在真正开始Tensorflow并行运算代码实现之前,我们首先了解一下Tensorflow系统结构设计是如何完美的支持并行运算的。(参见博客)
1. Tensorflow系统概述
Tensorflow的系统结构以C API为界,将整个系统分为前端和后端两个子系统(见下图)

- 前端:提供编程模型,负责构造计算图
- 后端:提供运行环境,负责执行计算图
前端提供各种语言的库(主要是Python),前端库基于C API触发tensorflow后端程序运行。
后端的Distributed Runtime下的Distributed Master根据Session.run()的参数,从计算图中反向遍历,找到所依赖的最小子图,并将最小子图分裂为多个子图片段,派发给Work Service, 启动子图片段的执行过程。
Kernel主要包括一些具体操作,如卷积操作等。后端的最底层是网络层和设备层。网络层包括RPC和RDMA,负责传递神经网络的参数。
⚠️client、master 和 worker各组件的内部工作原理
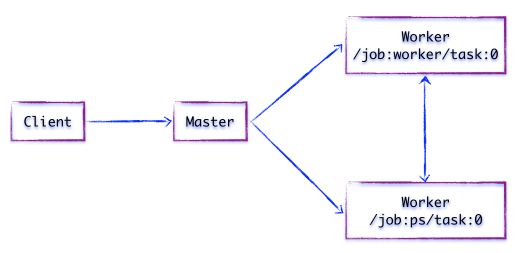
Client基于tensorflow的编程接口来构造计算图, 主要为Python和C++ 编程接口,直到Session会话被建立tensorflow才开始工作,Session建立Client和后端运行时的通道,将Graph发送给 Distributed Master,如下为Client构建了一个简单的计算Graph:

执行Session.run运算时,
Master将最小子图分片派发给
Work Service。如下图所示,
PS上放置模型参数,
worker上则执行op。
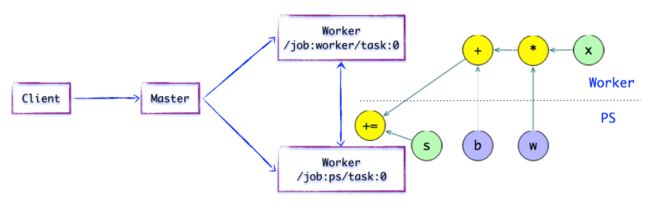
边被任务点分割,
Distributed Master会将该边分裂,并在两个分布式任务之间插入
send和
recv节点,实现数据传递。

2. Tensorflow multi GPU
Tensorflow官网给出了单GPU运行,多GPU运行的简单例子。这里需要注意的是:如果没有指定运行设备,会优先选用GPU(如果有GPU的话)。
对于深度学习来说,Tensorflow的并行主要包括数据并行和模型并行参见博客
2.1 数据并行
每个GPU上的模型相同,喂以相同模型不同的训练样本。
数据并行根据参数更新方式的不同又可以分为同步数据并行和异步数据并行。
同步数据并行:每个GPU根据loss计算各自的gradient,汇总所有GPU的gradient,求平均梯度,根据平均梯度更新模型参数,具体过程见下图。所以同步数据并行的速度取决于最慢的GPU,当各个GPU的性能相差不大时适用。

异步数据并行:和同步并行的区别是,不用等所有GPU的梯度,每个GPU均可更新参数。每个GPU每次取到的参数也是最新的。
据说缺点是:参数容易移出最优解。

数据并行,速度取决于最慢的GPU和中心服务器(分发数据,计算平均梯度的cpu/gpu)的快慢。
2.2 模型并行
同一批训练样本,将不同的模型计算部分分布在不同的计算设备上同时执行
模型并行,比如输入层到隐层的计算放到gpu0上,隐层到输出层的计算放到gpu1上。初始启动时gpu1是不工作的,要等gpu0输出后才能运行。能保证对同一批数据的同步吗?疑惑点⚠️
多机多卡,即client,master,worker不在同一台机器上时称之为分布式
3. 并行计算代码实现
代码中使用到的数据是自己写的数据,参见数据读取
3.1 同步数据并行
#!/usr/bin/env python
# _*_coding:utf-8 _*_
import tensorflow as tf
from tensorflow.python.client import device_lib
import os
import time
# 设置tf记录那些信息,这里有以下参数:
# 0 = all messages are logged (default behavior)
# 1 = INFO messages are not printed
# 2 = INFO and WARNING messages are not printed
# 3 = INFO, WARNING, and ERROR messages are not printed
# 在Linux下,运行python程序前,使用的语句是$ export TF_CPP_MIN_LOG_LEVEL=2
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
################# 获取当前设备上的所有GPU ##################
def check_available_gpus():
local_devices = device_lib.list_local_devices()
gpu_names = [x.name for x in local_devices if x.device_type == 'GPU']
gpu_num = len(gpu_names)
print('{0} GPUs are detected : {1}'.format(gpu_num, gpu_names))
return gpu_num # 返回GPU个数
# 设置使用设备上的哪些GPU,这样设置后,实际的GPU12对我的程序来说就是GPU0
os.environ['CUDA_VISIBLE_DEVICES'] = '12, 13, 14, 15'
N_GPU = 4 # 定义GPU个数
# 定义网络中需要使用一些参数
BATCH_SIZE = 100*N_GPU
LEARNING_RATE = 0.001
EPOCHS_NUM = 1000
NUM_THREADS = 10
# 定义读取数据和保存模型的路径
MODEL_SAVE_PATH = 'data/tmp/logs_and_models/'
