1.参照官网配置TiCDC 具体配置如下
# 指定配置文件中涉及的库名、表名是否为大小写敏感
# 该配置会同时影响 filter 和 sink 相关配置,默认为 true
case-sensitive = true
# 是否输出 old value,从 v4.0.5 开始支持
enable-old-value = true
[filter]
# 忽略指定 start_ts 的事务
ignore-txn-start-ts = [1, 2]
# 过滤器规则
# 过滤规则语法:https://docs.pingcap.com/zh/tidb/stable/table-filter#表库过滤语法 指定了我的销售表
rules = ['dspdev.sales_order_header']
[mounter]
# mounter 线程数,用于解码 TiKV 输出的数据
worker-num = 16
[sink]
# 对于 MQ 类的 Sink,可以通过 dispatchers 配置 event 分发器
# 支持 default、ts、rowid、table 四种分发器,分发规则如下:
# - default:有多个唯一索引(包括主键)时按照 table 模式分发;只有一个唯一索引(或主键)按照 rowid 模式分发;如果开启了 old value 特性,按照 table 分发
# - ts:以行变更的 commitTs 做 Hash 计算并进行 event 分发
# - rowid:以所选的 HandleKey 列名和列值做 Hash 计算并进行 event 分发
# - table:以表的 schema 名和 table 名做 Hash 计算并进行 event 分发
# matcher 的匹配语法和过滤器规则语法相同
dispatchers = [
{matcher = ['dspdev.*'], dispatcher = "ts"}
]
# 对于 MQ 类的 Sink,可以指定消息的协议格式
# 目前支持 default、canal、avro 和 maxwell 四种协议。default 为 TiCDC Open Protocol
protocol = "canal"
[cyclic-replication]
# 是否开启环形同步
enable = false
# 当前 TiCDC 的复制 ID
replica-id = 1
# 需要过滤掉的同步 ID
filter-replica-ids = [2,3]
# 是否同步 DDL
sync-ddl = true
2 cdc sink 配置下游为kafka
--sink-uri="kafka://127.0.0.1:9092/cdc-test?kafka-version=2.4.0&partition-num=6&max-message-bytes=67108864&replication-factor=1"
这样就会将tidb cdc 数据以protobuf数据发完kafka,我们只需要在下游做解析就好
具体配置解释参考:tidb配置连接
3 新建spring boot项目 引入 canal-client,kafka等配置
pom引入如下:
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.3.4.RELEASE
com.konka.dsp
kafka-parse
0.0.1-SNAPSHOT
kafka-parse
Demo project for Spring Boot
11
1.2.70
org.springframework.boot
spring-boot-starter
org.apache.kafka
kafka-streams
com.alibaba
fastjson
${fastjson.version}
com.alibaba.otter
canal.client
1.1.4
org.springframework.kafka
spring-kafka
org.springframework.boot
spring-boot-starter-test
test
org.junit.vintage
junit-vintage-engine
org.springframework.kafka
spring-kafka-test
test
org.springframework.boot
spring-boot-maven-plugin
properties 如下:
###########【Kafka集群】###########
spring.kafka.bootstrap-servers=192.168.8.71:9092
###########【初始化生产者配置】###########
# 重试次数
spring.kafka.producer.retries=0
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=1
# 批量大小
spring.kafka.producer.batch-size=16384
# 提交延时
spring.kafka.producer.properties.linger.ms=0
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
?
