Go 语言作为一门为编写网络应用程序而生的编程语言,在拥有比 Java 更强的并发性的同时,有拥有比 C 和 C++ 更快的开发速度(得益于简洁的语法和丰富的标准库),非常适合用于开发爬虫程序。笔者基于 Go 语言开发了一个爬虫程序,并从单任务版本改良为并发式版本,最后演进为分布式版本。下面就分享出并发式版本和分布式版的架构和设计思想。
并发式爬虫
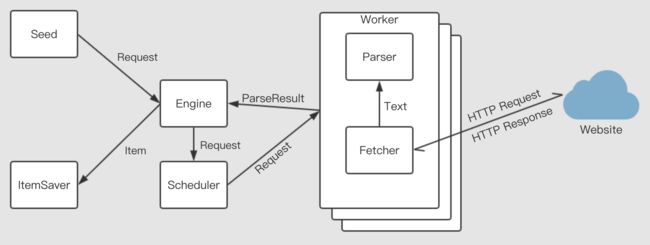
并发式版本利用了 Go 语言强大的并发性能,解决了单任务版本爬取速度慢的问题。并发式版本由四大部分构成,分别是Engine、Scheduler、Worker和Saver。
- 爬虫程序输入一个由 URL 和 Parser 构成的种子 Request
- Engine 会将接收的每个 Request 传递给维护着一个 Request 队列和一个 可用 Worker 队列的 Scheduler
- Scheduler 依据 FIFO 的原则将 Request 任务分配给 Worker
- 每个包含 Fetcher 和 Parser 的 Goroutine 代表一个 Worker,每个 Worker 并发执行任务,任务完成后重新加入 Scheduler 中的可用 Worker 队列。Fetcher 首先网络请求 Request 中的 URL 地址,并将返回的网络响应传递给 Parser,Parser 再讲网络响应中需要的信息解析并提取出来,再返回给 Engine
- Worker 返回给 Engine 的 ParseResult 中既包含我们需要得到的信息 Item,又包括需要进一步爬取的 Request 任务,Engine 再将任务提交给 Scheduler 之前需要先进行去重处理,以防重复爬取
- Engine 将需要保存的 Item 通过通道发送给 Saver
Model
// 请求,包括URL和指定的解析函数
type Request struct {
Url string
Parser Parser
}
// 解析结果
type ParseResult struct {
Requests []Request
Items []Item
}
// 最终要保存的条目
type Item struct {
Url string
Id string
Type string
Payload interface{}
}
Engine
type ConcurrentEngine struct {
MaxWorkerCount int // 工作协程的数量
Scheduler Scheduler // 任务调度器
ItemChan chan Item // 与ItemSaver之间的通道
RequestWorker Processor // Worker的处理器
}
type Processor func(request Request) (ParseResult, error)
type Scheduler interface {
Submit(request Request)
GetWorkerChan() chan Request
Run()
Ready
}
type Ready interface {
WorkerReady(chan Request)
}
func (e *ConcurrentEngine) Run(seed ...Request) {
out := make(chan ParseResult, 1024) // Worker返回任务结果的通道,缓冲区大小为1024
e.Scheduler.Run()
// 根据配置的Worker数量创建Goroutin
for i := 0; i < e.MaxWorkerCount; i++ {
e.createWorker(e.Scheduler.GetWorkerChan(), out, e.Scheduler)
}
for _, r := range seed {
// 先去重,再提交任务给Scheduler
if IsDuplicate(r.Url) {
continue
}
e.Scheduler.Submit(r)
}
for {
result := <-out // 获取Worker返回的结果
for _, item := range result.Items {
go func() { e.ItemChan <- item }() // 给Saver发送Item
}
for _, r := range result.Requests {
// 先去重,再提交任务给Scheduler
if IsDuplicate(r.Url) {
continue
}
e.Scheduler.Submit(r)
}
}
}
/**
* Worker工厂函数
* in Scheduler向Worker发送任务的通道
* out Worker向Engine返回结果的通道
* s 实现了Ready接口的Scheduler
*/
func (e *ConcurrentEngine) createWorker(in chan Request, out chan ParseResult, s Ready) {
go func() {
for {
s.WorkerReady(in) // 完成任务后,通知Scheduler当前Worker可用
request := <-in // 从Scheduler获取任务
result, err := e.RequestWorker(request) // 执行任务
if err != nil {
continue
}
out <- result // 返回任务执行结果
}
}()
}
Scheduler
type QueuedScheduler struct {
requestChan chan engine.Request // 接收Engine提交任务的通道
workerChan chan chan engine.Request // 派发任务给Worker的通道
}
func (s *QueuedScheduler) Submit(request engine.Request) {
s.requestChan <- request
}
func (s *QueuedScheduler) WorkerReady(w chan engine.Request) {
s.workerChan <- w
}
func (s *QueuedScheduler) GetWorkerChan() chan engine.Request {
return make(chan engine.Request)
}
func (s *QueuedScheduler) Run() {
s.requestChan = make(chan engine.Request)
s.workerChan = make(chan chan engine.Request)
go func() {
var requestQ []engine.Request // 任务队列
var workerQ []chan engine.Request // Worker队列
for {
var activeRequest engine.Request
var activeWorker chan engine.Request
if len(requestQ) > 0 && len(workerQ) > 0 {
activeRequest = requestQ[0]
activeWorker = workerQ[0]
}
select {
case r := <-s.requestChan:
// 若任务通道中有新任务,加入任务队列
requestQ = append(requestQ, r)
case w := <-s.workerChan:
// 若可用Worker通道中有新Worker,加入Worker队列
workerQ = append(workerQ, w)
case activeWorker <- activeRequest:
// 将任务队列中的首个元素派发给可用Worker队列中的首个元素
