1.知识图谱:
1).描述客观世界中存在的实体或概念;
2).其中每个实体或概念有一个唯一ID标识,称之为标识符;(实体)
3).每个(属性-值)描述各个实体或概念的内在特性,用关系来描述各个实体或者概念的关联;(关系)
提供一种丰富的语义信息,建立与现实世界实体的关系;
2.知识图谱的构建:
1)数据源:主要是文本、dom trees,html表格、RDF语义数据,用于信息抽取,多数据源也可有效的判定知识的可信性;
a.大规模知识库,比如百度百科、wiki百科、以及一些大公司资助的知识库(谷歌收购的Freebase,德国莱比锡大学等DBpedia,德国马克斯·普朗特研究所的YAGO等等),还有一些领域专家整理的领域知识库;
b.互联网链接数据:就是W3C发起的项目Linked opend data (LOD) :将互联网文档组成的万维网(web of document)扩展成互联数据组成的知识空间(web of data),LOD通过RDF(resource description framework)形式在web上发布各种开放数据集;
ps:RDF是一种描述结构化数据的框架,它将实体间的关系表示为(实体1,关系,实体2)的三元组;
RDF还允许不同来源的数据项之间设置RDF链接,实现语义web知识库。但有一些问题:主要是很多机构发布的数据集存在冗余和异构等问题;
c.互联网网页文本数据:从海量的互联网中直接抽取数据,当然很多就是无结构化的数据了,很多人采取的方式是只采集表格中的数据等;
2)知识融合:
涉及‘实体融合’,‘关系融合’,‘实例融合’;(实例= 实体+关系);
其一,实体融合涉及三个处理:1.同区域下的不同实体名称称谓规约到同一个实体下,2.同一个称谓在不同语言不同地区不同国家的命名;3.同一个实体名在不同的语境下会有不同的含义(例如‘苹果’)
其二:关系融合与实体融合大体一致;
其三:实例融合在处理了实体融合和关系融合之后,就开始处理三元组实例的融合;
3.知识图谱的主要技术点,智能信息处理技术
1)实体链指(Entity Linking)
将网页中出现的实体链接到相应的知识库词条上,实际上是将互联网网页与实体之间建立了链接关系;
需要做的事情:计算机自动实现实体链指,需要注意的是知识图谱不仅包含实体,而且还还有大量概念(concept)
具体要实现:实体识别(entity recognition)和实体消歧(entity disambiguation)
实体链指不局限于文本和实体,包括图像,社交媒体,数据与实体的关联。
2)关系抽取(Relation Extraction)
构建知识图谱的重要来源之一就是从互联网网页文本中抽取实体关系。关系抽取是一种典型的信息抽取任务。
其典型的方法是采用自举(bootstrapping)的思想:
a.按照‘模板生成->实例抽取’的流程不断迭代直至收敛。举例说明:‘X是Y的首都’模板取出(中国,首都,北京)等三元组实例;然后根据这些三元组中的实例对‘中国-北京’可以发现更多的匹配模板,如‘Y的首都是X’,'X是Y的政治中心'等,进而用新发现的模板抽取更多新的三元组实例,通过反复迭代不断抽取新的实例与模板。但是这种方法虽然直观有效,但是面临很多的挑战问题,如在扩展中遇到很容易引入噪声实例和模板,出现语义漂移的现象,降低抽取准确度。当然处理这些问题现象有一些方法,比如‘同时扩展多个互斥类别的知识’,‘提出引入负实例来限制语义漂移‘。
b. 也可以通过识别表达语义关系的短语来抽取实体间的关系,通过句法分析出实体的多个关系(同一个意思的多种表达),一般是一个以动词为核心的短语,无需人工定义关系的种类,但是这种自由度带来的问题是没有归一化,自动发现的关系进行的聚类归约是一个挑战性问题;
c.将关系看成分类标签,把关系抽取转换成对实体对的关系分类问题,采用此方法的缺陷主要来源于缺乏标注语料。斯坦福(远程监督思想)使用知识图谱中已有的三元组实例启发式的标注训练语料,将知识图谱三元组中每个实体看做待分类样例,将知识图谱中实体对关系看做分类标签,通过从出现实体对的所有句子中抽取特征,利用机器学习分类模型(如最大熵分类、SVM等)构建信息抽取系统。远程监督能够根据知识图谱自动构建大规模标注语料库,但是和自举思想一样,同样也会出现大量噪声训练样例,严重损害模型准确度。处理方法:一个正确训练实例往往位于语义一致的区域,也就是其周边的实例应用拥有相同的关系,也可以利用因子图、矩阵分解等方法,建立数据内部的关联关系,以实现有效降低噪声;
3)知识推理(Knowledge Reasoning)
首先,推理能力是人类智能的重要特征,能够从已有的知识中发现隐含的知识。其需要相关规则的支持;
毋庸置疑,通过人工手工构建,很费时间精力,如何自动挖掘相关推理规则或模式,现在主要依赖关系之间的同现情况,利用关联挖掘技术来自动发现推理规则;
实体之间有丰富的同现信息,比如X,Y,Z间出现的实例(x,父亲,y),(y,父亲,z)以及(x,祖父,z)统计出(父亲+父亲->祖父)。利用推理规则实现关系抽取的经典方法是Path Ranking Algorithm (Lao & Cohen 2010),该方法将每种不同的关系路径作为一维特征,通过在知识图谱中统计大量的关系路径构建关系分类的特征向量,建立关系分类器进行关系抽取,取得不错的抽取效果,成为近年来的关系抽取的代表方法之一。但这种基于关系的同现统计的方法,面临严重的数据稀疏问题。 在知识推理方面还有很多的探索工作,例如采用谓词逻辑(Predicate Logic)等形式化方法和马尔科夫逻辑网络(Markov Logic Network)等建模工具进行知识推理研究。目前来看,这方面研究仍处于百家争鸣阶段,大家在推理表示等诸多方面仍为达成共识,未来路径有待进一步探索。