MODEL_NAME = 'model.ckpt'
DATA_PATH = 'data/test_data.tfrecord'
# Dataset的解析函数
def _parse_function(example_proto):
dics = {
'sample': tf.FixedLenFeature([5], tf.int64),
'label': tf.FixedLenFeature([], tf.int64)}
parsed_example = tf.parse_single_example(example_proto, dics)
parsed_example['sample'] = tf.cast(parsed_example['sample'], tf.float32)
parsed_example['label'] = tf.cast(parsed_example['label'], tf.float32)
return parsed_example
# 读取数据并根据GPU个数进行均分
def _get_data(tfrecord_path = DATA_PATH, num_threads = NUM_THREADS, num_epochs = EPOCHS_NUM, batch_size = BATCH_SIZE, num_gpu = N_GPU):
dataset = tf.data.TFRecordDataset(tfrecord_path)
new_dataset = dataset.map(_parse_function, num_parallel_calls=num_threads)# 同时设置了多线程
# 这里需要注意的一个点是,目前从代码运行来看,shuffle必须放在repeat前面,才能正确运行。否则会报错: Out of Range
shuffle_dataset = new_dataset.shuffle(buffer_size=10000)# shuffle打乱顺序
repeat_dataset = shuffle_dataset.repeat(num_epochs)# 定义重复训练多少次全部样本
batch_dataset = repeat_dataset.batch(batch_size=batch_size)
iterator = batch_dataset.make_one_shot_iterator()# 创建迭代器
next_element = iterator.get_next()
x_split = tf.split(next_element['sample'], num_gpu)
y_split = tf.split(next_element['label'], num_gpu)
return x_split, y_split
# 由于对命名空间不理解,且模型的参数比较少,把参数的初始化放在外面,运行前只初始化一次。
# 但是,当模型参数多的时候,这样定义几百个会崩溃的。之后会详细介绍一下TF中共享变量的定义,解决此问题。
def _init_parameters():
w1 = tf.get_variable('w1', shape=[5, 10], initializer=tf.random_normal_initializer(mean=0, stddev=1, seed=9))
b1 = tf.get_variable('b1', shape=[10], initializer=tf.random_normal_initializer(mean=0, stddev=1, seed=1))
w2 = tf.get_variable('w2', shape=[10, 1], initializer=tf.random_normal_initializer(mean=0, stddev=1, seed=0))
b2 = tf.get_variable('b2', shape=[1], initializer=tf.random_normal_initializer(mean=0, stddev=1, seed=2))
return w1, w2, b1, b2
# 计算平均梯度,平均梯度是对样本个数的平均
def average_gradients(tower_grads):
avg_grads = []
# grad_and_vars代表不同的参数(含全部gpu),如四个gpu上对应w1的所有梯度值
for grad_and_vars in zip(*tower_grads)
grads = []
for g, _ in grad_and_vars:# 这里循环的是不同gpu
expanded_g = tf.expand_dims(g, 0) # 扩展一个维度代表gpu,如w1=shape(5,10), 扩展后变为shape(1,5,10)
grads.append(expanded_g)
grad = tf.concat(grads, 0) # 在第一个维度上合并
grad = tf.reduce_mean(grad, 0)# 求平均
v = grad_and_vars[0][1] # v 是变量
grad_and_var = (grad, v) # 这里是将平均梯度和变量对应起来
# 将不同变量的平均梯度append一起
avg_grads.append(grad_and_var)
# return average gradients
return avg_grads
# 初始化变量
w1, w2, b1, b2 = _init_parameters()
# 获取训练样本
x_split, y_split = _get_data()
# 建立优化器
opt = tf.train.GradientDescentOptimizer(LEARNING_RATE)
tower_grads = []
# 将神经网络中前传过程分配给不同的gpu训练不同的样本
for i in range(N_GPU):
