数据库事务使用日志文件,辅助实现数据库事务。
在分布式系统中,为了获得高可用性,通常会对数据进行复制,以维持数据的多个可用副本。
通过重做日志实现数据复制的思想已经广泛使用,例如,MySQL使用binlog复制从库,Zookeeper主节点向从节点广播操作所有操作序列。
我们需要一个可靠的日志服务组件。但是,要在项目中实现一个高可用的复制方案着实不易,要考虑的问题很多,硬盘故障导致数据丢失,应用宕机数据要恢复,在线扩容应用后数据要再平衡等等。
如果有一个高可用的日志服务,能够按顺序记录应用的所有写操作,我们的复制架构就可以简化为:
1)主节点先写操作日志Write-ahead Logging (WAL),然后修改主节点本地数据。
2)从节点通过Tail操作日志,完全回放主节点的写操作,从而与主节点的数据保持完全同步。
Apache Bookeeper 的目的就是提供这种高可用分布式日志存储服务。Bookeeper最初是Hadoop用来在线备份HDFS NameNode写操作的日志存储服务,后来成为Apache的一个独立子项目。目前,Apache Pulsar,Twitter通用日志服务组件等很多项目都在使用bookkeeper作为底层存储方案。
Bookeeper采用无主复制方案实现数据复制,它的目标是:高效写,高错误容忍性。
无主复制方案中没有主副本,每个副本是平等的,都需要处理读写操作,依赖多数裁决的方式,来确定操作结果。
1)写操作
写操作发送给所有N个副本,在获得超过半数副本确认后,即认为写成功。
2)读操作
从超过半数的节点读,由于读写的副本集合存在交集,那么一定可以读到写操作的结果。
Bookeeper使用的是相对==宽松的==的无主复制方案,它放宽了读写副本数量的限制,不要求一定超过半数。
创建Ledger时,指定保存数据的bookie节点数E,写节点数Qw,确认节点数Qa,满足: E >= Qw >= Qa 即可。
这带来了很有趣的特性,当E>Qw时,意味着每一次写都只会更新部分节点,Bookeeper利用这个特点,实现了条带化写(类似Raid0的条带化),使写操作均匀分布在E个节点上。
发生条带化写时,每个节点只保存了一部分数据,因此,读操作需要从多个节点读。
应用需要综合考虑对吞吐量、可用性、数据持久性的要求,使用合理的(E,Qw,Qa)创建Ledger。高吞吐量=>增大E,减小Qw,高可用性=>减小Qa,数据持久性=>增大Qa。
Bookeepr提供的数据一致性保证是:顺序写(写操作不乱序,前面的数据确认前,不会确认后面的数据),前缀一致读(不会发生数据回滚)。
对每一个Ledger只允许一个Writer,和多个reader,读写可以并行。但是,由于writer只在关闭ledger时才会把该ledger的LastCommitId更新到ledger的元数据中(在zk中保存),reader没有办法实时获取当前ledger的最新数据进展。当然,reader可以使用屏蔽读打开ledger,这会强制writer关闭ledger。也就是说,读写没办法并行。
在Pulsar中,为每一个topic(由多个ledger构成)指定一个owner,所有消息读写操作都通过owner进行。因此,owner不需要经过zk,就知道LastCommitId,因此可以提供实时的读写并发服务。
可以从Bookeeper官网了解基本概念,相关在资料在文末有链接,这里谈一些笔者自己的理解。
1.Bookeeper的可扩展性怎么体现?
