前言
在我们使用Flink DataStream API编写业务代码时,aggregate()算子和AggregateFunction无疑是非常常用的。编写一个AggregateFunction需要实现4个方法:
public interface AggregateFunction extends Function, Serializable {
ACC createAccumulator();
ACC add(IN value, ACC accumulator);
OUT getResult(ACC accumulator);
ACC merge(ACC a, ACC b);
}
前三个方法都很容易理解,但第四个merge()方法就有些令人费解了:到底什么时候需要合并两个累加器的数据呢?最近也有童鞋问到了这个问题。实际上,这个方法是专门为会话窗口(session window)服务的。下面来解析一下会话窗口。
Session Window & MergingWindowAssigner
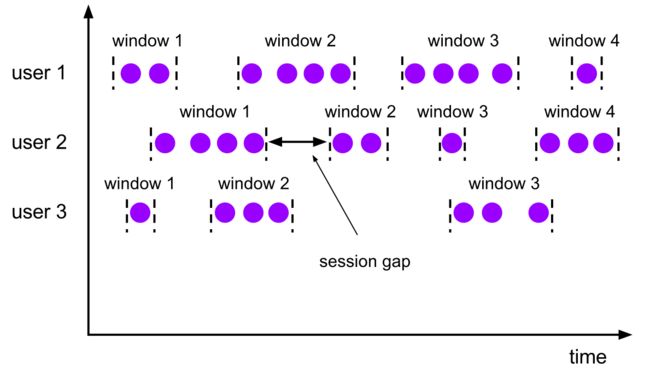
在普通的翻滚窗口和滑动窗口中,窗口的范围是按时间区间固定的,虽然范围有可能重合,但是处理起来是各自独立的,并不会相互影响。但是会话窗口则不同,其范围是根据事件之间的时间差是否超过gap来确定的(超过gap就形成一个新窗口),也就是说并非固定。所以,我们需要在每个事件进入会话窗口算子时就为它分配一个初始窗口,起点是它本身所携带的时间戳(这里按event time处理),终点则是时间戳加上gap的偏移量。这样的话,如果两个事件所在的初始窗口没有相交,说明它们属于不同的会话;如果相交,则说明它们属于同一个会话,并且要把这两个初始窗口合并在一起,作为新的会话窗口。多个事件则依次类推,最终形成上面图示的情况。
为了支持会话窗口的合并,它们的WindowAssigner也有所不同,称为MergingWindowAssigner,如下类图所示。
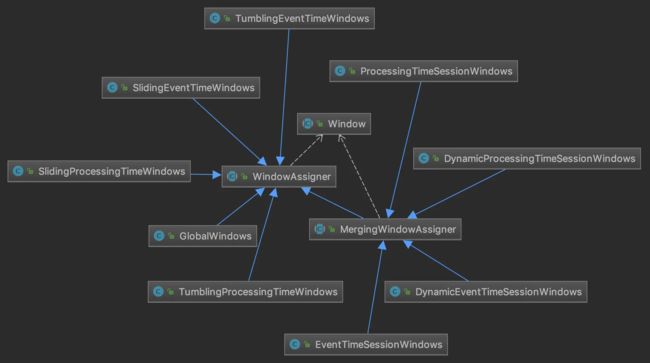
MergingWindowAssigner是一个抽象类,代码很简单,定义了用于合并窗口的mergeWindows()方法以及合并窗口时的回调MergeCallback。
public abstract class MergingWindowAssigner extends WindowAssigner {
private static final long serialVersionUID = 1L;
public abstract void mergeWindows(Collection windows, MergeCallback callback);
public interface MergeCallback {
void merge(Collection toBeMerged, W mergeResult);
}
}
所有MergingWindowAssigner实现类的mergeWindows()方法都是相同的,即直接调用TimeWindow.mergeWindows()方法,其源码如下。
public static void mergeWindows(Collection windows, MergingWindowAssigner.MergeCallback c)
// sort the windows by the start time and then merge overlapping windows
List sortedWindows = new ArrayList<>(windows);
Collections.sort(sortedWindows, new Comparator() {
@Override
public int compare(TimeWindow o1, TimeWindow o2) {
return Long.compare(o1.getStart(), o2.getStart());
}
});
List>> merged = new ArrayList<>();
Tuple2> currentMerge = null;
for (TimeWindow candidate: sortedWindows) {
if (currentMerge == null) {
currentMerge = new Tuple2<>();
currentMerge.f0 = candidate;
currentMerge.f1 = new HashSet<>();
currentMerge.f1.add(candidate);
} else if (currentMerge.f0.intersects(candidate)) {
currentMerge.f0 = currentMerge.f0.cover(candidate);
currentMerge.f1.add(candidate);
} else {
merged.add(currentMerge);
currentMerge = new Tuple2<>();
currentMerge.f0 = candidate;
currentMerge.f1 = new HashSet<>();
currentMerge.f1.add(candidate);
}
}
if (currentMerge != null) {
merged.add(currentMerge);
}
for (Tuple2> m: merged) {
if (m.f1.size() > 1) {
c.merge(m.f1, m.f0);
}
}
}
// TimeWindow.intersects()
public boolean intersects(TimeWindow other) {
return this.start <= other.end && this.end >= other.start;
}
// TimeWindow.cover()