with tf.device("/gpu:%d" % i):
y_hidden = tf.nn.relu(tf.matmul(x_split[i], w1) + b1)
y_out = tf.matmul(y_hidden, w2) + b2
y_out = tf.reshape(y_out, [-1])
cur_loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=y_out, labels=y_split[i], name=None)
grads = opt.compute_gradients(cur_loss)
tower_grads.append(grads)
###### 这里建立一个session主要是想获取参数的具体数值,以查看是否对于每一个gpu来说都没有更新参数。
##### 当然,这里从程序也能看出,在每个gpu上只是计算梯度,并没有更新参数。
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)) as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
sess.run(tower_grads)
print('=============== parameter test sy =========')
print(i)
print(sess.run(b1))
coord.request_stop()
coord.join(threads)
# 计算平均梯度
grads = average_gradients(tower_grads)
# 用平均梯度更新模型参数
apply_gradient_op = opt.apply_gradients(grads)
# allow_soft_placement是当指定的设备如gpu不存在是,用可用的设备来处理。
# log_device_placement是记录哪些操作在哪个设备上完成的信息
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)) as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
for step in range(1000):
start_time = time.time()
sess.run(apply_gradient_op)
duration = time.time() - start_time
if step != 0 and step % 100 == 0:
num_examples_per_step = BATCH_SIZE * N_GPU
examples_per_sec = num_examples_per_step / duration
sec_per_batch = duration / N_GPU
print('step:', step, grads, examples_per_sec, sec_per_batch)
print('=======================parameter b1============ :')
print(sess.run(b1))
coord.request_stop()
coord.join(threads)
- 计算所有gpu的平均梯度,再更新参数。
- 计算所有gpu平均损失函数,用梯度更新参数
- 各个gpu得到新参数,再平均更新参数,这样有没有影响,参数暂时怎么存放等。
1和2的结果理论上应该是相同的
3.2 异步数据并行
'''
这里先定义训练模型,利用optimizer.minimize()直接更新模型参数
'''
def _model_nn(w1, w2, b1, b2, x_split, y_split, i_gpu):
y_hidden = tf.nn.relu(tf.matmul(x_split[i_gpu], w1) + b1)
y_out = tf.matmul(y_hidden, w2) + b2
y_out = tf.reshape(y_out, [-1])
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=y_out, labels=y_split[i_gpu], name=None)
opt = tf.train.GradientDescentOptimizer(LEARNING_RATE)
train = opt.minimize(loss)
return train
w1, w2, b1, b2 = _init_parameters()
x_split, y_split = _get_data()
for i in range(N_GPU):
with tf.device("/gpu:%d" % i):
train = _model_nn(w1, w2, b1, b2, x_split, y_split, i)
##### 同样,这里建立session主要是为了检查在每个gpu的时候,变量是否更新了。
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)) as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
sess.run(train)
print('=============== parameter test Asy =========')
print(i)
print(sess.run(b1))
coord.request_stop()
coord.join(threads)
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)) as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
for step in range(2):
