基础知识
工欲善其事,必先利其器,要编写爬虫程序,首先必须找一个爬虫框架,如果你使用Python语言,可以选用scrapy,如果你使用Java语言,可选用WebMagic,本文使用后者,编写爬虫程序无非分以下几步:
- 根据URL下载网页,得到HTML(注意并不是通过开发工具看到的HTML,而是网页源代码HTML,这两者有本质区别);
- 根据HTML解析您所需要的数据,可以利用xpath获取DOM节点内容或属性值;
- 有可能还需要根据得到的HTML解析出其他链接,利用多线程继续爬取;
- 解析后的数据存储(数据库,文件等);
WebMagic爬虫框架在core代码中主要有四个模块:Downloader、PageProcessor、Scheduler、Pipeline,分别处理下载,页面解析,管理(管理待抓取的URL,做一些去重工作,默认使用内存队列管理URL,也可以使用Redis进行分布式管理)和持久化工作,因为最终解析出的结构化数据应该是要入库或入文件存储的。
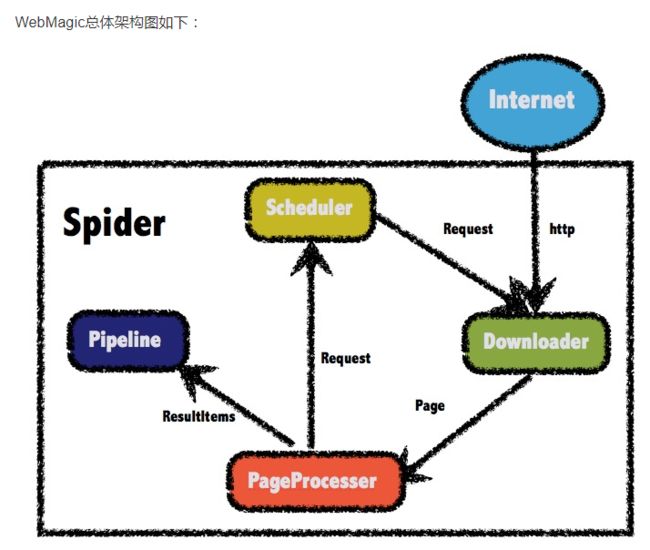
页面下载
WebMagic爬虫框架负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具,当然你可以使用chromedriver下载动态内容,那么我们应该调用Spider的setDownloader方法spider.setDownloader(new SeleniumDownloader())。
页面解析
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
这是您需要花大力气编写代码的地方,根据chrome开发工具查看您所需抓取的数据的xpath路径,利用xpath获取节点信息获取数据。
Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案,如果你需要将数据存储到数据库,您可能需要自定义一个Pipeline,以JSON形式保存到文件D:\webmagic\可以使用:
Spider.create(new XXXPageProcessor())
.addUrl("http://www.baidu.com")
.addPipeline(new JsonFilePipeline("D:\\webmagic\\"))
.thread(5)
.run();
另外,Request对象用于在PageProcessor的process实现函数中,将其他url的抓取任务扔给Downloader组件去执行,Downloader组件下载到一个页面是Page对象,在此可以获取网页源码内容,可以做xpath解析等,ResultItems相当于一个Map,保存PageProcessor处理的结果,供Pipeline使用,你可以将里面的内容保存到注入数据库中。
Selectable抽取元素
解析处理HTML获取自己想要的数据可能是编写爬虫最麻烦的一环,使用Selectable接口,你可以直接完成页面元素的链式抽取,也无需去关心抽取的细节,比如上文提到的Page.getHtml()得到的就是一个Html对象,实现了Selectable接口。以下是常用的解析方法:
- xpath(String xpath):根据xpath路径获取节点,如html.xpath("//div[@class='title']/text()",获取包含title类的div包裹的内容;
- ("div.title"),获取包含title类名的div节点列表
- css(String selector):功能同$,使用css选择器;
- links():获取所有链接
- regex(String regex):根据正则匹配出内容
- replace(String regex,String replacement):替换内容
以上函数都返回Selectable接口,支持链式调用,但想要获取解析后数据的结果时,可以利用get()返回一条String结果或all返回所有结果List或match返回匹配结果。
常见问题
在编写爬虫程序时,我们经常会碰到的一些问题汇总与解决方案,帮您快速定位解决问题。
通过代理上网解决IP被封问题
有时候抓取的站点会封我们的IP,公司的外网IP又是固定的,我们可以通过ADSL拨号的方式接入另一个网络,在ADSL网络的服务器上搭建代理服务器,爬虫程序所在的服务器通过代理该台服务器上网,这样再也不怕对方站点封您的IP了,让爬虫程序通过代理爬取网页,代码如下:
HttpClientDownloader downloader= new HttpClientDownloader();
downloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("IP",PORT,"username","password")));
spider.setDownloader(httpClientDownloader)
服务器端返回403错误
有些网站会有一些爬虫的识别机制,影响您利用爬虫去爬数据时,会碰到服务端的403拒绝访问错误,这时,我们应该根据实际访问网址的情况,构造userAgent,Cookie等数据,以便达到可访问网站的目的,典型的应用场景是爬取Discuz!论坛的列表数据,已爬取宁波当地的房产论坛列表为例,利用WebMagic编写的爬虫代码如下:
package test.springboot2.webmagic;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class TestBBS {
public static void main(String[] args) {
Spider.create(new PageProcessor() {
private Site site = Site.me().setCharset("GBK").setRetryTimes(3)
.addCookie("7nPA_2132_atarget", "1")
.addCookie("7nPA_2132_forum_lastvisit", "D_57_1544683126")