requestQ = requestQ[1:]
workerQ = workerQ[1:]
}
}
}()
}
Worker
func Worker(r Request) (ParseResult, error) {
body, err := fetcher.Fetch(r.Url)
if err != nil {
log.Error().Msgf("请求[%s]失败:%s", r.Url, err)
return ParseResult{}, err
}
return r.Parser.Parse(body, r.Url), nil
}
每个 Worker 运行在一个独立的 Goroutine 当中,读者需要根据实际爬取的网站来编写 Fetcher 和 Parser。
ItemSaver
ItemSaver 的任务就是将 Engine 通过 Channel 传送过来的 Item 持久化存储,读者可以根据自己的需求来实现 ItemSaver,将 Item 存储到 MySQL,MongoDB,ElasticSearch 等数据库。
分布式爬虫
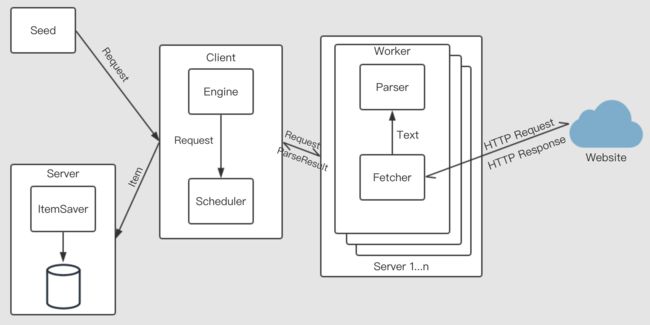
并发式版本虽然解决了单任务版本爬取效率低下的问题,但是在同一机器(同一 IP)上并发请求目标网站,很容易因为短时间内网络请求流量过大而被目标网站封禁。
分布式版本将 Worker 和 Saver 分离部署到不同的机器上,不同机器上的 Worker 使用不同 IP,不但能够解决 IP 封禁的问题,还能进一步提升爬取效率。
JSON-RPC
分布式系统需要通过网络交互数据,同步系统中的状态。本系统通过 JSON-RPC 同步各个节点中的状态,交互任务与任务执行结果。Go 语言标准库中的 net/rpc 包支持 JSON-RPC,可以通过交换 JSON 格式的数据来进行 RPC。
// 创建RPC服务器
func ServeRpc(host string, service interface{}) error {
rpc.Register(service)
listener, err := net.Listen("tcp", host)
if err != nil {
return err
}
for {
conn, err := listener.Accept()
if err != nil {
log.Printf("accept error: %v", err)
continue
}
go jsonrpc.ServeConn(conn)
}
return nil
}
// 创建RPC客户端
func NewClient(host string) (*rpc.Client, error) {
conn, err := net.Dial("tcp", host)
if err != nil {
return nil, err
}
return jsonrpc.NewClient(conn), nil
}
序列化与反序列化
系统中的各个节点在进行 JSON-RPC 之前,必须对需要发送的对象和函数序列,对接收的对象和函数反序列化。
type SerializedParser struct {
Name string
Args interface{}
}
type Request struct {
Url string
Parser SerializedParser
}
type ParseResult struct {
Items []engine.Item
Requests []Request
}
// 序列化请求对象
func SerializeRequest(r engine.Request) Request {
name, args := r.Parse.Serialize()
return Request{
Url: r.Url,
Parser: SerializedParser{
Name: name,
Args: args,
},
}
}
// 序列化结果对象
func SerializeResult(r engine.ParseResult) (p ParseResult) {
p.Items = r.Items
for _, req := range r.Requests {
p.Requests = append(p.Requests, SerializeRequest(req))
}
return p
}
// 反序列解析器
func deserializeParser(p SerializedParser) (engine.Parser, error) {
switch p.Name {
case "ParseCity":
return engine.NewFuncParser(parser.ParseCity, p.Name), nil
case "ParseCityList":
return engine.NewFuncParser(parser.ParseCityList, p.Name), nil
case "ProfileParser":
if userName, ok := p.Args.(string); ok {
return parser.NewProfileParser(userName), nil
} else {
return nil, errors.New("invalid args for profileParser")
}
case "NilParser":
return engine.NilParse{}, nil
default:
return nil, errors.New("unknown parser name")
}
}
// 反序列化请求
func DeserializeRequest(r Request) (engine.Request, error) {
parse, err := deserializeParser(r.Parser)
if err != nil {
return engine.Request{}, err
}
req := engine.Request{
Url: r.Url,
Parse: parse,
}
return req, nil
}
// 反序列化结果
func DeserializeResult(r ParseResult) engine.ParseResult {
result := engine.ParseResult{
Items: r.Items,
}
for _, req := range r.Requests {
ereq, err := DeserializeRequest(req)
if err != nil {
log.Warn().Msgf("error deserializing request: %v", err)
continue
}
result.Requests = append(result.Requests, ereq)
}
return result
}
连接池
分布式系统中维护着一个 Worker 连接池,Engine 通过连接池将请求任务派发到系统中的不同节点。
func createClientPool(hosts []string) chan *rpc.Client {
var clients []*rpc.Client
for _, h := range hosts {
client, err := rpcsupport.NewClient(h)
if err != nil {
log.Warn().Msgf("error connection to %s : %s", h, err)
} else {
clients = append(clients, client)
log.Warn().Msgf("connected to %s", h)
}
}
out := make(chan *rpc.Client)
go func() {
for {
for _, c := range clients {
out <- c
}
}
}()
return out
}