sess.run(train)
print('======================= parameter b1 ================ :')
print('step:', step, sess.run(b1)
coord.request_stop()
coord.join(threads)
4. 共享变量
之前提到了我们在定义多层变量时,一个一个定义权重和偏置,对于大型网络是不太现实和让人崩溃的。所有就有了tf.variable_scope 和 tf.name_scope()。
-
tf.name_scope()主要是与Variable配合,方便参数命名管理 -
tf.variable_scope与tf.get_variable配合使用,实现变量共享
tf.name_scope命名空间是便于管理变量,不同命名空间下的用Variable定义的变量名允许相同。可以理解为名字相同,但是姓(命名空间)不同,指向的也是不同变量。
而tf.get_variable()定义的变量不受命名空间的限制(主要是用于共享变量,避免大型网络结构中定义过多的模型参数。
我们主要看tf.variable_scope()的使用。
tf.variable_scope(
name_or_scope, # name
default_name=None,
values=None,
initializer=None,
regularizer=None,
caching_device=None,
partitioner=None,
custom_getter=None,
reuse=None, # True, None, or tf.AUTO_REUSE;
# if True, we go into reuse mode for this scope as well as all sub-scopes;
# if tf.AUTO_REUSE, we create variables if they do not exist, and return them otherwise;
# if None, we inherit the parent scope's reuse flag. When eager execution is enabled, new variables are always created unless an EagerVariableStore or template is currently active.
dtype=None,
use_resource=None,
constraint=None,
auxiliary_name_scope=True
)
tf.variable_scope()可以理解为从某个name的篮子里取东西。在这个篮子里,只要名字相同,下次可以反复的用这个变量。
tf.variable_scope()可以节省内存,官网的例子:
import tensorflow as tf
def my_image_filter():
conv1_weights = tf.Variable(tf.random_normal([5, 5, 32, 32]),
name="conv1_weights")
conv1_biases = tf.Variable(tf.zeros([32]), name="conv1_biases")
conv2_weights = tf.Variable(tf.random_normal([5, 5, 32, 32]),
name="conv2_weights")
conv2_biases = tf.Variable(tf.zeros([32]), name="conv2_biases")
return
# First call creates one set of 4 variables.
result1 = my_image_filter()
# Another set of 4 variables is created in the second call.
result2 = my_image_filter()
# 获取所有的可训练变量
vs = tf.trainable_variables()
print('There are %d train_able_variables in the Graph: ' % len(vs))
for v in vs:
print(v)
这是官网上的例子,从输出可以看出调用my_image_fileter()两次,会有8个变量
There are 8 train_able_variables in the Graph:
如果用tf.variable_scope()共享变量会怎么样呢?
import tensorflow as tf
# 定义一个卷积层的通用方式
def conv_relu(kernel_shape, bias_shape):
# Create variable named "weights".
weights = tf.get_variable("weights", kernel_shape, initializer=tf.random_normal_initializer())
# Create variable named "biases".
biases = tf.get_variable("biases", bias_shape, initializer=tf.constant_initializer(0.0))
return
def my_image_filter():
# 按照下面的方式定义卷积层,非常直观,而且富有层次感
with tf.variable_scope("conv1"):
# Variables created here will be named "conv1/weights", "conv1/biases".
relu1 = conv_relu([5, 5, 32, 32], [32])
with tf.variable_scope("conv2"):