public TimeWindow cover(TimeWindow other) {
return new TimeWindow(Math.min(start, other.start), Math.max(end, other.end));
}
该方法将所有待合并的窗口按照起始时间升序排序,遍历排序好的窗口,并调用intersects()方法判断它们是否相交。如果相交,则调用cover()方法合并返回一个覆盖两个窗口的窗口;如果不相交,则启动下一次合并过程。列表merged中存储的就是[合并结果, 原窗口集合]的二元组,如果原窗口集合的大小大于1,说明发生了合并,需要调用回调方法MergeCallback.merge()。
就这么简单吗?当然不是。上面的逻辑只是在时域的角度合并了窗口,但是别忘了,窗口是需要维护状态和触发器的,所以它们也得被合并才能保证不出错。下面就来介绍跟踪窗口状态合并的MergingWindowSet组件。
MergingWindowSet
MergingWindowSet的思路很直接:既然状态的创建和维护是比较重的操作,那么就在一批窗口合并时,以其中一个窗口的状态为基准,其他窗口的状态都直接合并到这个基准窗口的状态里来,称为“状态窗口”。这样就避免了创建新的状态实例,只需要维护合并的窗口与状态窗口之间的映射关系,以及保证映射关系的容错(通过ListState)即可。
// Mapping from window to the window that keeps the window state...
private final Map mapping;
// Mapping when we created the MergingWindowSet...
private final Map initialMapping;
private final ListState> state;
public W getStateWindow(W window) {
return mapping.get(window);
}
public void persist() throws Exception {
if (!mapping.equals(initialMapping)) {
state.clear();
for (Map.Entry window : mapping.entrySet()) {
state.add(new Tuple2<>(window.getKey(), window.getValue()));
}
}
}
MergingWindowSet的核心逻辑位于add()方法中。该方法输入一个新窗口,并试图将其时域和状态进行合并,代码如下。
public W addWindow(W newWindow, MergeFunction mergeFunction) throws Exception {
List windows = new ArrayList<>();
windows.addAll(this.mapping.keySet());
windows.add(newWindow);
final Map> mergeResults = new HashMap<>();
windowAssigner.mergeWindows(windows,
new MergingWindowAssigner.MergeCallback() {
@Override
public void merge(Collection toBeMerged, W mergeResult) {
if (LOG.isDebugEnabled()) {
LOG.debug("Merging {} into {}", toBeMerged, mergeResult);
}
mergeResults.put(mergeResult, toBeMerged);
}
});
W resultWindow = newWindow;
boolean mergedNewWindow = false;
// perform the merge
for (Map.Entry> c: mergeResults.entrySet()) {
W mergeResult = c.getKey();
Collection mergedWindows = c.getValue();
// if our new window is in the merged windows make the merge result the
// result window
if (mergedWindows.remove(newWindow)) {
mergedNewWindow = true;
resultWindow = mergeResult;
}
// pick any of the merged windows and choose that window's state window
// as the state window for the merge result
W mergedStateWindow = this.mapping.get(mergedWindows.iterator().next());
// figure out the state windows that we are merging
List mergedStateWindows = new ArrayList<>();
for (W mergedWindow: mergedWindows) {
W res = this.mapping.remove(mergedWindow);
if (res != null) {
mergedStateWindows.add(res);
}
}
this.mapping.put(mergeResult, mergedStateWindow);
// don't put the target state window into the merged windows
mergedStateWindows.remove(mergedStateWindow);
// don't merge the new window itself, it never had any state associated with it
// i.e. if we are only merging one pre-existing window into itself
// without extending the pre-existing window
if (!(mergedWindows.contains(mergeResult) && mergedWindows.size() == 1)) {
mergeFunction.merge(mergeResult,
mergedWindows,
this.mapping.get(mergeResult),
mergedStateWindows);
}
}
// the new window created a new, self-contained window without merging
if (mergeResults.isEmpty() || (resultWindow.equals(newWindow) && !mergedNewWindow)) {
this.mapping.put(resultWindow, resultWindow);
}
return resultWindow;
}
前面调用MergingWindowAssigner.mergeWindows()方法的逻辑已经提过了,重点在后面状态的合并。注释写得比较详细,多读几遍即可理解,不再多废话,只解释一下四个关键变量的含义:
- mergeResult:窗口的时域合并结果;
- mergedWindows:本次被合并的窗口集合;
- mergedStateWindow:将要合并的状态窗口结果(目前就是基准的状态窗口);
- mergedStateWindows:本次被合并的状态窗口集合。
最后,回调MergeFunction.merge()方法进行正式的合并。MergeFunction的定义同样位于MergingWindowSet中,其merge()方法的参数与上面四个变量是一一对应的。
public interface MergeFunction {
/**
* This gets called when a merge occurs.
*
* @param mergeResult The newly resulting merged {@code Window}.
* @param mergedWindows The merged {@code Window Windows}.
* @param stateWindowResult The state window of the merge result.
* @param mergedStateWindows The merged state windows.
* @throws Exception
*/
void merge(W mergeResult, Collection mergedWindows, W stateWindowResult, Collection mergedStateWindows) throws Exception;
}
接下来去到窗口算子WindowOperator中,完成最后一步。
Window Merging in WindowOperator
以下是WindowOperator.processElement()方法中,处理MergingWindowAssigner的部分。
@Override
public void processElement(StreamRecord element) throws Exception {
final Collection elementWindows = windowAssigner.assignWindows(
element.getValue(), element.getTimestamp(), windowAssignerContext);
//if element is handled by none of assigned elementWindows
boolean isSkippedElement = true;
final K key = this.getKeyedStateBackend().getCurrentKey();
if (windowAssigner instanceof MergingWindowAssigner) {
MergingWindowSet mergingWindows = getMergingWindowSet();
for (W window: elementWindows) {
// adding the new window might result in a merge, in that case the actualWindow
// is the merged window and we work with that. If we don't merge then
// actualWindow == window
W actualWindow = mergingWindows.addWindow(window, new MergingWindowSet.MergeFunction() {
@Override
public void merge(W mergeResult,
Collection mergedWindows, W stateWindowResult,
Collection mergedStateWindows) throws Exception {
if ((windowAssigner.isEventTime() && mergeResult.maxTimestamp() + allowedLateness <= internalTimerService.currentWatermark())) {
// ...
} else if (!windowAssigner.isEventTime()) {
// ...