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 自定义分区器
# spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
###########【初始化消费者配置】###########
# 默认的消费组ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
# 提交offset延时(接收到消息后多久提交offset)
spring.kafka.consumer.auto.commit.interval.ms=1000
# 当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
# 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=com.alibaba.otter.canal.client.kafka.MessageDeserializer
# 消费端监听的topic不存在时,项目启动会报错(关掉)
spring.kafka.listener.missing-topics-fatal=false
#过滤table和字段
table.data = {"sales_order_header":"id,customer_name,total_amount,created_date"}
# 设置批量消费
# spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
sprint boot kafka 消费端代码如下:
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.serializer.SerializerFeature;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.FlatMessage;
import com.alibaba.otter.canal.protocol.Message;
import com.konka.dsp.kafkaparse.CanalKafkaClientExample;
import com.konka.dsp.kafkaparse.tidb.KafkaMessage;
import com.konka.dsp.kafkaparse.tidb.TicdcEventData;
import com.konka.dsp.kafkaparse.tidb.TicdcEventDecoder;
import com.konka.dsp.kafkaparse.tidb.TicdcEventFilter;
import com.konka.dsp.kafkaparse.tidb.value.TicdcEventDDL;
import com.konka.dsp.kafkaparse.tidb.value.TicdcEventResolve;
import com.konka.dsp.kafkaparse.tidb.value.TicdcEventRowChange;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Optional;
@Component
public class kafkaConsumer {
protected final static Logger logger = LoggerFactory.getLogger(CanalKafkaClientExample.class);
// 消费监听
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("#{${table.data}}")
private Map map;
@KafkaListener(topics = {"cdc-test"})
public void onMessage1(ConsumerRecord consumerRecord) throws UnsupportedEncodingException {
Message message = consumerRecord.value();
long batchId = message.getId();
FlatMessage fm = new FlatMessage();
List entrys = message.getEntries();
for (CanalEntry.Entry entry : entrys) {
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChage = null;
try {
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
fm.setId(entry.getHeader().getExecuteTime());
fm.setDatabase(entry.getHeader().getSchemaName());
fm.setEs(entry.getHeader().getExecuteTime());
fm.setTs(entry.getHeader().getExecuteTime());
fm.setTable(entry.getHeader().getTableName());
fm.setType(rowChage.getEventType().name());
CanalEntry.EventType eventType = rowChage.getEventType();
fm.setIsDdl(rowChage.getIsDdl());
fm.setSql(rowChage.getSql());
Map mysqlTypes = new HashMap<>();
Map sqlType = new HashMap<>();
List pkNames = new ArrayList<>();
logger.info(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
String[] filtercolumn = map.get(entry.getHeader().getTableName()).split(",");
logger.info(" filter --> column {}",filtercolumn);
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
fm.setData(saveRowData(rowData.getBeforeColumnsList(),pkNames,filtercolumn));
fm.setMysqlType(setMysqlTypes(rowData.getBeforeColumnsList(),filtercolumn));
fm.setSqlType(setSqlTypes(rowData.getBeforeColumnsList(),filtercolumn));
} else if (eventType == CanalEntry.EventType.INSERT) {
