1. Cypher介绍
“Cypher”是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询。Cypher还在继续发展和成熟,这也就意味着有可能会出现语法的变化。同时也意味着作为组件没有经历严格的性能测试。
Cypher设计的目的是一个人类查询语言,适合于开发者和在数据库上做点对点模式(ad-hoc)查询的专业操作人员。它的构念是基于英语单词和灵巧的图解。
Cyper通过一系列不同的方法和建立于确定的实践为表达查询而激发的。许多关键字如like和order by是受SQL的启发。模式匹配的表达式来自于SPARQL。正则表达式匹配实现实用Scala programming language语言。
Cypher是一个申明式的语言。对比命令式语言如Java和脚本语言如Gremlin和JRuby,它的焦点在于从图中如何找回(what to retrieve),而不是怎么去做。这使得在不对用户公布的实现细节里关心的是怎么优化查询。
Neo4j使用Cypher查询图形数据,和SQL很相似,Cypher语言的关键字不区分大小写,但是属性值,标签,关系类型和变量是区分大小写的。
2. 基本语法
Cypher使用一对圆括号来表示一个节点:提供了多种格式如下:
() 匿名节点
(matrix) 为节点添加一个ID
(:Movie) Movie label标签,声明的是节点类型。noe4j的索引使用label,每个索引由标签和属性组成
(matrix:Movie)
(matrix:Movie {title: "The Matrix"}) 节点属性(如:title)代表一个key\value 的List
(matrix:Movie {title: "The Matrix", released: 1997})
RelationShip语法:
-- 表示一个无指向的关系
--> 表示一个有指向的关系
[] 能够添加ID,属性,类型等信息
-[role]->
-[:ACTED_IN]->
-[role:ACTED_IN]->
-[role:ACTED_IN {roles: ["Neo"]}]->
Pattern 语法:
节点和关系语法的合并就表示模式。
(keanu:Person:Actor {name: "Keanu Reeves"} )
-[role:ACTED_IN {roles: ["Neo"] } ]->
(matrix:Movie {title: "The Matrix"} )
Pattern Identifiers :
为模式分配ID,为例增加模块化和重复使用
acted_in = (:Person)-[:ACTED_IN]->(:Movie)
3. 创建节点
节点模式的构成:(Variable:Lable1:Lable2{Key1:Value1,Key2,Value2}),实际上,每个节点都有一个整数ID,在创建新的节点时,Neo4j自动为节点设置ID值,在整个数据库中,节点的ID值是递增的和唯一的。
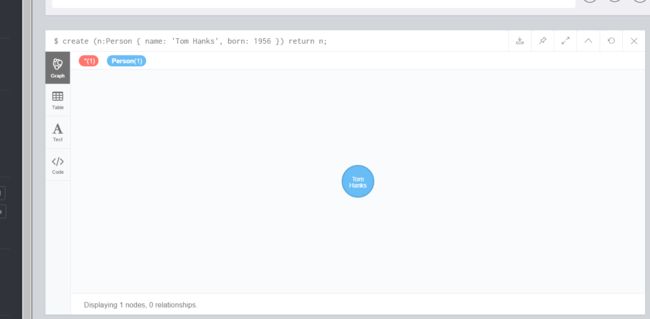
下面的Cypher查询创建一个节点,标签是Person,具有两个属性name和born,通过RETURN子句,返回新建的节点:
create (n:Person { name: 'Tom Hanks', born: 1956 }) return n;
继续创建其他节点:
create (n:Person { name: 'Robert Zemeckis', born: 1951 }) return n;
create (n:Movie { title: 'Forrest Gump', released: 1951 }) return n;
4. 查询节点
通过match子句查询数据库,match子句用于指定搜索的模式(Pattern),where子句为match模式增加谓词(Predicate),用于对Pattern进行约束;
4.1 查询整个图形数据库
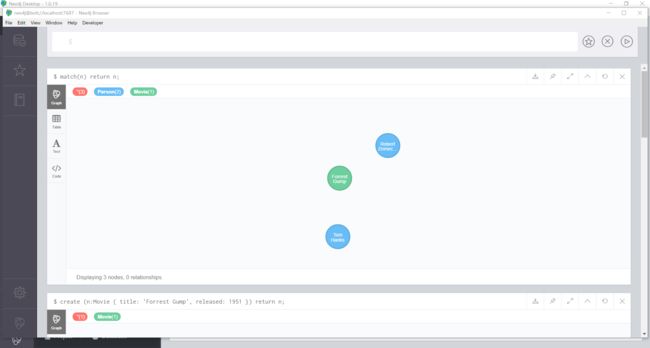
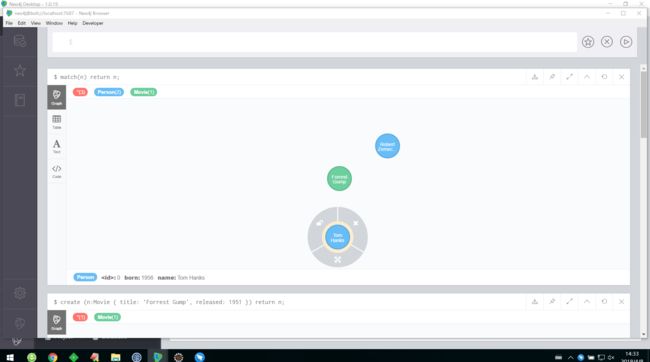
match(n) return n;
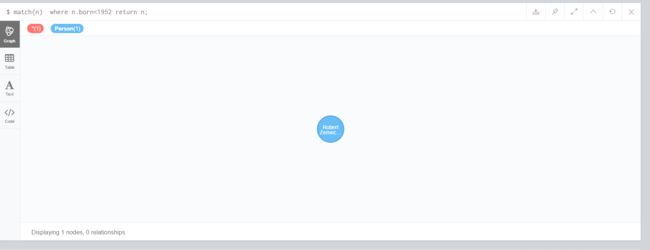
在图形数据库中,有三个节点,Person标签有连个节点,Movie有1个节点
4.2 查询born属性小于1952的节点
match(n)
where n.born<1952
return n;
4.3 查询具有指定Lable的节点
match(n:Movie)
return n;
4. 创建关系
关系的构成:StartNode - [Variable:RelationshipType{Key1:Value1,Key2:Value2}] -> EndNode,在创建关系时,必须指定关系类型。
4.1 创建没有任何属性的关系
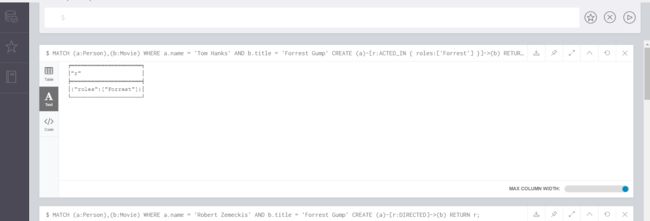
MATCH (a:Person),(b:Movie)
WHERE a.name = 'Robert Zemeckis' AND b.title = 'Forrest Gump'
CREATE (a)-[r:DIRECTED]->(b)
RETURN r;

4.2 创建关系,并设置关系的属性
MATCH (a:Person),(b:Movie)
WHERE a.name = 'Tom Hanks' AND b.title = 'Forrest Gump'
CREATE (a)-[r:ACTED_IN { roles:['Forrest'] }]->(b)
RETURN r;
5. 查询关系
在Cypher中,关系分为三种:符号--,表示有关系,忽略关系的类型和方向;符号-->和<--,表示有方向的关系;
5.1 查询整个数据图形
match(n) return n;

5.2 查询跟指定节点有关系的节点
示例脚本返回跟Movie标签有关系的所有节点
match(n)--(m:Movie)
return n;
5.2 查询有向关系的节点
MATCH (:Person { name: 'Tom Hanks' })-->(movie)
RETURN movie;
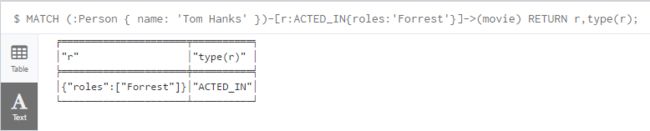
5.3 为关系命名,通过[r]为关系定义一个变量名,通过函数type获取关系的类型
MATCH (:Person { name: 'Tom Hanks' })-[r]->(movie)
RETURN r,type(r);

5.4 查询特定的关系类型,通过[Variable:RelationshipType{Key:Value}]指定关系的类型和属性
MATCH (:Person { name: 'Tom Hanks' })-[r:ACTED_IN{roles:'Forrest'}]->(movie)
RETURN r,type(r);
6. 更新操作
set子句,用于对更新节点的标签和实体的属性;remove子句用于移除实体的属性和节点的标签;
6.1 创建一个完整的Path
由于Path是由节点和关系构成的,当路径中的关系或节点不存在时,Neo4j会自动创建;
CREATE p =(vic:Worker:Person{ name:'vic',title:"Developer" })-[:WORKS_AT]->(neo)<-[:WORKS_AT]-(michael:Worker:Person { name: 'Michael',title:"Manager" })
RETURN p
变量neo代表的节点没有任何属性,但是,其有一个ID值,通过ID值为该节点设置属性和标签

6.2 为节点增加属性
通过节点的ID获取节点,Neo4j推荐通过where子句和ID函数来实现。
match (n)
where id(n)=7
set n.name = 'neo'
return n;
6.3 为节点增加标签
match (n)
where id(n)=7
set n:Company
return n;
6.4 为关系增加属性
match (n)<-[r]-(m)
where id(n)=7 and id(m)=8
set r.team='Azure'
return n;
7. Merge子句
Merge子句的作用有两个:当模式(Pattern)存在时,匹配该模式;当模式不存在时,创建新的模式,功能是match子句和create的组合。在merge子句之后,可以显式指定on create和on match子句,用于修改绑定的节点或关系的属性。
通过merge子句,你可以指定图形中必须存在一个节点,该节点必须具有特定的标签,属性等,如果不存在,那么merge子句将创建相应的节点。
7.1 通过merge子句匹配搜索模式
匹配模式是:一个节点有Person标签,并且具有name属性;如果数据库不存在该模式,那么创建新的节点;如果存在该模式,那么绑定该节点;
MERGE (michael:Person { name: 'Michael Douglas' })
