XLNet 预训练模型及命名实体识别
谷歌的团队继 BERT 模型之后,在 2019 年中旬又 提出了 XLNet 模型。XLNet 在多达 20 个任务上均取得了超越 BERT 的成绩,还在如问答系统、自然语言推理、情感分析、文本排序等任务上超过了目前的最好成绩。
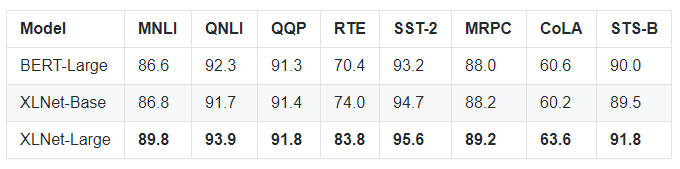
下面是 XLNet 在 GLUE 上的测试结果:
XLNet 在 BERT 和 GPT-2 上的改进
BERT 的缺点
可以说 XLNet 是 BERT 的增强版,但它与 BERT 又有许多不同之处。下面,我们将详细介绍一下。
在第一次实验中提到的,BERT 是自编码模型(Autoencoding),换一种说法来说就是,BERT 以遮蔽语言模型(Masked Language Model)为训练目标。训练自回归模型时,输入语句的一些词会被随机替换成 [MASK] 标签,然后训练模型预测被标签掩盖的词。
我们可以从这个过程中看到两个缺点:
错误地假设了被覆盖词与被覆盖词之间是独立的。
使预训练和微调时的输入不统一。
缺点 1 是指,在进行预测时,由于部分词被 [MASK] 覆盖,所以当 BERT 模型在预测一个被覆盖词时,忽略了其他的覆盖词对他的影响。也就是假设了所有被覆盖词是不相关的,很明显可以知道这个假设是错误的。
缺点 2 是指,在预训练是我们使用了 [MASK] 标签把部分词覆盖,而在微调预训练好的模型时,我们并不会使用到这个标签,这就导致了预训练过程和微调过程不符。
GPT-2 的缺点
在上一次实验中我们介绍了,GPT-2 是自回归模型(Autoregressive),即通过待预测词之前或之后的文本作为语境信息进行预测。

但是自回归模型的一个很明显的缺点就是,它只能考虑一个单方向的语境。很多时候的下游任务,如自然语言理解,会同时需要前后两个方向的语境信息。
介绍完 BERT 所代表的自编码模型和 GPT-2 所代表的自回归模型的固有缺点,下面就要介绍一下 XLNet 是如何针对这两类模型的缺点进行的改进。
XLNet 的改进
研究人员在设计 XLNet 模型时,考虑到要克服自编码模型和自回归模型的缺点,并且要结合它们的优势,设计出了排列语言模型(Permutation Lanuage Model)。如下图所示,排列语言模型的思想是,既然自回归语言模型只能获取单向语境,那就通过改变字词排列位置的方法将双向的语句排列到单向。

以图中右上角的部分为例,当字词排列变为 "2 -> 4 -> 3 -> 1",并且训练目标为预测第 3 个字词时,输入模型的为词 2 和词 4 的信息。这样模型即保留了自回归模型的特点,又使得模型学习到了双向的语境信息。
需要注意,改变排列不会实际改变字词的位置信息,即排在第三位的词的位置向量还是会对应该词是第三位的信息。
在具体实现时,通过对注意力机制的掩膜的作用之一就是进行改变来达到改变排列的目的,可以参照下图红框部分,

此图的其他部分含义在下文会介绍,这里先说一下红框的部分。以上半部分的第二行为例,表示当对单词 2 之后的词进行预测时,对每个单词添加的掩膜,并且此时的排列顺序为 "3 -> 2 -> 4 -> 1"。所以,这时添加到单词 2 和 3 的掩膜值应为 1 ,表示模型可以看到的词,而其余词的值应为 0。同时我们也可以看到图中第二行中第 2 和 3 列对应的掩膜都被标成了红色。上半部分的其他行同理。
而图中下半部分的不同是,下半部分添加的掩膜可以使得模型看不到每个待预测的词,这样当模型预测单词 2 时就不会产生模型已经见过单词 2 的问题。
XLNet 模型结构
SentencePiece 分词方法
XLNet 模型使用了 SentencePiece 的分词方法,SentencePiece 是谷歌开源的自然语言处理工具包。它的原理是统计出现次数多的片段,则认为该片段是一个词。
SentencePiece 工具特别之处在于,它不依赖于之前的训练,而是通过从给定的训练集中学习,并且它不会因为语言不同而有不一样的表现,因为它把所有字符串中的字符都认为是 Unicode 字符。
可以说使用 SentencePiece 优化了 BERT 使用的 WordPiece 方法对中文分词效果不好的问题。
双流自注意力机制
从总体结构上来说,XLNet 的模型结构和 BERT 的结构差异不大,都是以 Transformer 为基础。但 XLNet 模型使用了特别的注意力机制,即双流自注意力机制(Two-Stream Self-Attention),XLNet 的双流自注意力机制使用了两种特征表征单元,分别为内容表征单元和询问表征单元。
内容表征单元是对上文信息的表示,会包含当前的词。询问表征单元包含对除当前词之外的上文信息的表示,以及包含当前词的位置信息,而不能访问当前词的内容信息。
内容表征单元与询问表征单元构成了两种信息流,这两种信息流不断向上传递,在最后输出询问单元的信息。并且我们可以从下图的红框部分看到,最后的输出的预测结果中对应的字词顺序和输入时相同。
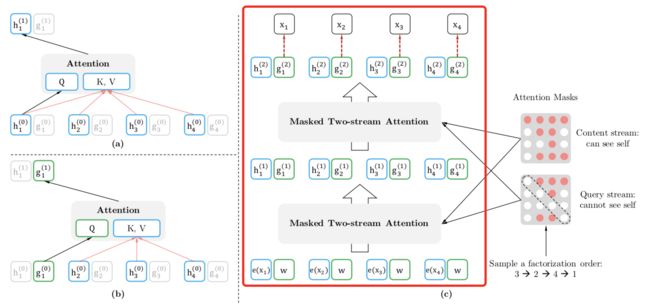
下面详细了解一下这个图中的各部分,首先图(a)部分表示的是内容流注意力(Content stream attention),图(b)部分表示的是询问流注意力(Query stream attention)。我们可以看到在图(b)中词 1 对应的只有询问表征单元被输入,而在图(a)中词 1 的内容表征单元也被输入了。图(c)部分表示的是模型如何应用双流自注意力机制。而图(c)右侧是注意力掩膜,我们在上文中也有介绍。添加掩膜的作用除了达到改变排列的目的,还达到了使模型在内容流注意力中能看到当前词,而在询问流注意力中不能看到当前词的目的。
除了上面提到的方法,XLNet 还使用了部分预测的方式,因为自回归语言模型是从第一个词预测到最后一个词,但在预测的初始阶段,由于已知的语句信息较少,模型很难收敛,所以实际只选择预测语句后 1/K 的词,而前面 1-1/K 的部分作为上下文信息。
XLNet 命名实体识别
