上一篇,什么是倒排索引以及原理是什么。本篇讲解 Analyzer,了解 Analyzer 是什么 ,分词器是什么,以及 Elasticsearch 内置的分词器,最后再讲解中文分词是怎么做的。
一、Analysis 与 Analyzer
Analysis 文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词
,Analysis 是通过 Analyzer 来实现的。 Elasticsearch 有多种 内置的分析器,如果不满足也可以根据自己的需求定制化分析器,除了在数据写入时转换词条,匹配 Query 语句时候也需要用相同的分析器对查询语句进行分析。
二、Analyzer 的组成
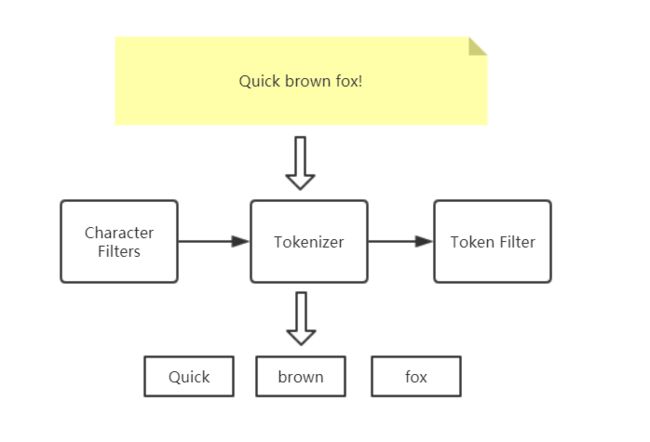
- Character Filters (针对原始文本处理,例如,可以使用字符过滤器将印度阿拉伯数字(٠ ١٢٣٤٥٦٧٨ ٩)转换为其等效的阿拉伯语-拉丁语(0123456789))
- Tokenizer(按照规则切分为单词),将把文本 "Quick brown fox!" 转换成 terms [Quick, brown, fox!],tokenizer 还记录文本单词位置以及偏移量。
- Token Filter(将切分的的单词进行加工、小写、刪除 stopwords,增加同义词)
三、Analyzer 内置的分词器
例子:The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
Standard Analyzer
- 默认分词器
- 按词分类
- 小写处理
#standard
GET _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[the,2,quick,brown,foxes,a,jumped,over,the,lazy,dog's,bone]
Simple Analyzer
- 按照非字母切分,非字母则会被去除
- 小写处理
#simpe
GET _analyze
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[the,quick,brown,foxes,jumped,over,the,lazy,dog,s,bone]
Stop Analyzer
- 小写处理
- 停用词过滤(the,a, is)
GET _analyze
{
"analyzer": "stop",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[quick,brown,foxes,jumped,over,lazy,dog,s,bone]
Whitespace Analyzer
- 按空格切分
#stop
GET _analyze
{
"analyzer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[The,2,QUICK,Brown-Foxes,jumped,over,the,lazy,dog's,bone.]
Keyword Analyzer
- 不分词,当成一整个 term 输出
#keyword
GET _analyze
{
"analyzer": "keyword",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.]
Patter Analyzer
- 通过正则表达式进行分词
- 默认是 \W+(非字母进行分隔)
GET _analyze
{
"analyzer": "pattern",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[the,2,quick,brown,foxes,jumped,over,the,lazy,dog,s,bone]
Language Analyzer
支持语言:arabic, armenian, basque, bengali, bulgarian, catalan, czech, dutch, english, finnish, french, galician, german, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, portuguese, romanian, russian, sorani, spanish, swedish, turkish.
#english
GET _analyze
{
"analyzer": "english",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[2,quick,brown,fox,jump,over,the,lazy,dog,bone]
中文分词要比英文分词难,英文都以空格分隔,中文理解通常需要上下文理解才能有正确的理解,比如 [苹果,不大好吃]和
[苹果,不大,好吃],这两句意思就不一样。
ICU Analyzer
ElasticSearch 默认以每个字对中文分隔,无法满足我们的需求。ICU Analyzer 使用国际化组件 Unicode (ICU) 函数库提供丰富的处理 Unicode ,更好支持中文分词,ICU Analyzer 不是默认分词器,需要先安装插件,安装命令 sudo bin/elasticsearch-plugin install analysis-icu。
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理”"
}
输出:
[他,说的,确实,在,理]
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
输出:
[他,说,的,确,实,在,理]
ICU 只是其中一种中文分词器,在 Github 上可以查找到其他中文分词器,比如 IK,THULAC,这些就不在这里提及,有兴趣可以自行了解。
四、总结
本篇对 Analyzer 进行详细讲解,ES 内置分词器是如何工作的,通过 ICU Analyzer 对中文分词的效果,下面总结内置的所有分词器的特点,做一个简单对比。
Standard Analyzer -- 默认分词器,按词切分,小写处理
Simple Analyzer -- 按照非字母切分(符号被过滤),小写处理
Stop Analyzer -- 小写处理,停用词过滤(the,a, is)
Whitespace Analyzer -- 按照空格切分,不转小写
Keyword Analyzer -- 不分词,直接将输入当作输出
Patter Analyzer -- 正则表达式,默认\W+ (非字符分隔)
Language Analyzer -- 提供了 30 多种常见语言的分词器
Customer Analyzer -- 自定义分词器
【Elasticsearch 7 探索之路】(三)倒排索引
【Elasticsearch 7 探索之路】(二)文档的 CRUD 和批量操作
【Elasticsearch 7 搜索之路】(一)什么是 Elasticsearch?