.addCookie("7nPA_2132_lastact", "1544683156%09forum.php%09ajax")
.addCookie("7nPA_2132_lastvisit", "1544679421")
.addCookie("7nPA_2132_saltkey", "Y41kZTOe")
.addCookie("7nPA_2132_sendmail", "1")
.addCookie("7nPA_2132_sid", "HpKlUl")
.addCookie("7nPA_2132_st_t", "0%7C1544683126%7Ca40d86281e77b87595a73a73f8a8d6ab")
.addCookie("7nPA_2132_visitedfid", "57")
.addHeader("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8")
.addHeader("Accept-Encoding","gzip, deflate, br")
.addHeader("Accept-Language","zh-CN,zh;q=0.9")
.addHeader("Cache-Control","max-age=0")
.addHeader("Connection","keep-alive")
.addHeader("Cookie","7nPA_2132_saltkey=Y41kZTOe; 7nPA_2132_lastvisit=1544679421; 7nPA_2132_st_t=0%7C1544683021%7C8f3386d0af3b92c0e84bee8dce32f193; 7nPA_2132_atarget=1; 7nPA_2132_forum_lastvisit=D_57_1544683021; 7nPA_2132_visitedfid=57; 7nPA_2132_sendmail=1; 7nPA_2132_sid=NXsz2s; 7nPA_2132_lastact=1544683081%09forum.php%09ajax")
.addHeader("DNT","1")
.addHeader("Referer","https://bbs.cnnb.com.cn/member.php?mod=logging&action=logout&formhash=7663dd1d")
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36")
.setSleepTime(1000);
@Override
public void process(Page page) {
List titles = page.getHtml().xpath("//a[@class='s xst']/text()").all();
page.putField("title",titles);
}
@Override
public Site getSite() {
return site;
}
})
.addUrl("http://bbs.cnnb.com.cn/forum.php?mod=forumdisplay&fid=57")
.thread(1).start();
}
}
爬取Ajax动态数据
有些网站采用异步Ajax的方式获取列表数据,这些列表数据我们无法直接通过下载网址的文件得到,需要利用虚拟浏览器技术,以ChromeDriver为例,利用selenium-java编写的爬虫程序如下:
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.downloader.selenium.SeleniumDownloader;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class TestGetStockList{
public static void main(String[] args) {
System.setProperty("selenuim_config","D:\\workspace_spider\\webmagic\\webmagic-selenium\\src\\test\\resources\\config.ini");
Spider.create(new PageProcessor() {
private Site site = Site.me().setCharset("utf-8").setRetryTimes(3).setSleepTime(1000);
@Override
public void process(Page page) {
WebDriver driver = new ChromeDriver();
driver.get("http://www.sse.com.cn/assortment/stock/list/info/company/index.shtml?COMPANY_CODE=600000");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement webElement = driver.findElement(By.id("tableData_stockListCompany"));
String str = webElement.getAttribute("outerHTML");
System.out.println(str);
Html html = new Html(str);
System.out.println(html.xpath("//tbody/tr").all());
String companyCode = html.xpath("//tbody/tr[1]/td/text()").get();
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
String dateString = html.xpath("//tbody/tr[3]/td/text()").get().split("/")[0];