上面,我们介绍了 XLNet 在 BERT 和 GPT-2 基础上的改进之处,以及 XLNet 模型所使用的一些特别的方法。接下来我们将使用 XLNet 的预训练模型进行命名实体识别实验。命名实体识别(Named Entity Recognition,简称 NER),是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。命名实体识别是信息抽取的重要一步,被广泛应用在自然语言处理领域。
本次实验中我们使用的训练和测试数据来源为 CoNLL-2003, CoNLL-2003 数据集是以新闻语料为基础,标注的实体有四种,分别为:公司、地点、人名和不属于以上三类的实体。分别命名为 ORG, LOC, PER, MISC,实体的第一个字标为 B-ORG, B-LOC, B-PER, B-MISC,第二个字标为 I-ORG, I-LOC, I-PER, I-MISC,标注为 O 的字词表示它不属于任何一个短语。
下面我们将使用在 PyTorch-Transformers 模型库中封装好的 XLNetTokenizer() 和 XLNetModel 类来实际进行一下 XLNet 预训练模型应用。首先,需要安装 PyTorch-Transformers。
!pip install pytorch-transformers==1.0 # 安装 PyTorch-Transformers
因为原始数据结构较复杂,所以我们提前将数据重新整理过,已按照如下的标签标注数据。
# 标签数据所对应的字符串含义
label_dict = {'O':0, 'B-ORG':1, 'I-ORG':2, 'B-PER':3, 'I-PER':4, 'B-LOC':5, 'I-LOC':6, 'B-MISC':7, 'I-MISC':8, 'X':9, '[PAD]':10}
可以注意到上面的标签中多了 X 和 [PAD] 标签,它们的含义分别为:因为分词会使得某些原本完整的单词断开,而断开的多出来的部分我们设为标签 X。[PAD] 标签对应则的是填补的字符。
接下来要下载数据集,我们已经提前下载好并存放在蓝桥云课服务器中,可通过以下命令读取。
!wget -nc "https://labfile.oss.aliyuncs.com/courses/1372/conell2003.zip"
!unzip -o "conell2003.zip"
下载好数据集后,读取数据文件。
train_samples = []
train_labels = []
with open('./train.txt', 'r') as f:
while True:
s1 = f.readline()
if not s1:
# 如果读取到内容为空,则读取结束
break
s2 = f.readline()
_ = f.readline()
train_samples.append(s1.replace('\n', ''))
train_labels.append(s2.replace('\n', ''))
len(train_samples), len(train_labels)
由于上文提到的,分词会使某些完整的词断开,所以分词后,我们要在原始数据的基础上再进行标签的增加。例如词 “She's”,会被分为 “She”,“'”,“s”,三个词,这时就将原本词 “She's” 对应的标签 O 标在词 “She” 上,而 “'”,“s” 分别表为 X 和 X。下面的代码就是上述标签修改的具体实现。
from pytorch_transformers import XLNetTokenizer
# 使用 XLNet 的分词器
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
input_ids = []
input_labels = []
for text, ori_labels in zip(train_samples, train_labels):
l = text.split(' ')
labels = []
text_ids = []
for word, label in zip(l, ori_labels):
if word == '':
continue
tokens = tokenizer.tokenize(word)
for i, j in enumerate(tokens):
if i == 0:
labels.append(int(label))
text_ids.append(tokenizer.convert_tokens_to_ids(j))
else:
labels.append(9)
text_ids.append(tokenizer.convert_tokens_to_ids(j))
input_ids.append(text_ids)
input_labels.append(labels)
len(input_ids), len(input_labels)
在准备好数据后,这里使用 PyTorch 提供的 DataLoader() 构建训练集数据集表示,使用 TensorDataset() 构建训练集数据迭代器。
import torch
from torch.utils.data import DataLoader, TensorDataset
del train_samples
del train_labels
for j in range(len(input_ids)):
# 将样本数据填充至长度为 128
i = input_ids[j]
if len(i) != 128:
input_ids[j].extend([0]*(128 - len(i)))
for j in range(len(input_labels)):
# 将样本数据填充至长度为 128
i = input_labels[j]
if len(i) != 128:
input_labels[j].extend([10]*(128 - len(i)))
# 构建数据集和数据迭代器,设定 batch_size 大小为 8
train_set = TensorDataset(torch.LongTensor(input_ids),
torch.LongTensor(input_labels))
