什么是伙伴堆算法
伙伴堆算法(也叫伙伴系统,buddy system)是Linux系统中的一种动态的内存管理算法
伙伴堆算法的用途
每当分配和释放内存的时候系统都将遇到尾部碎片的问题,比如当请求一个页面的时候,即使系统可用页面总数足够多,但是无法分配大块连续的页面。也就是说可用页面会被一个或多个不连续的不可用页面拆开。使用伙伴算法就可以一定程度解决这种页面碎片的问题。
算法基本思想
Linux把所有的空闲页框分组为11个块链表,每个链表上的页框块是固定的。在第i条链表中每个页框块都包含2的i次方个连续页,其中i称为分配阶。
下面以一个例子,讲述伙伴算法的思想:假设要申请一个256个页,先从256个页框的链表中查找空闲块,如果没有,就去512个页框的链表中找,找到了则将页框块分为2个256个页框的块,一个分配给应用,另外一个移到256个页框的链表中。如果512个页框的链表中仍没有空闲块,继续向1024个页框的链表查找。如果1024块存在,则将其中的256页框作为请求返回,剩余的768分成256块和512块分别插到相应的链表中。如果仍然没有,则返回错误。
算法涉及的数据结构
Linux中伙伴堆算法的核心数据结构包含以下两个部分
1.free_area
//在mmzone.h中
#define MAX_ORDER 11
struct zone
{
... ...
struct free_area free_area[MAX_ORDER];
... ...
};
每个物理内存节点上都可以划分为不同的zone,划分zone的原因是因为X86的一些架构的影响(这一部分不是本文关键),因此可以理解为zone就是一块内存的管理符,其中有一个很重要的数据就是free_area,并且它是一个结构体数组,具体定义如下。
//在mmzone.h中
struct free_area
{
struct list_head free_list[MIGRATR_TYPES];//说明了页的属性
unsigned long nr_free;//来说明每个界中有多少可用的页
};
在这个结构体中有两个域,第一个是free_list,是个链表,它表示的就是当前分配阶所对应的页框块的链表。第二个nr_free指的是当前链表中空闲页框块的数目,比如free_area[2]中nr_free的值为5,表示有5个大小为4的页框块,那么总的空闲页为20.其具体结构可见下面两幅图
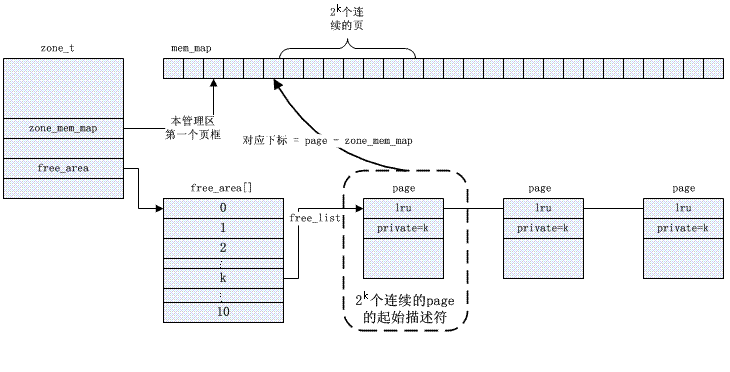
这张图很好的说明了zone的结构体中包含以分free_area字段并且free_area是一个数组后面用链表的形式附加了各种大小的页面对于zone中另一个比较重要的结构mem_map结构在稍后进行说明。free_area的具体实现见下图。

对应数组下标为i的位置连接一些大小为2的i次幂大小的空闲页面,并通过双向链表的形式组织起来,nr_free的值为链表中空闲页面的个数。
2. zone_mem_map数组
zone_mem_map是用于查找连续伙伴空间用的伙伴位图。用一位描述伙伴块的状态位码,称之为伙伴位码。比如,bit0为第0块和第1块的伙伴位码,如果bit0为1,表示这两块至少有一块已经分配出去,如果bit0为0,说明两块都空闲,还没分配。整个内存释放或者分配过程中,位图扮演了重要的角色。
内存分配与释放得原理
分配原理:假如系统需要4(2 * 2)个页面大小的内存块,该算法就到free_area[2]中查找,如果链表中有空闲块,就直接从中摘下并分配出去。如果没有,算法将顺着数组向上查找free_area[3],如果free_area[3]中有空闲块,则将其从链表中摘下,分成等大小的两部分,前四个页面作为一个块插入free_area[2],后4个页面分配出去,free_area[3]中也没有,就再向上查找,如果free_area[4]中有,就将这16(2 * 2 * 2 * 2)个页面等分成两份,前一半挂如free_area[3]的链表头部,后一半的8个页等分成两等分,前一半挂free_area[2]的链表中,后一半分配出去。假如free_area[4]也没有,则重复上面的过程,知道到达free_area数组的最后,如果还没有则放弃分配。