Bookeeper数据存储的逻辑模型:
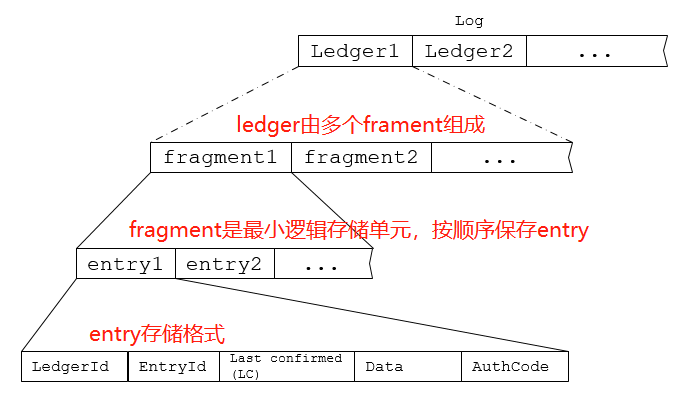
Ledger的元数据格式:
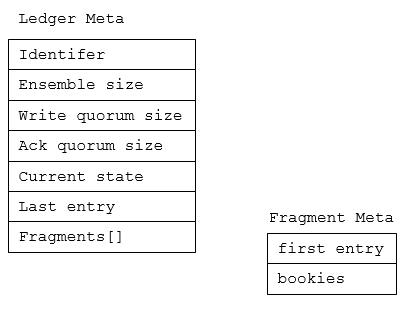
当创建或重新打开ledger时,会创建一个新的fragment,分配保存数据的bookies。另外,在写数据过程中某一个bookie出现故障时,也会关闭当前frament,创建新的frament,并重新分配保存数据的bookies(不包含出故障的bookie)。
因此,fragment是bookeeper最小的逻辑数据单元,数据持久化的保证也是在fragment的级别上起作用。
通过把应用的日志和数据流分割成一个一个的segment,每个segment存储在Bookeeper的一个ledgers中,数据自然就分布在整个数据集群中。
这样处理的好处:逻辑日志和物理存储解耦,日志大小不局限于单个服务器的存储空间;存储集群中增加新服务器后,新创建的ledgers会自动利用新增的存储空间。
2.什么是条带化写,它带来什么好处?
Bookeeper的复制方案对Write Quorums方案做了一些优化,
E : 副本个数
Qw: 写副本数量
Qa: 等待响应副本数量
E >= Qw >= Qa。
当Qw=E时,Writer向所有Bookies发送写请求。
当Qw由于条带化只写Qw个Bookie,它降低了系统的IO压力。
3.怎么处理Bookies异常?
writer向Qw个副本发生写操作请求,当收到Qa个Ack时,认为写入成功。
当未收到某个Bookies的响应时,Writer就关闭当前ledgers,设置ledgers的last commit id。然后,新建一个ledgers(新分配的Ensembles不包含出问题的Bookies),开始后续的写操作。
4.当writer异常宕机后,如何正确修复数据和关闭ledgers?
当writer发送故障宕掉时,ledgers会处于未关闭状态,后续的writer/reader必须先修复数据:
a) 在zk中把ledgers置为恢复状态;
b) 通过RPC要求所有相关的Bookies屏蔽该ledgers的所有后续写操作;
c) 向所有Bookies读取该ledgers最后提交的entryId,在收到Qw个Ack后,确定该ledger的最大highEntryId;
d) 从ledger最后活动的fragment头部开始,逐条读取数据,确保每一个entry都有Qw个副本;
e) 最后,在zk修改ledgers为关闭状态,并把最后有效记录置为highEntryId。
5.Bookie如何确定消息的commit状态?如何实现pipeline写?
Bookeeper使用一个类似两阶段提交的方式确定最后提交的entryId,有两种方式发送commit消息,
a)捎带:每条写消息都会携带当前已经提交的最大entryId(writer收到Qa个Ack的消息)。
b)单独发送:在指定时间内没有新消息发送时,单独发一个commit控制消息WriteLacRequest 给Bookies。这个消息对reader不可见。
一旦Bookie收到一个commit entryId,就意味着这个entryId及之前的所有消息都是committied,对reader可见。
写操作和commit在逻辑上是两个独立的操作,很容易在writer实现pipeline写。
例如,当前writer确认当前commitId为100,这时候连续发送了110、111、112三条消息,消息中携带的last commit id都是100。过了一段时间writer收到Qa个对108号消息的确认,在后续发送的113号消息(或者因为没有后续消息,单独发送一个commit消息)中携带的last commit id就要写上108,Bookies收到消息后就可以确认108以前的消息都是已提交的,reader可见。
6.读操作有哪些方式?