fm.setData(saveRowData(rowData.getAfterColumnsList(),pkNames,filtercolumn));
fm.setMysqlType(setMysqlTypes(rowData.getAfterColumnsList(),filtercolumn));
fm.setSqlType(setSqlTypes(rowData.getAfterColumnsList(),filtercolumn));
} else {
logger.info("-------> before->{}",rowData.getBeforeColumnsList().size());
fm.setOld(saveRowData(rowData.getBeforeColumnsList(),pkNames,filtercolumn));
logger.info("-------> after");
fm.setData(saveRowData(rowData.getAfterColumnsList(),pkNames,filtercolumn));
fm.setMysqlType(setMysqlTypes(rowData.getAfterColumnsList(),filtercolumn));
fm.setSqlType(setSqlTypes(rowData.getAfterColumnsList(),filtercolumn));
if(rowData.getBeforeColumnsList().size()==0&&rowData.getAfterColumnsList().size()>0){
fm.setType("INSERT");
}
}
}
HashSet h = new HashSet(pkNames);
pkNames.clear();
pkNames.addAll(h);
fm.setPkNames(pkNames);
}
logger.info("json解析:{}",JSON.toJSONString(fm, SerializerFeature.WriteMapNullValue));
kafkaTemplate.send("canal-data",JSON.toJSONString(fm, SerializerFeature.WriteMapNullValue));
//
// FlatMessage flatMessage = (FlatMessage)JSON.parseObject(flatMessageJson, FlatMessage.class);
// 消费的哪个topic、partition的消息,打印出消息内容
// KafkaMessage kafkaMessage = new KafkaMessage();
// kafkaMessage.setKey(consumerRecord.key());
// kafkaMessage.setValue(consumerRecord.value());
// kafkaMessage.setOffset(consumerRecord.offset());
// kafkaMessage.setPartition(consumerRecord.partition());
// kafkaMessage.setTimestamp(consumerRecord.timestamp());
// TicdcEventFilter filter = new TicdcEventFilter();
// TicdcEventDecoder ticdcEventDecoder = new TicdcEventDecoder(kafkaMessage);
// while (ticdcEventDecoder.hasNext()) {
// TicdcEventData data = ticdcEventDecoder.next();
// if (data.getTicdcEventValue() instanceof TicdcEventRowChange) {
// boolean ok = filter.check(data.getTicdcEventKey().getTbl(), data.getTicdcEventValue().getKafkaPartition(), data.getTicdcEventKey().getTs());
// if (ok) {
// // deal with row change event
// } else {
// // ignore duplicated messages
// }
// } else if (data.getTicdcEventValue() instanceof TicdcEventDDL) {
// // deal with ddl event
// } else if (data.getTicdcEventValue() instanceof TicdcEventResolve) {
// filter.resolveEvent(data.getTicdcEventValue().getKafkaPartition(), data.getTicdcEventKey().getTs());
// // deal with resolve event
// }
// System.out.println(JSON.toJSONString(data, true));
// }
}
private List> saveRowData(List columns,List pkNames,String[] filter) {
Map map = new HashMap<>();
List> rowdata = new ArrayList<>();
columns.forEach(column -> {
if(column.hasIsKey()){
pkNames.add(column.getName());
}
if(Arrays.asList(filter).contains(column.getName())){
map.put(column.getName(),column.getValue().equals("")?"NULL":column.getValue());
}
//防止flink接收""报错
});
rowdata.add(map);
return rowdata;
// rabbitTemplate.convertAndSend(tableEventType.toUpperCase(),JSON.toJSONString(map));
}
private Map setMysqlTypes(List columns,String[] filter){
Map map = new HashMap<>();
columns.forEach(column -> {
if(Arrays.asList(filter).contains(column.getName())){
map.put(column.getName(),column.getMysqlType());
}
});
return map;
}
private Map setSqlTypes(List columns,String[] filter){
