https://blog.csdn.net/sinat_42239797/article/details/90641659
#***************************一些必要的包的调用********************************
import torch.nn.functional as F
import torch
import torch
import torch.nn as nn
from torch.autograd import Variable
import torchvision.models as models
from torchvision import transforms, utils
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import numpy as np
import torch.optim as optim
import os
#***************************初始化一些函数********************************
#torch.cuda.set_device(gpu_id)#使用GPU
learning_rate = 0.0001#学习率的设置
#*************************************数据集的设置****************************************************************************
root =os.getcwd()+"\\"#数据集的地址
#定义读取文件的格式
def default_loader(path):
return Image.open(path).convert('RGB')
class MyDataset(Dataset):
#创建自己的类: MyDataset,这个类是继承的torch.utils.data.Dataset
#********************************** #使用__init__()初始化一些需要传入的参数及数据集的调用**********************
def __init__(self,txt, transform=None,target_transform=None, loader=default_loader):
super(MyDataset,self).__init__()
imgs = []
#对继承自父类的属性进行初始化
fh = open(txt, 'r')
#按照传入的路径和txt文本参数,以只读的方式打开这个文本
for line in fh: #迭代该列表#按行循环txt文本中的内
line = line.strip('\n')
line = line.rstrip('\n')
# 删除 本行string 字符串末尾的指定字符,这个方法的详细介绍自己查询python
words = line.split()
#用split将该行分割成列表 split的默认参数是空格,所以不传递任何参数时分割空格
imgs.append((words[0],int(words[1])))
#把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定
# 很显然,根据我刚才截图所示txt的内容,words[0]是图片信息,words[1]是lable
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
#*************************** #使用__getitem__()对数据进行预处理并返回想要的信息**********************
def __getitem__(self, index):#这个方法是必须要有的,用于按照索引读取每个元素的具体内容
fn, label = self.imgs[index]
#fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息
img = self.loader(fn)
# 按照路径读取图片
if self.transform is not None:
img = self.transform(img)
#数据标签转换为Tensor
return img,label
#return回哪些内容,那么我们在训练时循环读取每个batch时,就能获得哪些内容
#********************************** #使用__len__()初始化一些需要传入的参数及数据集的调用**********************
def __len__(self):
#这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return len(self.imgs)
train_data=MyDataset(txt=root+'train.txt', transform=transforms.ToTensor())
test_data = MyDataset(txt=root+'text.txt', transform=transforms.ToTensor())
#然后就是调用DataLoader和刚刚创建的数据集,来创建dataloader,这里提一句,loader的长度是有多少个batch,所以和batch_size有关
train_loader = DataLoader(dataset=train_data, batch_size=32, shuffle=True,num_workers=0)
test_loader = DataLoader(dataset=test_data, batch_size=32, shuffle=False,num_workers=0)
print('num_of_trainData:', len(train_loader))
print('num_of_testData:', len(test_loader))
要使用上面的代码,首先要制作供调用的txt文件,我的文件夹里面的内容是这样的
我的文件夹.JPG
train里面的数据如下,一共10类,10个数字,我预先resize成224x224
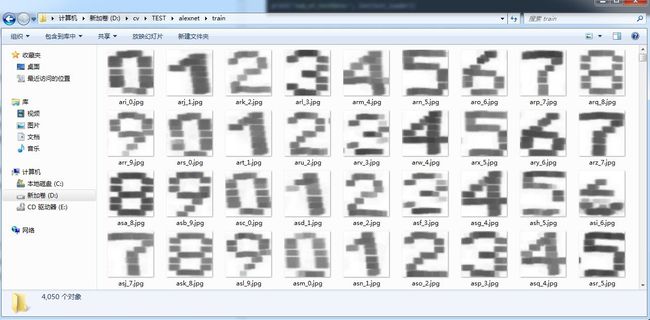
train文件夹.JPG
用的制作txt的代码如下
import os
dir = 'D:/cv/TEST/alexnet/test/'#图片文件的地址
#os.listdir的结果就是一个list集,可以使用list的sort方法来排序。如果文件名中有数字,就用数字的排序
files = os.listdir(dir)#列出dirname下的目录和文件
files.sort()#排序