常见的两种read方式:
a) 指定entryId读(ReadRequest),读取一条entry。
b) 长轮询(ReadLacRequest),实时读最新的记录,达到tail账本的目的。
因为是Quorums读,reader就需要从多个Bookies读数据,这也存在多种方式,
a) 顺序请求,依次向E中的副本读数据,直到读到为止(考虑Bookies数据损坏,或发生条带化写)。
b) 并发请求,同时向E中的所有副本读数据。
7.Bookeeper在zk里保存什么数据?
Bookeeper使用zk:
a) 保存ledger元数据,包括E、Qw、Qa配置,fragment列表,状态(OPEN/CLOSE/RECOVERY)、last commit entryId等。
b) 当使用Log Api时,还要保存Log的元信息。
近来Bookeeper社区有一种声音,要使用etcd代替zk,考虑点:
1. Zookeeper’s log is only exposed through a tree like interface. It can be hard to shoehorn your application into this.
2. A zookeeper ensemble of multiple machines is limited to one log. You may want one log per resource, which will become expensive very quickly.
3. Adding extra machines to a zookeeper ensemble does not increase capacity nor throughput.
另外,Etcd已经在k8s中集成,使用Etcd更方便部署。
8.Bookeeper在存储实现上有哪些优秀的设计?
Bookeeper存储有4个核心组件:
- Journals: WAL日志,提升吞吐量,防止数据丢失。
- Index:为每一个entry,保存在EntryLog文件中的位置索引,{(ledgerId,entryId), offset}。
- EntryLog:顺序保存所有ledger的消息,当bookie启动,或者文件过大时,创建新的EntryLog。
- WriteCache:写操作在同步写入Journals日志,在内存缓存。
- ReadCache: 读操作时先读WriteCache(因为这是最新写入的数据),如果找不到则从ReadCache查找,如果还没有,则通过Index查找entry的文件偏移,从文件把数据读入ReadCache,最后返回数据给reader。
Bookeeper的Journals日志是同步顺序写,Endex和EntryLog是异步顺序写(后台线程周期性fsync()),把它们放在不同磁盘上,可以充分发挥Bookeeper的IO性能。
参考Understanding How Apache Pulsar Works
9.Plusar使用Bookeeper的基本原理?
Plusar可以认为是建立在Bookeeper/Zookeper上的一个Proxy,
- 使用多个ledger序列来保存一个topic的数据,获得极大的吞吐量和存储扩展性。
- 为每个topic指定一个owner proxy,主题的读写都通过这个owner进行,巧妙的处理了bookeeper中reader无法及时获取ledger的LastCommitId的问题。
- 在proxy上维护cache,减少向bookeeper存储读取数据的次数,提升性能。
- Plusar有一些后台进程,在不断扫描和修复数据,确保每一个fragment都有Qa个副本。
- 基于bookeeper的数据可靠性保证,向Plusar的用户提供数据可靠性保证。
- Plusar可以为每个消费组提供:独占、共享、主备三种访问语义。
从Plusar的底层模型推断,Plusar可以提供"恰好一次"发布语义,
- 当writer不出故障时,Bookeeper存储模型可以保证这一点;当writer故障时,reader可以正确关闭ledger,writer重启后,通过查看ledger的lastCommitId可以知道最后提交的消息,不会发生消息丢失和重复)。
- 但是对于reader来说,它可能在消费了数据,但没有提交commit时意外的挂掉。再重启后,就会读到重复的数据。对这种跨系统的”恰好一次“投递语义,需要应用程序介入。
参考资料
- concepts
- protocol
- BP-28-etcd-as-metadata-store
- bookeeperOverview
- intro-to-bookkeeper
- why-apache-bookkeeper-part1
- why-apache-bookkeeper-part2
- Scaling out Total Order Atomic Broadcast with Apache BookKeeper
- Understanding How Apache Pulsar Works