邻近的样本中选取 样本b,然后在对 ab 中随机选择一点作为新样本。
2)K-折交叉验证,过采样之前采用
3)阈值移动
在样本分类决策过程中,改变决策阈值为两类样本的比例,
4)评估指标,auc,交叉熵
5)模型选择,选择树模型或者集成学习方法,xgboost,随机森林
hr面 25min 4.07
4.06 接到电话通知hr面,嗯,接到电话的时候可以上天了
hr应该是之前一直跟我沟通的小姐姐
没有自我介绍,对方应该是知道了大概情况,问对整体面试的评价;对哪个面试官印象最深;
实验室的方向,研究生期间做的事情
个人职业规划,对第一份工作有什么要求,看重哪些地方,希望在哪里工作,导师的评价
个人优缺点,遇到的一件困难的事情,能给公司带来什么,优缺点那里追问了一下
对字节有哪些了解,有用过哪些app
反问:实习转正要求,这个职位具体要做的工作,以及转正后能否调整工作地点(不能orz)
阿里淘系
4.8 笔试
- 勇士n秒内获得增幅,每秒一点伤害,伤害范围为b,木头人血量为a, 数量为m,求最多可以打倒的木头人数量;
- 给定一个矩阵,求从左上角出发累计的路径最大值,要求每一步需要比前一步的数值大,可以跨越的距离为k: ac35%
招行信用卡中心
4.8笔试
- 判断是不是镜像字符串;
- 给定一个数字字符串和k, 可以添加+,-,找到和为k的组合数:ac50%
def calcu(vec, k):
total = sum(vec)
if (total-k)%2!=0:
return 0
else:
limit = (total-k)//2
memo = [0]*(limit+1)
memo[0]=1
for i in range(1, len(vec)):
j=limit
while j>=vec[i]:
if memo[j-vec[i]]>0:
memo[j]+= memo[j-vec[i]]
j -= 1
return memo[limit]
def permu(s, vec, res):
if len(s)==0:
res.append(vec)
for i in range(len(s)):
permu(s[i+1:], vec+[int(s[:i+1])], res)
return
t = int(input())
while t>0:
t -= 1
s, k = input().split()
if s