Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Windows 安装
升级pip版本:pip install --upgrade pip
通过pip 安装 Scrapy 框架pip install scrapy
Ubuntu 需要9.10或以上版本/Mac安装方式
安装非Python的依赖 sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip 安装 Scrapy 框架 sudo pip install scrapy
安装后,只要在命令终端输入 scrapy,提示类似以下结果,代表已经安装成功

具体Scrapy安装流程参考: http://doc.scrapy.org/en/latest/intro/install.html#intro-install-platform-notes 里面有各个平台的安装方法
scrapy项目结构
新建项目(scrapy startproject)
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider

其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
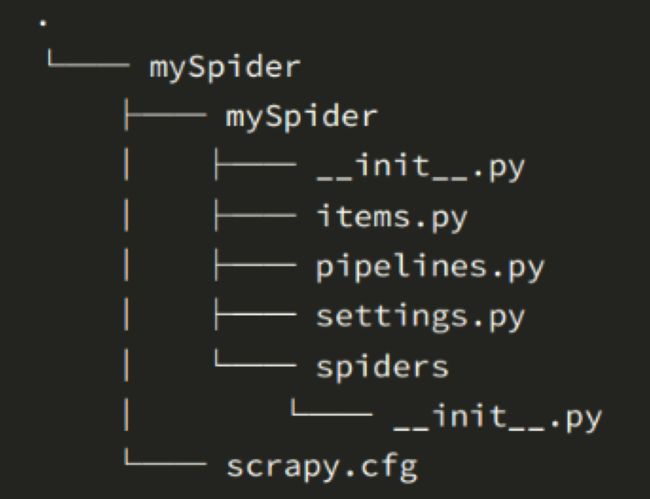
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
入门案例
创建一个Scrapy项目
定义提取的结构化数据(Item)
编写爬取网站的 Spider 并提取出结构化数据(Item)
编写 Item Pipelines 来存储提取到的Item(即结构化
我要完成https://movie.douban.com/top250信息的爬取
新建项目(scrapy startproject)
在命令行中执行
scrapy startproject douban
明确目标(mySpider/items.py)
我们打算抓取:https://movie.douban.com/top250信息
打开douban目录下的items.py
Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item。
接下来,创建一个DoubanItem 类和构建item模型(model)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序号
serial_number = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 电影介绍
introduce = scrapy.Field()
# 电影星级
star = scrapy.Field()
# 电影的评价
evalute = scrapy.Field()
# 电影的描述
describe = scrapy.Field()
pass

制作爬虫
爬虫功能要分两步:
- 爬数据
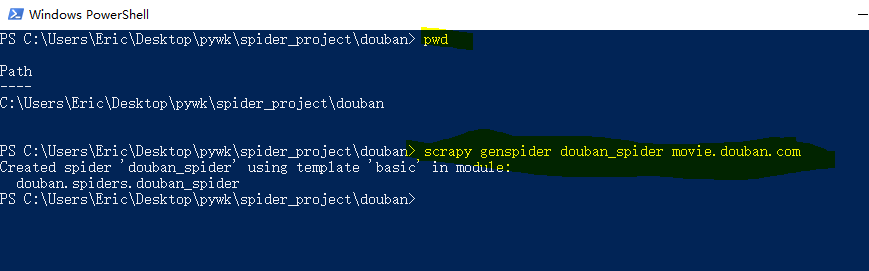
在当前目录下输入命令,将在mySpider/spider目录下创建一个名为的爬虫,并指定爬取域的范围:
scrapy genspider douban_spider movie.douban.com
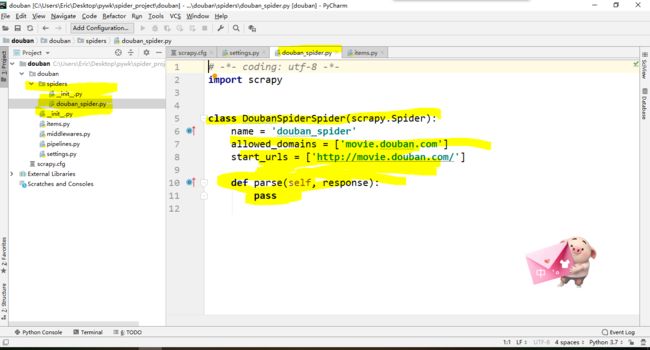
打开 douban/spiders目录里的douban_spider.py,默认增加了下列代码:
# -*- coding: utf-8 -*-
import scrapy
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/']
def parse(self, response):
pass
其实也可以由我们自行创建douban_spider.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = "" :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = () :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
生成需要下一页的URL请求。
修改parse()方法
def parse(self, response):
print(response.text)
with open('douban.html', 'w',encoding='utf-8') as f:
f.write(response.text)
# douban_spider 就是name的名称
scrapy crawl douban_spider
是的,就是 douban_spider,看上面代码,它是 DoubanSpiderSpider类的 name 属性,也就是使用 scrapy genspider命令的爬虫名。
一个Scrapy爬虫项目里,可以存在多个爬虫。各个爬虫在执行时,就是按照 name 属性来区分。
运行之后,如果打印的日志出现 [scrapy] INFO: Spider closed (finished),代表执行完成。 之后当前文件夹中就出现了一个 douban.html 文件,里面就是我们刚刚要爬取的网页的全部源代码信息。
取数据
- 爬取整个网页完毕,接下来的就是的取过程了,首先观察页面源码
是不是一目了然?直接上XPath开始提取数据吧。
我们之前在douban/items.py 里定义了一个DoubanItem类。 这里引入进来,然后添加如下代码
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
# 继承scrapy.Spider,这里是爬虫名字,不能和项目名字重复
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口 url,扔到调度器里面
# start_urls = ['http://movie.douban.com/']
start_urls = ['https://movie.douban.com/top250']
# 默认解析方法
def parse(self, response):
movie_list = response.xpath('//div[@id="content"]//ol/li')
print(len(movie_list))
for i_item in movie_list:
douban_item = DoubanItem()
# 爬取序号
douban_item['serial_number'] = i_item.xpath('./div[@class="item"]/div[@class="pic"]/em/text()').extract_first()
# 爬取电影名称
douban_item['movie_name'] = i_item.xpath('./div[@class="item"]/div[@class="info"]/div[@class="hd"]/a/span[1]/text()').extract_first()
# 电影内容
# 解析数据,而不是第一个
content = i_item.xpath('.//div[@class="bd"]/p[1]/text()').extract()
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
# 电影星级
douban_item['star'] = i_item.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[2]/text()').extract_first()
# 电影的评价
evalute = i_item.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[4]/text()').extract_first()
douban_item['evalute'] = evalute.replace('人评价', '')
# 电影的描述
douban_item['describe'] = i_item.xpath('./div[@class="item"]/div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[@class="inq"]/text()').extract_first()
print(douban_item)
# 不进行 yield 无法进入 pipelines 里面,将获取的数据交给pipelines
yield douban_item
#解析下一页
next_link = response.xpath('//span[@class="next"]/link/@href').extract()
# 如果有就一直取下一页
if next_link:
next_link=next_link[0]
# 将获取的数据交给pipelines
yield scrapy.Request('https://movie.douban.com/top250'+next_link, callback=self.parse)

保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下:
json格式,默认为Unicode编码
scrapy crawl douban_spider -o douban.json
json lines格式,默认为Unicode编码
scrapy crawl douban_spider -o douban.jsonl
csv 逗号表达式,可用Excel打开,注意编码方式
scrapy crawl douban_spider -o douban.csv
xml格式
scrapy crawl douban_spider -o douban.xml