train_loader = DataLoader(dataset=train_set,
batch_size=8,
shuffle=True)
train_loader
检查是否机器有 GPU,如果有就在 GPU 运行,否则就在 CPU 运行。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
由于 XLNet 预模型体积很大,且托管在外网,所以本次实验先从蓝桥云课镜像服务器下载预训练模型,本地实验无需此步骤。
!wget -nc "https://labfile.oss.aliyuncs.com/courses/1372/xlnet-base-shiyanlou.zip"
!unzip -o "xlnet-base-shiyanlou.zip"
下面构建用于命名实体识别类,命名实体识别本质上是在进行分类,在 XLNet 模型下加入一个 Dropout 层用于防止过拟合,和一个 Linear 全连接层。
import torch.nn as nn
from pytorch_transformers import XLNetModel
class NERModel(nn.Module):
def __init__(self, num_class=11):
super(NERModel, self).__init__()
# 读取 XLNet 预训练模型
self.model = XLNetModel.from_pretrained("./")
self.dropout = nn.Dropout(0.1)
self.l1 = nn.Linear(768, num_class)
def forward(self, x, attention_mask=None):
outputs = self.model(x, attention_mask=attention_mask)
x = outputs[0] # 形状为 batch * seqlen * 768
x = self.dropout(x)
x = self.l1(x)
return x
定义损失函数。这里使用了交叉熵(Cross Entropy)作为损失函数。
def loss_function(logits, target, masks, num_class=11):
criterion = nn.CrossEntropyLoss(reduction='none')
logits = logits.view(-1, num_class)
target = target.view(-1)
masks = masks.view(-1)
cross_entropy = criterion(logits, target)
loss = cross_entropy * masks
loss = loss.sum() / (masks.sum() + 1e-12) # 加上 1e-12 防止被除数为 0
loss = loss.to(device)
return loss
实体化类,定义损失函数,建立优化器。
from torch.optim import Adam
model = NERModel()
model.to(device)
model.train()
optimizer = Adam(model.parameters(), lr=1e-5)
开始训练。
from torch.autograd import Variable
import time
pre = time.time()
epoch = 3
for i in range(epoch):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(target).to(device)
optimizer.zero_grad()
# 生成掩膜
mask = []
for sample in data:
mask.append([1 if i != 0 else 0 for i in sample])
mask = torch.FloatTensor(mask).to(device)
output = model(data, attention_mask=mask)
# 得到模型预测结果
pred = torch.argmax(output, dim=2)
loss = loss_function(output, target, mask)
loss.backward()
optimizer.step()
if ((batch_idx+1) % 10) == 1:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
i+1, batch_idx, len(train_loader), 100. *
batch_idx/len(train_loader), loss.item()
))
if batch_idx == len(train_loader)-1:
# 在每个 Epoch 的最后输出一下结果
print('labels:', target)
print('pred:', pred)
print('训练时间:', time.time()-pre)
训练结束后,可以使用验证集观察模型的训练效果。
读取验证集数据和构建数据迭代器的方式与训练集相同。
eval_samples = []
eval_labels = []
with open('./dev.txt', 'r') as f:
while True:
s1 = f.readline()
if not s1:
break
s2 = f.readline()
_ = f.readline()
eval_samples.append(s1.replace('\n', ''))
eval_labels.append(s2.replace('\n', ''))
len(eval_samples)
# 这里使用和训练集同样的方式修改标签,不再赘述
input_ids = []
input_labels = []
for text, ori_labels in zip(eval_samples, eval_labels):