# Variables created here will be named "conv2/weights", "conv2/biases".
return conv_relu([5, 5, 32, 32], [32])
with tf.variable_scope("image_filters") as scope:
# 下面我们两次调用 my_image_filter 函数,但是由于引入了 变量共享机制
# 可以看到我们只是创建了一遍网络结构。
result1 = my_image_filter()
scope.reuse_variables()
result2 = my_image_filter()
# 获取所有的可训练变量
vs = tf.trainable_variables()
print('There are %d train_able_variables in the Graph: ' % len(vs))
for v in vs:
print(v)
输出为:
There are 4 train_able_variables in the Graph:


下面我们用命名空间整理一下之前简单二分类的网络结构:
#!/usr/bin/env python
# _*_coding:utf-8 _*_
import os
import tensorflow as tf
# set environment
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# set the visible_devices
os.environ['CUDA_VISIBLE_DEVICES'] = '12, 13, 14, 15'
# GPU list
N_GPU = 4 # GPU number
# define parameters of neural network
BATCH_SIZE = 100*N_GPU
LEARNING_RATE = 0.001
EPOCHS_NUM = 1000
NUM_THREADS = 10
# define the path of log message and model
DATA_DIR = 'data/tmp/'
LOG_DIR = 'data/tmp/log'
DATA_PATH = 'data/test_data.tfrecord'
# get train data
def _parse_function(example_proto):
dics = {
'sample': tf.FixedLenFeature([5], tf.int64),
'label': tf.FixedLenFeature([], tf.int64)}
parsed_example = tf.parse_single_example(example_proto, dics)
parsed_example['sample'] = tf.cast(parsed_example['sample'], tf.float32)
parsed_example['label'] = tf.cast(parsed_example['label'], tf.float32)
return parsed_example
def _get_data(tfrecord_path = DATA_PATH, num_threads = NUM_THREADS, num_epochs = EPOCHS_NUM, batch_size = BATCH_SIZE, num_gpu = N_GPU):
with tf.variable_scope('input_data'):
dataset = tf.data.TFRecordDataset(tfrecord_path)
new_dataset = dataset.map(_parse_function, num_parallel_calls=num_threads)
shuffle_dataset = new_dataset.shuffle(buffer_size=10000)
repeat_dataset = shuffle_dataset.repeat(num_epochs)
batch_dataset = repeat_dataset.batch(batch_size=batch_size)
iterator = batch_dataset.make_one_shot_iterator()
next_element = iterator.get_next()
x_split = tf.split(next_element['sample'], num_gpu)
y_split = tf.split(next_element['label'], num_gpu)
return x_split, y_split
def weight_bias_variable(weight_shape, bias_shape):
weight = tf.get_variable('weight', weight_shape, initializer=tf.random_normal_initializer(mean=0, stddev=1))
bias = tf.get_variable('bias', bias_shape, initializer=tf.random_normal_initializer(mean=0, stddev=1))
return weight, bias
# 隐藏层的函数定义,我们可以根据layer_name来设定不同的隐藏层。这个程序里只是用了单隐层。
def hidden_layer(x_data, input_dim, output_dim, layer_name):
with tf.variable_scope(layer_name, reuse=tf.AUTO_REUSE):
weight, bias = weight_bias_variable([input_dim, output_dim], [output_dim])
# calculation output
y_hidden = tf.nn.relu(tf.matmul(x_data, weight) + bias)
tf.summary.histogram('weight', weight)
tf.summary.histogram('bias', bias)
tf.summary.histogram('y_hidden', y_hidden)
return y_hidden
# 由于输出层在计算输出时暂时不用激活函数,激活函数在计算损失函数时设定。所以这里单独创建了输出层
def output_grads(y_hidden, y_label, input_dim, output_dim):
with tf.variable_scope('out_layer', reuse=tf.AUTO_REUSE):
weight, bias = weight_bias_variable([input_dim, output_dim], [output_dim])
tf.summary.histogram('bias', bias)
y_out = tf.matmul(y_hidden, weight) + bias
y_out = tf.reshape(y_out, [-1])
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=y_out, labels=y_label)
loss_mean = tf.reduce_mean(loss, 0)
tf.summary.scalar('loss', loss_mean)
grads = opt.compute_gradients(loss_mean)
return loss_mean, grads
# calculate gradient
def average_gradients(tower_grads):
avg_grads = []
# list all the gradient obtained from different GPU
# grad_and_vars represents gradient of w1, b1, w2, b2 of different gpu respectively
for grad_and_vars in zip(*tower_grads): # w1, b1, w2, b2
# calculate average gradients
# print('grad_and_vars: ', grad_and_vars)
grads = []
for g, _ in grad_and_vars: # different gpu
expanded_g = tf.expand_dims(g, 0) # expand one dimension (5, 10) to (1, 5, 10)
grads.append(expanded_g)
grad = tf.concat(grads, 0) # for 4 gpu, 4 (1, 5, 10) will be (4, 5, 10),concat the first dimension
grad = tf.reduce_mean(grad, 0) # calculate average by the first dimension
# print('grad: ', grad)
v = grad_and_vars[0][1] # get w1 and then b1, and then w2, then b2, why?