text = open('./text.txt', 'a')
for file in files:
label = file.split('.')[0].split('_')[-1]
name = str(dir) +file + ' ' + label +'\n'
text.write(name)
text.close()
dir = 'D:/cv/TEST/alexnet/train/'#图片文件的地址
#os.listdir的结果就是一个list集,可以使用list的sort方法来排序。如果文件名中有数字,就用数字的排序
files = os.listdir(dir)#列出dirname下的目录和文件
files.sort()#排序
train = open('./train.txt','a')
for file in files:
label = file.split('.')[0].split('_')[-1]
name = str(dir) +file + ' ' + label +'\n'
train.write(name)
train.close()
dir = 'D:/cv/TEST/alexnet/vaild/'#图片文件的地址
#os.listdir的结果就是一个list集,可以使用list的sort方法来排序。如果文件名中有数字,就用数字的排序
files = os.listdir(dir)#列出dirname下的目录和文件
files.sort()#排序
vaild = open('./vaild.txt','a')
for file in files:
label = file.split('.')[0].split('_')[-1]
name = str(dir) +file + ' ' + label +'\n'
vaild.write(name)
vaild.close()
用的是官网的模型,没有想到pytorch做模型怎么简单
https://pytorch.org/docs/master/_modules/torchvision/models/alexnet.html#alexnet
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
net = AlexNet()
net.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
"""
###画图
import matplotlib.pyplot as plt
import numpy as np
import torchvision
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(train_loader)
images, labels = dataiter.next()
# show images
print(images[0])
imshow(torchvision.utils.make_grid(images[0]))
# print labels
print(' '.join('%5s' % labels[j] for j in range(32)))
###画图结束
"""
# 训练网络
# 迭代epoch
for epoch in range(30):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# get the input
inputs, labels = data
# zeros the paramster gradients
optimizer.zero_grad() #
# print(inputs)
# forward + backward + optimize
outputs = net(inputs.cuda())
loss = criterion(outputs, labels.cuda()) # 计算loss
#print(outputs,labels)
loss.backward() # loss 求导
optimizer.step() # 更新参数
# print statistics
running_loss += loss.item() # tensor.item() 获取tensor的数值
if i % 50 == 49:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 5)) # 每2000次迭代,输出loss的平均值
running_loss = 0.0
print('Finished Training')
# 保存
torch.save(net, 'model.pth')
def evaluteTop1(model, loader):
model.eval()
correct = 0
total = len(loader.dataset)
for x,y in loader:
x,y = x.cuda(), y.cuda()
with torch.no_grad():
logits = model(x)
pred = logits.argmax(dim=1)
correct += torch.eq(pred, y).sum().float().item()
#correct += torch.eq(pred, y).sum().item()
return correct / total
model = AlexNet()
model = torch.load('model.pth')
print(evaluteTop1(model,test_loader))
"""
###错误的图片,要上面的imshow代码
#net.eval()
eval_loss = 0.
eval_acc = 0.
errorimg = []
for i, data in enumerate(test_loader, 0):
inputs, labels = data
outputs = model(inputs.cuda())
pred = torch.max(outputs, 1)[1]
for i in range(len(labels)):
if labels[i] != pred[i]:
errorimg.append(inputs[i])
imshow(torchvision.utils.make_grid(errorimg))
###
"""
图片及处理代码和很潦草的jupyter文件
链接: https://pan.baidu.com/s/19sA7brPbKbv9tPByuY2Rkw 提取码: t2ih 复制这段内容后打开百度网盘手机App,操作更方便哦
训练出的模型
链接: https://pan.baidu.com/s/1WAevnAAJA8J5JHWaStJ_NQ 提取码: b9we