l = text.split(' ')
labels = []
text_ids = []
for word, label in zip(l, ori_labels):
if word == '':
continue
tokens = tokenizer.tokenize(word)
for i, j in enumerate(tokens):
if i == 0:
labels.append(int(label))
text_ids.append(tokenizer.convert_tokens_to_ids(j))
else:
labels.append(9)
text_ids.append(tokenizer.convert_tokens_to_ids(j))
input_ids.append(text_ids)
input_labels.append(labels)
del eval_samples
del eval_labels
for j in range(len(input_ids)):
# 将样本数据填充至长度为 128
i = input_ids[j]
if len(i) != 128:
input_ids[j].extend([0]*(128 - len(i)))
for j in range(len(input_labels)):
# 将样本数据填充至长度为 128
i = input_labels[j]
if len(i) != 128:
input_labels[j].extend([10]*(128 - len(i)))
# 构建数据集和数据迭代器,设定 batch_size 大小为 1
eval_set = TensorDataset(torch.LongTensor(input_ids),
torch.LongTensor(input_labels))
eval_loader = DataLoader(dataset=eval_set,
batch_size=1,
shuffle=False)
eval_loader
将模型设置为验证模式,输入验证集数据。
from tqdm.notebook import tqdm
model.eval()
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(tqdm(eval_loader)):
data = data.to(device)
target = target.float().to(device)
# 生成掩膜
mask = []
for sample in data:
mask.append([1 if i != 0 else 0 for i in sample])
mask = torch.Tensor(mask).to(device)
output = model(data, attention_mask=mask)
# 得到模型预测结果
pred = torch.argmax(output, dim=2)
# 将掩膜添加到预测结果上,便于计算准确率
pred = pred.float()
pred = pred * mask
target = target * mask
pred = pred[:, 0:mask.sum().int().item()]
target = target[:, 0:mask.sum().int().item()]
correct += (pred == target).sum().item()
total += mask.sum().item()
print('正确分类的标签数:{},标签总数:{},准确率:{:.2f}%'.format(
correct, total, 100.*correct/total))
可以看到最后的准确率在 90% 以上。在应用提取实体时,有时还会用添加规则的方式提取完整实体词,或将最后预测标签时的 Softmax 层替换为 条件随机场 提高准确率。
Quora 文本相似度分析比赛
挑战说明
本次挑战使用 Kaggle 平台上的 分辨 Quora 问题对 比赛作为数据集,进行文本相似度判断。
在进行文本相似度问题计算时有多种方法,比如可以计算句向量,然后计算两句之间的余弦相似度,最后设定阈值判断文本相似与否。其中计算句向量有多种方法,例如使用词袋模型、Word2Vec 预训练模型或最新的 BERT 预训练模型等。
在本次挑战中,推荐使用将文本相似度问题转化为文本分类问题的方法。详细来说,以文本 What is the step by step guide to invest in share market in india? 和文本 What is the step by step guide to invest in share market? 的比较为例,这两句不是重复的,即标签为 0。那么转化为分类问题后,待分类文本为 What is the step by step guide to invest in share market in india? What is the step by step guide to invest in share market?,标签为 0。
题目:请阅读分辨 Quora 问题对比赛说明,并使用 PyTorch-Transformers 模型库中封装好的 XLNet 预训练模型完成该比赛,最后尝试通过 Kaggle 提交获取排名成绩。
你可以下载数据集在本地完成,也可以使用 Kaggle 提供的 * Kaggle Notebook* 环境在线完成。最后,通过比赛页面的右上角的 Submission Predictions 提交挑战结果后即可看到排名信息。
本地练习时,数据集下载地址:
# 数据版权归 Kaggle 所有,复制链接粘贴到浏览器下载
https://labfile.oss.aliyuncs.com/courses/1372/quora-question-pairs.zip
数据集包含 3 个文件,释义如下:
├── sample_submission.csv # 预测数据提交示例格式
├── test.csv # 比赛需预测数据集
└── train.csv # 比赛用训练数据集