Map map = new HashMap<>();
columns.forEach(column -> {
if(Arrays.asList(filter).contains(column.getName())){
map.put(column.getName(),column.getSqlType());
}
});
return map;
}
private static void printColumn(List columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
这里基本上将 tidb的数据转化为canal-json格式数据,这里我们继续将转化后的数据发完kafka,以便kafka 继续消费,这里有个点就是不知道为什么tidb出来的insert和update eventtype类型都是UPDATE,所以我在代码做了判断没有OLD的话基本上就是INSERT了
4.flink 本地开发 建议下载搭建好环境参考flink table 配置
具体参考官网
flinktable配置
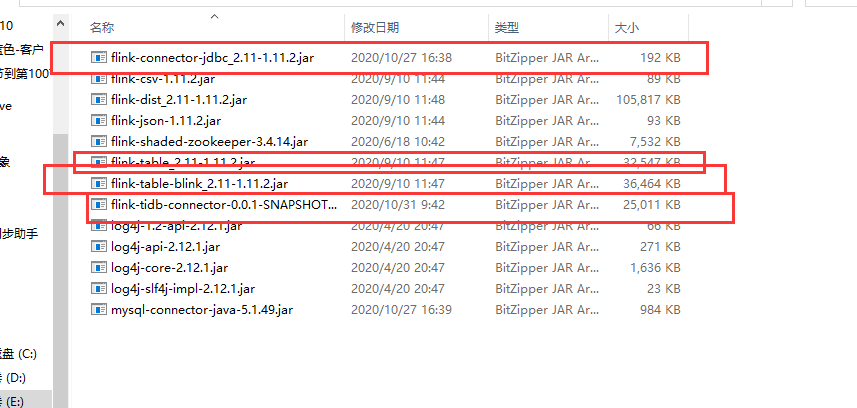
把table相关jar包拷贝到flink下的lib目录下即可
这里的会用到另外一个知乎开源的相关包项目地址如下: https://github.com/pingcap-incubator/TiBigData/
把项目编译完成以后把flink相关jar包拷贝到flink下的lib下
image
5 最后在我们的相关业务库配置表这里我上代码了:
import org.apache.flink.api.java.DataSet;
import org.apache.flink.table.api.*;
import org.apache.flink.table.expressions.TimeIntervalUnit;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.*;
public class SalesOrderStream {
public static Table report(Table transactions) {
return transactions.select(
$("customer_name"),
$("created_date"),
$("total_amount"))
.groupBy($("customer_name"), $("created_date"))
.select(
$("customer_name"),
$("total_amount").sum().as("total_amount"),
$("created_date")
);
}
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
// tEnv.executeSql("CREATE TABLE sales_order_header_stream (\n" +
//// " id BIGINT not null,\n" +
// " customer_name STRING,\n"+
//// " dsp_org_name STRING,\n"+
// " total_amount DECIMAL(38,2),\n" +
//// " total_discount DECIMAL(16,2),\n" +
//// " pay_amount DECIMAL(16,2),\n" +
//// " total_amount DECIMAL(16,2),\n" +
// " created_date TIMESTAMP(3)\n" +
// ") WITH (\n" +
// " 'connector' = 'mysql-cdc',\n" +
// " 'hostname' = '192.168.8.73',\n" +
// " 'port' = '4000',\n"+
// " 'username' = 'flink',\n"+
// " 'password' = 'flink',\n"+
// " 'database-name' = 'dspdev',\n"+
// " 'table-name' = 'sales_order_header'\n"+
// ")");
tEnv.executeSql("CREATE TABLE sales_order_header_stream (\n" +
" `id` BIGINT,\n"+
" `total_amount` DECIMAL(16,2) ,\n"+
" `customer_name` STRING,\n"+
" `created_date` TIMESTAMP(3) ,\n"+
" PRIMARY KEY (`id`) NOT ENFORCED "+
") WITH (\n" +
"'connector' = 'kafka',\n"+
"'topic' = 'canal-data',\n"+
"'properties.bootstrap.servers' = '192.168.8.71:9092',\n"+
"'properties.group.id' = 'test',\n"+
"'scan.startup.mode' = 'earliest-offset',\n"+
"'format' = 'canal-json'\n"+
")");
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" customer_name STRING,\n" +
// " total_amount DECIMAL(16,2),\n" +
// " total_discount DECIMAL(16,2),\n" +
// " pay_amount DECIMAL(16,2),\n" +
" total_amount DECIMAL(16,2),\n" +
" created_date TIMESTAMP(3),\n" +
" PRIMARY KEY (customer_name,created_date) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'tidb',\n" +
" 'tidb.database.url' = 'jdbc:mysql://192.168.8.73:4000/dspdev',\n" +
" 'tidb.username' = 'flink',\n"+
" 'tidb.password' = 'flink',\n"+
" 'tidb.database.name' = 'dspdev',\n"+
" 'tidb.table.name' = 'spend_report'\n"+
")");
Table transactions = tEnv.from("sales_order_header_stream");
report(transactions).executeInsert("spend_report");
}
}
这样在我数据库里面就可以实时统计当前的销售总价并写入数据库里,最后数据库数据如下:

image
以上就是机遇TIDB体系进行的数据实时统计