原文地址
一、聚类思想
所谓聚类算法是指将一堆没有标签的数据自动划分成几类的方法,属于无监督学习方法,这个方法要保证同一类的数据有相似的特征,如下图所示:

根据样本之间的距离或者说是相似性(亲疏性),把越相似、差异越小的样本聚成一类(簇),最后形成多个簇,使同一个簇内部的样本相似度高,不同簇之间差异性高。
二、k-means聚类分析算法
相关概念:
K值:要得到的簇的个数
质心:每个簇的均值向量,即向量各维取平均即可
距离量度:常用欧几里得距离和余弦相似度(先标准化)

算法流程:
1、首先确定一个k值,即我们希望将数据集经过聚类得到k个集合。
2、从数据集中随机选择k个数据点作为质心。
3、对数据集中每一个点,计算其与每一个质心的距离(如欧式距离),离哪个质心近,就划分到那个质心所属的集合。
4、把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。
5、如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终止。
6、如果新质心和原质心距离变化很大,需要迭代3~5步骤。
三、数学原理

K-Means采用的启发式方式很简单,用下面一组图就可以形象的描述:

上图a表达了初始的数据集,假设k=2。在图b中,我们随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别,如图c所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。此时我们对我们当前标记为红色和蓝色的点分别求其新的质心,如图d所示,新的红色质心和蓝色质心的位置已经发生了变动。图e和图f重复了我们在图c和图d的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如图f。
四、实例
坐标系中有六个点:

1、我们分两组,令K等于2,我们随机选择两个点:P1和P2
2、通过勾股定理计算剩余点分别到这两个点的距离:

3、第一次分组后结果:
组A:P1
组B:P2、P3、P4、P5、P6
4、分别计算A组和B组的质心:
A组质心还是P1=(0,0)
B组新的质心坐标为:P哥=((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)
5、再次计算每个点到质心的距离:

6、第二次分组结果:
组A:P1、P2、P3
组B:P4、P5、P6
7、再次计算质心:
P哥1=(1.33,1)
P哥2=(9,8.33)
8、再次计算每个点到质心的距离:
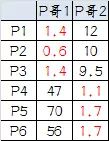
9、第三次分组结果:
组A:P1、P2、P3
组B:P4、P5、P6
可以发现,第三次分组结果和第二次分组结果一致,说明已经收敛,聚类结束。
五、K-Means的优缺点
优点:
1、原理比较简单,实现也是很容易,收敛速度快。
2、当结果簇是密集的,而簇与簇之间区别明显时, 它的效果较好。
3、主要需要调参的参数仅仅是簇数k。
缺点:
1、K值需要预先给定,很多情况下K值的估计是非常困难的。
2、K-Means算法对初始选取的质心点是敏感的,不同的随机种子点得到的聚类结果完全不同 ,对结果影响很大。
3、对噪音和异常点比较的敏感。用来检测异常值。
4、采用迭代方法,可能只能得到局部的最优解,而无法得到全局的最优解。
六、细节问题
1、K值怎么定?
答:分几类主要取决于个人的经验与感觉,通常的做法是多尝试几个K值,看分成几类的结果更好解释,更符合分析目的等。或者可以把各种K值算出的E做比较,取最小的E的K值。
2、初始的K个质心怎么选?
答:最常用的方法是随机选,初始质心的选取对最终聚类结果有影响,因此算法一定要多执行几次,哪个结果更reasonable,就用哪个结果。 当然也有一些优化的方法,第一种是选择彼此距离最远的点,具体来说就是先选第一个点,然后选离第一个点最远的当第二个点,然后选第三个点,第三个点到第一、第二两点的距离之和最小,以此类推。第二种是先根据其他聚类算法(如层次聚类)得到聚类结果,从结果中每个分类选一个点。
3、关于离群值?
答:离群值就是远离整体的,非常异常、非常特殊的数据点,在聚类之前应该将这些“极大”“极小”之类的离群数据都去掉,否则会对于聚类的结果有影响。但是,离群值往往自身就很有分析的价值,可以把离群值单独作为一类来分析。
4、单位要一致!
答:比如X的单位是米,Y也是米,那么距离算出来的单位还是米,是有意义的。但是如果X是米,Y是吨,用距离公式计算就会出现“米的平方”加上“吨的平方”再开平方,最后算出的东西没有数学意义,这就有问题了。
5、标准化
答:如果数据中X整体都比较小,比如都是1到10之间的数,Y很大,比如都是1000以上的数,那么,在计算距离的时候Y起到的作用就比X大很多,X对于距离的影响几乎可以忽略,这也有问题。因此,如果K-Means聚类中选择欧几里德距离计算距离,数据集又出现了上面所述的情况,就一定要进行数据的标准化(normalization),即将数据按比例缩放,使之落入一个小的特定区间。