String stockCode = html.xpath("//tbody/tr[2]/td/text()").get().split("/")[0];
String name = html.xpath("//tbody/tr[5]/td/text()").get().split("/")[0];
String department = html.xpath("//tbody/tr[14]/td/text()").get().split("/")[0];
System.out.println(companyCode);
System.out.println(stockCode);
System.out.println(name);
System.out.println(department);
driver.close();
}
@Override
public Site getSite() {
return site;
}
}).thread(5)
.addUrl("http://www.sse.com.cn/assortment/stock/list/info/company/index.shtml?COMPANY_CODE=600000")
.run();
}
}
注:如果要让代码运行成功需要下载一个chromedriver,如果你是windows可以去这个网址去下https://chromedriver.storage.googleapis.com/2.25/chromedriver_win32.zip,虽然是32位的但是64位也可以用,如果不行的话或者你是其他OS,可以去官网下https://chromedriver.storage.googleapis.com/index.html?path=2.27/
https站点问题
有些https站点只支持TLS1.2,比如大名鼎鼎的Github网站,这时你需要修改框架源码,找到如下类:
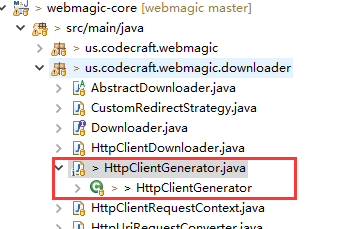
去除如下代码的红框部分:

否则将无法爬虫https站点数据。
处理非Get请求的爬虫
有时候,我们需要爬取非Get请求的数据,代码如下(其他诸如DELETE,PUT等请求方式类似):
Request req = new Request("http://www.baidu.com");
req.setMethod(HttpConstant.Method.POST)
//也可以采用form提交的方式.HttpRequestBody.form(map)
.setRequestBody(HttpRequestBody.json("{'id':1}","utf-8"));
spider.addRequest(req);
典型案例
抓取列表+详解
这里我们以作者的新浪博客http://blog.sina.com.cn/flashsword20作为例子。在这个例子里,我们要从最终的博客文章页面,抓取博客的标题、内容、日期等信息,也要从列表页抓取博客的链接等信息,从而获取这个博客的所有文章。
在这个例子中,我们的主要使用几个方法:
- 从页面指定位置发现链接,使用正则表达式来过滤链接.
- 在PageProcessor中处理两种页面,根据页面URL来区分需要如何处理。
package test.springboot2.webmagic;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @author [email protected]
*/
public class SinaBlogProcessor implements PageProcessor {
public static final String URL_LIST = "http://blog\\.sina\\.com\\.cn/s/articlelist_1487828712_0_\\d+\\.html";
public static final String URL_POST = "http://blog\\.sina\\.com\\.cn/s/blog_\\w+\\.html";
private Site site = Site
.me()
.setDomain("blog.sina.com.cn")
.setSleepTime(3000)
.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override
public void process(Page page) {
//列表页
if (page.getUrl().regex(URL_LIST).match()) {
page.addTargetRequests(page.getHtml().xpath("//div[@class=\"articleList\"]").links().regex(URL_POST).all());
page.addTargetRequests(page.getHtml().links().regex(URL_LIST).all());
//文章页
} else {
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath("//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",
page.getHtml().xpath("//div[@id='articlebody']//span[@class='time SG_txtc']").regex("\\((.*)\\)"));
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new SinaBlogProcessor())
.addUrl("http://blog.sina.com.cn/s/articlelist_1487828712_0_1.html")
.run();
}
}
后记
基于以上爬虫思路,如果让你设计一个爬虫管理控制中心,你该如何设计与实现呢?请关注我们后续文章,感谢阅读!