4)知识表示(knowledge Representation)
在计算机中如何对知识图谱进行表示与存储,往往将知识图谱作为复杂网络进行存储,这个网络的每个节点带有实体标签,而每条边带有关系标签。基于这种网络的表示方案,知识图谱的相关应用任务往往需要借助于 图算法来完成。该表示方法面临严重的数据稀疏问题,对于那些对外连接较少的实体,一些图方法可能束手无策或效果不佳。此外,图算法往往计算复杂度较高,无法适应大规模知识图谱的应用需求。
方法:伴随着深入学习和表示学习的发展,知识图谱的实体和关系的语义信息用低维向量表示,这种分布式表示(Distributed Representation)方案能够极大地帮助基于网络的表示方案。其中,最简单有效的模型是最近提出的TransE(Bordes, et al. 2013)。TransE基于实体和关系的分布式向量表示,将每个三元组实例(head,relation,tail)中的关系relation看做从实体head到实体tail的翻译,通过不断调整h、r和t(head、relation和tail的向量),使(h + r) 尽可能与 t 相等,即 h + r = t。
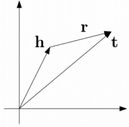
利用分布式向量,我们可以通过欧氏距离或余弦距离等方式,很容易地计算实体间、关系间的语义相关度。这将极大的改进开放信息抽取中实体融合和关系融合的性能。通过寻找给定实体的相似实体,还可用于查询扩展和查询理解等应用。这种向量表示有一些作用,1.反过来,知识表示可以用于关系抽取,给定两个实体h和t的时候,可以通过寻找与t-h最相似的r来寻找,两个实体间的关系,实验证明,该方法的抽取性能较高。而且我们可以发现,该方法仅需要知识图谱作为训练数据,不需要外部的文本数据,因此这又称为知识图谱补全(Knowledge Graph Completion),与复杂网络中的链接预测(Link Prediction)类似,但是要复杂得多,因为在知识图谱中每个节点和连边上都有标签(标记实体名和关系名)。2.知识表示向量还可以用于发现关系间的推理规则。例如,对于大量X、Y、Z间出现的(X,父亲,Y)、(Y,父亲,Z)以及(X,祖父,Z)实例,我们在TransE中会学习X+父亲=Y,Y+父亲=Z,以及X+祖父=Z等目标。根据前两个等式,我们很容易得到X+父亲+父亲=Z,与第三个公式相比,就能够得到“父亲+父亲=>祖父”的推理规则。前面我们介绍过,基于关系的同现统计学习推理规则的思想,存在严重的数据稀疏问题。如果利用关系向量表示提供辅助,可以显著缓解稀疏问题。
4.关注点
根据各搜索引擎公司提供的报告来看,为了保证知识图谱的准确率,仍然需要在知识图谱构建过程中采用较多的人工干预。
1.知识类型与表示。知识图谱主要采用(实体1,关系,实体2)三元组的形式来表示知识,这种方法可以较好的表示很多事实性知识。然而,人类知识类型多样,面对很多复杂知识,三元组就束手无策了。例如,人们的购物记录信息,新闻事件等,包含大量实体及其之间的复杂关系,更不用说人类大量的涉及主观感受、主观情感和模糊的知识了。有很多学者针对不同场景设计不同的知识表示方法。知识表示是知识图谱构建与应用的基础,如何合理设计表示方案,更好地涵盖人类不同类型的知识,是知识图谱的重要研究问题。最近认知领域关于人类知识类型的探索(Tenenbaum, et al. 2011)也许会对知识表示研究有一定启发作用。
2.知识获取。如何从互联网大数据萃取知识,是构建知识图谱的重要问题。目前已经提出各种知识获取方案,并已经成功抽取大量有用的知识。但在抽取知识的准确率、覆盖率和效率等方面,都仍不如人意,有极大的提升空间。
3.知识融合。来自不同数据的抽取知识可能存在大量噪音和冗余,或者使用了不同的语言。如何将这些知识有机融合起来,建立更大规模的知识图谱,是实现大数据智能的必由之路。
4.知识应用。目前大规模知识图谱的应用场景和方式还比较有限,如何有效实现知识图谱的应用,利用知识图谱实现深度知识推理,提高大规模知识图谱计算效率,需要人们不断锐意发掘用户需求,探索更重要的应用场景,提出新的应用算法。这既需要丰富的知识图谱技术积累,也需要对人类需求的敏锐感知,找到合适的应用之道。
5.总结:
• 知识图谱是下一代搜索引擎、自动问答等智能应用的基础设施。
• 互联网大数据是知识图谱的重要数据来源。
• 知识表示是知识图谱构建与应用的基础技术。
• 实体链指、关系抽取和知识推理是知识图谱构建与应用的核心技术。
知识图谱与本体(Ontology)和语义网(Semantic Web)等密切相关,有兴趣的亲可以搜索与之相关的文献阅读。知识表示(Knowledge Representation)是人工智能的重要课题,读者可以通过人工智能专著(Russell & Norvig 2009)了解其发展历程。在关系抽取方面,读者可以阅读(Nauseates, et al. 2013)、(Nickel, et al. 2015)详细了解相关技术。
--毕,此部分为知识库部分读书笔记。