RETURN michael;
7.2 在merge子句中指定on create子句
如果需要创建节点,那么执行on create子句,修改节点的属性;
ERGE (keanu:Person { name: 'Keanu Reeves' })
ON CREATE SET keanu.created = timestamp()
RETURN keanu.name, keanu.created
7.3 在merge子句中指定on match子句
如果节点已经存在于数据库中,那么执行on match子句,修改节点的属性;
MERGE (person:Person)
ON MATCH SET person.found = TRUE , person.lastAccessed = timestamp()
RETURN person.name, person.found, person.lastAccessed
7.4 在merge子句中同时指定on create 和 on match子句
MERGE (keanu:Person { name: 'Keanu Reeves' })
ON CREATE SET keanu.created = timestamp()
ON MATCH SET keanu.lastSeen = timestamp()
RETURN keanu.name, keanu.created, keanu.lastSeen
7.5 merge子句用于match或create一个关系
MATCH (charlie:Person { name: 'Charlie Sheen' }),(wallStreet:Movie { title: 'Wall Street' })
MERGE (charlie)-[r:ACTED_IN]->(wallStreet)
RETURN charlie.name, type(r), wallStreet.title
7.6 merge子句用于match或create多个关系
MATCH (oliver:Person { name: 'Oliver Stone' }),(reiner:Person { name: 'Rob Reiner' })
MERGE (oliver)-[:DIRECTED]->(movie:Movie)<-[:ACTED_IN]-(reiner)
RETURN movie
7.7 merge子句用于子查询
MATCH (person:Person)
MERGE (city:City { name: person.bornIn })
RETURN person.name, person.bornIn, city;
MATCH (person:Person)
MERGE (person)-[r:HAS_CHAUFFEUR]->(chauffeur:Chauffeur { name: person.chauffeurName })
RETURN person.name, person.chauffeurName, chauffeur;
MATCH (person:Person)
MERGE (city:City { name: person.bornIn })
MERGE (person)-[r:BORN_IN]->(city)
RETURN person.name, person.bornIn, city;
8. 跟实体相关的函数
8.1 通过id函数,返回节点或关系的ID
MATCH (:Person { name: 'Oliver Stone' })-[r]->(movie)
RETURN id(r);
8.2 通过type函数,查询关系的类型
MATCH (:Person { name: 'Oliver Stone' })-[r]->(movie)
RETURN type(r);
8.3 通过lables函数,查询节点的标签
MATCH (:Person { name: 'Oliver Stone' })-[r]->(movie)
RETURN lables(movie);
8.4 通过keys函数,查看节点或关系的属性键
MATCH (a)
WHERE a.name = 'Alice'
RETURN keys(a)
8.5 通过properties()函数,查看节点或关系的属性
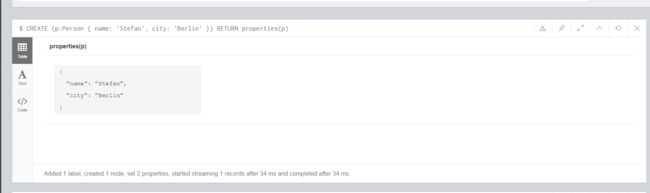
CREATE (p:Person { name: 'Stefan', city: 'Berlin' })
RETURN properties(p)