释放原理:内存的释放是分配的逆过程,也可以看作是伙伴的合并过程。当释放一个块时,先在其对应的链表中考查是否有伙伴存在,如果没有伙伴块,就直接把要释放的块挂入链表头;如果有,则从链表中摘下伙伴,合并成一个大块,然后继续考察合并后的块在更大一级链表中是否有伙伴存在,直到不能合并或者已经合并到了最大的块(2 * 2 * 2 * 2 * 2 * 2 * 2 * 2 * 2个页面)。整个过程中,位图扮演了重要的角色,位图的某一位对应两个互为伙伴的块,为1表示其中一块已经分配出去了,为0表示两块都空闲。伙伴中无论是分配还是释放都只是相对的位图进行异或操作。分配内存时对位图的是为释放过程服务,释放过程根据位图判断伙伴是否存在,如果对相应位的异或操作得1,则没有伙伴可以合并,如果异或操作得0,就进行合并,并且继续按这种方式合并伙伴,直到不能合并为止。
内存分配与释放的例子
下面通过一个例子,来深入地理解一下伙伴算法的真正内涵(下面这个例子并不严格表示Linux 内核中的实现,是阐述伙伴算法的实现思想):
假设系统中有 1MB 大小的内存需要动态管理,按照伙伴算法的要求:需要将这1M大小的内存进行划分。这里,我们将这1M的内存分为 64K、64K、128K、256K、和512K 共五个部分,如下图 a 所示

1.此时,如果有一个程序A想要申请一块45K大小的内存,则系统会将第一块64K的内存块分配给该程序(产生内部碎片为代价),如图b所示;
2.然后程序B向系统申请一块68K大小的内存,系统会将128K内存分配给该程序,如图c所示;
3.接下来,程序C要申请一块大小为35K的内存。系统将空闲的64K内存分配给该程序,如图d所示;
4.之后程序D需要一块大小为90K的内存。当程序提出申请时,系统本该分配给程序D一块128K大小的内存,但此时内存中已经没有空闲的128K内存块了,于是根据伙伴算法的原理,系统会将256K大小的内存块平分,将其中一块分配给程序D,另一块作为空闲内存块保留,等待以后使用,如图e所示;
5.紧接着,程序C释放了它申请的64K内存。在内存释放的同时,系统还负责检查与之相邻并且同样大小的内存是否也空闲,由于此时程序A并没有释放它的内存,所以系统只会将程序C的64K内存回收,如图f所示;
6.然后程序A也释放掉由它申请的64K内存,系统随机发现与之相邻且大小相同的一段内存块恰好也处于空闲状态。于是,将两者合并成128K内存,如图g所示;
7.之后程序B释放掉它的128k,系统也将这块内存与相邻的128K内存合并成256K的空闲内存,如图h所示;
8.最后程序D也释放掉它的内存,经过三次合并后,系统得到了一块1024K的完整内存,如图i所示。
buddy算法的优缺点
优点
1.解决内存碎片问题
2.避免把内存拆得太碎得同时,使内存的分配和释放过程迅速
缺点
1.虽然解决了内存碎片问题,但是该算法中,一个很小的块往往会阻碍一个大块的合并。(一片内存中仅一个小的内存块没有释放,旁边两个大的就不能合并。)
2.算法中有一定的浪费现象,伙伴算法是按2的幂次方大小进行分配内存块。
3.另外拆分和合并涉及到 较多的链表和位图操作,开销还是比较大的。
reference
[1].https://www.cnblogs.com/alantu2018/p/8527821.html
[2].https://www.cnblogs.com/cherishui/p/4246133.html
[3].https://blog.csdn.net/yq272393925/article/details/89286963
[4].https://www.cnblogs.com/huhuuu/p/3598760.html
[5].https://blog.csdn.net/qq_22238021/article/details/80208630
总结
文章写的并不全,包括位图具体得算法,linux内存池中的具体实现也都暂时没看完,以及优缺点总结并不全面。水平有限,暂时也就先这样吧。等我啥时候明白了我再更好了。Linux这种东西还是要多看几遍得