}
triggerContext.key = key;
triggerContext.window = mergeResult;
triggerContext.onMerge(mergedWindows);
for (W m: mergedWindows) {
triggerContext.window = m;
triggerContext.clear();
deleteCleanupTimer(m);
}
// merge the merged state windows into the newly resulting state window
windowMergingState.mergeNamespaces(stateWindowResult, mergedStateWindows);
}
});
// drop if the window is already late
if (isWindowLate(actualWindow)) {
mergingWindows.retireWindow(actualWindow);
continue;
}
isSkippedElement = false;
W stateWindow = mergingWindows.getStateWindow(actualWindow);
if (stateWindow == null) {
throw new IllegalStateException("Window " + window + " is not in in-flight window set.");
}
windowState.setCurrentNamespace(stateWindow);
windowState.add(element.getValue());
triggerContext.key = key;
triggerContext.window = actualWindow;
TriggerResult triggerResult = triggerContext.onElement(element);
if (triggerResult.isFire()) {
ACC contents = windowState.get();
if (contents == null) {
continue;
}
emitWindowContents(actualWindow, contents);
}
if (triggerResult.isPurge()) {
windowState.clear();
}
registerCleanupTimer(actualWindow);
}
// need to make sure to update the merging state in state
mergingWindows.persist();
} else {
// ......
}
// ......
}
该方法先获得输入的流元素分配到的窗口,然后调用MergingWindowSet.addWindow()方法试图合并它。特别注意MergeFunction.merge()方法,它做了如下两件事:
- 调用TriggerContext.onMerge()方法,更新触发器注册的定时器时间,然后遍历所有被合并的原始窗口,调用TriggerContext.clear()方法删除它们的触发器,保证合并后的窗口能够被正确地触发;
- 调用InternalMergingState.mergeNamespaces()方法,将待合并窗口的状态与基准窗口的状态合并,产生的stateWindowResult就是状态窗口。
addWindow()方法返回的actualWindow就是合并之后的真正窗口,然后再根据MergingWindowSet中维护的映射关系,取出它所对应的状态窗口,并将输入元素加入状态窗口中。最后,根据更新后的触发器逻辑判断窗口需要fire还是purge,并触发执行相应的操作。整个窗口合并的流程就完成了。
Back on AggregateFunction
前面说了这么多,AggregateFunction.merge()方法到底在哪里呢?注意上一节中出现的用于合并窗口状态的InternalMergingState.mergeNamespaces()方法,InternalMergingState是Flink状态体系中所有能够合并的状态的基类。下面观察它的两个实现类:
- 基于堆的AbstractHeapMergingState→HeapAggregatingState
@Override
public void mergeNamespaces(N target, Collection sources) throws Exception {
if (sources == null || sources.isEmpty()) {
return; // nothing to do
}
final StateTable map = stateTable;
SV merged = null;
// merge the sources
for (N source : sources) {
// get and remove the next source per namespace/key
SV sourceState = map.removeAndGetOld(source);
if (merged != null && sourceState != null) {
merged = mergeState(merged, sourceState); // <----
} else if (merged == null) {
merged = sourceState;
}
}
// merge into the target, if needed
if (merged != null) {
map.transform(target, merged, mergeTransformation);
}
}
@Override
protected ACC mergeState(ACC a, ACC b) {
return aggregateTransformation.aggFunction.merge(a, b); // <----
}
- 基于RocksDB的RocksDBAggregatingState
@Override
public void mergeNamespaces(N target, Collection sources) {
if (sources == null || sources.isEmpty()) {
return;
}
try {
ACC current = null;
// merge the sources to the target
for (N source : sources) {
if (source != null) {
setCurrentNamespace(source);
final byte[] sourceKey = serializeCurrentKeyWithGroupAndNamespace();
final byte[] valueBytes = backend.db.get(columnFamily, sourceKey);
backend.db.delete(columnFamily, writeOptions, sourceKey);
if (valueBytes != null) {
dataInputView.setBuffer(valueBytes);
ACC value = valueSerializer.deserialize(dataInputView);
if (current != null) {
current = aggFunction.merge(current, value); // <----
}
else {
current = value;
}
}
}
}
// ......
}
catch (Exception e) {
throw new FlinkRuntimeException("Error while merging state in RocksDB", e);
}
}
可见,累加器其实就是AggregateFunction维护的状态。当AggregateFunction与会话窗口一同使用来实现增量聚合时,就会调用用户实现的merge()方法来合并累加器中的数据了。也就是说,如果我们没有使用会话窗口,那么不实现merge()方法同样没问题。
The End
本篇贴了太多代码,逻辑也比较绕,希望能讲清楚吧。
民那晚安晚安。