# print('v',v)
grad_and_var = (grad, v)
# print('grad_and_var: ', grad_and_var)
# corresponding variables and gradients
avg_grads.append(grad_and_var)
return avg_grads
# get samples and labels
with tf.name_scope('input_data'):
x_split, y_split = _get_data()
# set optimizer
opt = tf.train.GradientDescentOptimizer(LEARNING_RATE)
tower_grads = []
for i in range(N_GPU):
with tf.device("/gpu:%d" % i):
with tf.name_scope('GPU_%d' %i) as scope:
y_hidden = hidden_layer(x_split[i], input_dim=5, output_dim=10, layer_name='hidden1')
loss_mean, grads = output_grads(y_hidden, y_label=y_split[i], input_dim=10, output_dim=1)
tower_grads.append(grads)
with tf.name_scope('update_parameters'):
# get average gradient
grads = average_gradients(tower_grads)
for i in range(len(grads)):
tf.summary.histogram('gradients/'+grads[i][1].name, grads[i][0])
# update parameters。
apply_gradient_op = opt.apply_gradients(grads)
init = tf.global_variables_initializer()
config = tf.ConfigProto()
config.gpu_options.allow_growth = False # 配置GPU内存分配,刚一开始分配少量的GPU容量,
# 然后按需慢慢的增加,由于不会释放内存,所以会导致碎片
config.allow_soft_placement = True # 当指定设备不存在时,找可用设备
config.log_device_placement = False
with tf.Session(config=config) as sess:
sess.run(init)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('data/tfboard', sess.graph)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
for step in range(1000):
sess.run(apply_gradient_op)
summary = sess.run(merged)
writer.add_summary(summary, step)
writer.close()
coord.request_stop()
coord.join(threads)
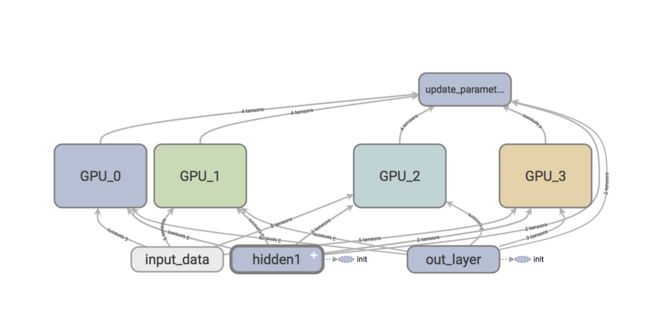
根据保存路径,在终端输入:
$ tensorboard --logdir=路径(例如:/Users/username/PycharmProjects/firsttensorflow/multigpu/data/tfboard)
在浏览器中输入http://localhost:6006,出现tensorboard的界面,默认界面是scalar(标量):

切换到graph界面如下图所示: