2021.1.7下午记
大家新年好~
距离上次写这个课题的博客已经是去年12.30的时候了,是想趁热打铁赶快写的,无奈1.5/1.6有两门考试,便只好赶去复习暂时搁置了。现在终于考完试,而且也马上到了图像处理大课题报告的截止日期了,于是我马上赶来写博客了。
之前讲的都是课题分析,环境配置还有我们是怎么使用Google云盘链接Colaboratory用Google服务器端提供的16G显存进行训练,现在终于来到了最核心的部分了,也就是对于我们选定的入门网络Retinanet网络的学习和实现。
这一篇文章就梳理一下我们对Retinanet网络的学习和实现。
首先还是放一下我们参考的Retinanet网络实现的博客和B站讲解链接:
【睿智的目标检测17——Keras搭建Retinanet目标检测平台】
(https://blog.csdn.net/weixin_44791964/article/details/104327456)
【Keras 搭建自己的Retinanet目标检测平台(Bubbliiiing 深度学习 教程)】(https://www.bilibili.com/video/BV1f741177HD?p=10)
以及Retinanet提出来时发表的论文链接:
【Focal Loss for Dense Object Detection】
(https://arxiv.org/pdf/1708.02002.pdf)
最初的选择:Retinanet目标检测算法
1、选择理由
(1)优势
Retinanet这个网络其实算是目标检测算法里一个里程碑的存在吧,不过具有里程碑意义的,还是这个网络所运用的损失函数Focal Loss。Focal Loss这个损失函数解决了类别不平衡的问题,大大提升了one-stage算法的检测精度,使one-stage算法在保持高速处理的同时精度不再落后于two-stage算法。
我们查阅资料发现,作为单阶段网络(one-stage),Retinanet兼具速度和精度(精度是没问题的,但目标检测算法发展到现在,Retinanet的速度已经远远比不上新提出的算法了,但在当时应该可以说是速度和精度兼备),它是非常耐用的一个检测器,现在很多单阶段检测器是以Retinanet为baseline,进行各种改进,足见Retinanet的重要。而且,看了那个博主的介绍,我们发现其实Retinanet网络还是比较简单的,会比较适合刚刚入门的人。综上,基于CSDN上的一些博客,如果要入门目标检测算法,我觉得这个网络就很合适,不会太旧但也不是太新,作为之后许多目标检测检测器的baseline,掌握了Retinanet,想必之后再去学习其他的网络也就容易许多了。事实证明这并没有错,我们在理解并实现了Retinanet后,尝试使用在其基础上改进的新的算法,比如之前提到的EfficienDet,我们发现,不同目标检测算法之间可能只是多使用了一些小trick,可能只是在某一部分稍稍进行了改进。在基本掌握Retinanet以及Retinanet的实现代码之后再去看比较新的算法,确实容易很多。



以下解释摘自博客:
https://blog.csdn.net/JNingWei/article/details/80038594?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
- 什么是“类别不平衡”呢?
详细来说,检测算法在早期会生成一大波的bbox。而一幅常规的图片中,顶多就那么几个object。这意味着,绝大多数的bbox属于background。- “类别不平衡”又如何会导致检测精度低呢?
因为bbox数量爆炸。
正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就低了。- 那为什么two-stage系就可以避免这个问题呢?
因为two-stage系有RPN罩着。
第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于前景类bbox,但是至少数量差距已经不像最初生成的anchor那样夸张了。就等于是 从 “类别 极 不平衡” 变成了 “类别 较 不平衡” 。
不过,其实two-stage系的detector也不能完全避免这个问题,只能说是在很大程度上减轻了“类别不平衡”对检测精度所造成的影响。
接着到了第二个stage时,分类器登场,在初筛过后的bbox上进行难度小得多的第二波分类(这次是细分类)。这样一来,分类器得到了较好的训练,最终的检测精度自然就高啦。但是经过这么两个stage一倒腾,操作复杂,检测速度就被严重拖慢了。- 那为什么one-stage系无法避免该问题呢?
因为one stage系的detector直接在首波生成的“类别极不平衡”的bbox中就进行难度极大的细分类,意图直接输出bbox和标签(分类结果)。而原有交叉熵损失(CE)作为分类任务的损失函数,无法抗衡“类别极不平衡”,容易导致分类器训练失败。因此,one-stage detector虽然保住了检测速度,却丧失了检测精度。
(2)劣势
当然了,从Retinanet提出所在的论文名:Focal Loss for Dense Object Detection,我们也可以明显发现,其实这篇论文并不是专门为了提出Retinanet而发表的,这篇论文的核心其实是提出了一个新的损失函数:Focal Loss。所以Retinanet的提出其实就是为了证明Focal Loss这个损失函数的有效性。所以说,这里的创新并不是网络设计的创新,而是损失函数的创新。
为了证明其有效性,在设计的时候提取的anchor box数量很多,将近100K,这实际上不利于我们做高速的检测,但却可以充分验证Focal Loss这个损失函数对征服类别不平衡这一问题的有效性(因为精度确实很高)。可实际上我们并不需要这么多的先验框,对每个先验框都要做判断做筛选,这无疑会大大降低它的处理速度。这也是我们后面才意识到的,虽然它的精度很高,但是速度确实比较慢。
2、算法结构
在这里就简单介绍一下整个网络的结构吧。

(1)主干特征提取网络:ResNet
ResNet50有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,用于加深网络的。
要了解Resnet的构成,首先要了解一下残差网络。
Residual net(残差网络):
将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。
意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献。
其结构如下:

Conv Block的结构如下:

Identity Block的结构如下:

当输入的图片为600x600x3的时候,shape变化与整个的Resnet网络结构如下:
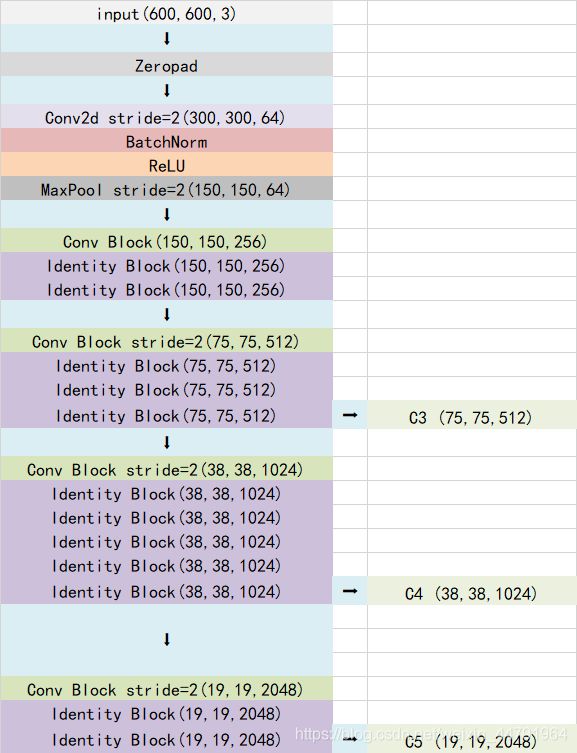
由上图可以看出,我们取出长宽压缩了三次、四次、五次的结果输出来进行网络金字塔FPN的构造。
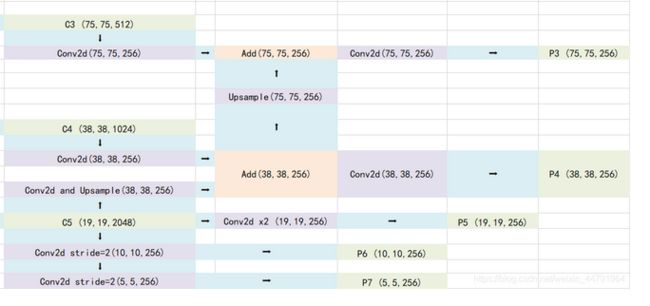
(2)特征加强网络:特征金字塔FPN(Feature Pyramid Network)
由最开始放的Retinanet整体结构图可知,获得到的特征还需要经过图像金字塔的处理,这样的结构可以融合多尺度的特征,实现更有效的预测。
特征金子塔对主干特征网络提取出的特征层进一步进行融合主要是为了得到更高语义的信息。
此外,输出不同层次的特征层是因为卷积多次,小物体的特征可能会丢失,不利于小物体的检测,但是有利于大物体的检测。所以进行特征融合的话不仅可以提取更丰富的特征信息,而且可以兼顾大物体和小物体的检测。
以下则为Retinanet中特征金字塔的构造,最终会输出P3—P7这五层。
(3)目标框回归和分类回归子网(Class Subnet+Box Subnet)
通过特征金字塔我们可以获得五个有效的特征层,分别是P3、P4、P5、P6、P7,
为了和普通特征层区分,我们称之为有效特征层,将这五个有效的特征层分别传输过class+box subnets就可以获得预测结果了。
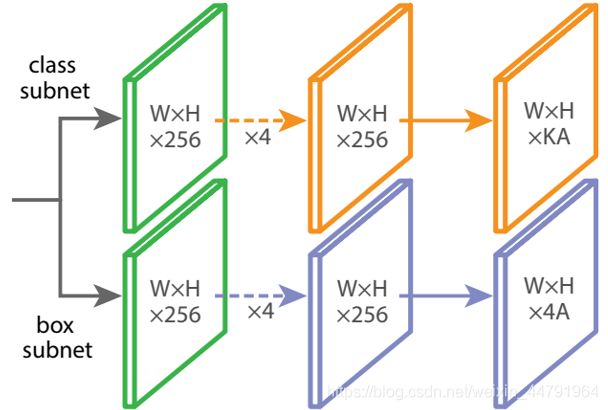
class subnet采用4次256通道的卷积和1次num_priors x num_classes的卷积,num_priors指的是该特征层所拥有的先验框数量,num_classes指的是网络一共对多少类的目标进行检测。
box subnet采用4次256通道的卷积和1次num_priors x 4的卷积,num_priors指的是该特征层所拥有的先验框数量,4指的是先验框的调整情况。
需要注意的是,每个特征层所用的class subnet是同一个class subnet;每个特征层所用的box subnet是同一个box subnet。
其中:
num_priors x 4的卷积用于预测该特征层上每一个网格点上每一个先验框的变化情况。num_priors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类。
(4)Focal Loss损失函数
作为Retinanet网络中应用的最核心内容,Focal Loss当然需要好好了解一下。

论文的提出是为了解决类别不平衡导致负样本占据了loss主导地位而模型难以收敛到好的效果的问题
类别不平衡:模型对分类的输出有可能几乎正确(easy example,即在应该是0的地方输出接近0,或该是1的地方输出接近1,多数情况下,背景是easy example,即easy negative),也可能错得离谱(hard example,通常是错误分类为占多数的类,通常是包含object的区域,之所以说hard是因为这部分比较难学),几乎正确的分类loss会很低,而错误的分类loss会很高,这本来是很好的。可是当object特别稀疏而导致即使对于每个easy negative 的loss都很低时,由于压倒性的数量优势,这部分loss仍然在总的loss中占了绝对主导地位,也就在梯度传导中占了主导地位,所以导致原来错误的hard example几乎没有被得到应有的改正。如果能想办法把错误分类的loss和正确分类的loss之间的差距再拉大点,就能一定程度上改善这种情况。
于是提出了Focal Loss的概念,如下图,正确分类的loss变得更低,错误分类的loss虽然也降低了,可是相比之下与正确分类的loss差距(从比例上看)拉大了很多。
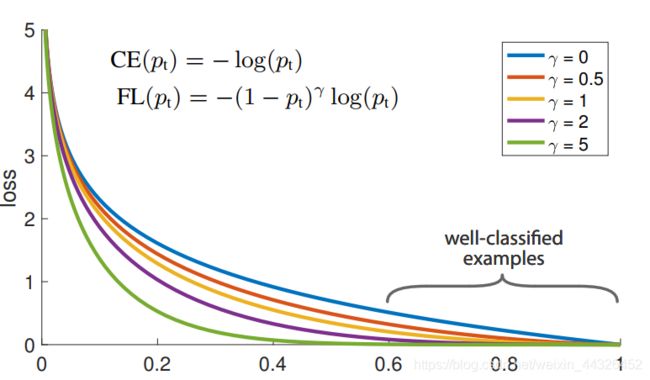
以下是我在看博客时看到有个博主从Focal Loss中获得的启发。确实啊,并不需要多么复杂的改进也能有很好的效果,最关键的是要关注到核心问题,抓住瓶颈背后的真正原因。我还记得当时在调参时看了一些调参的相关博客,当时看过一句话,博主说:过早的优化是万恶之源+抓住真正的瓶颈。我觉得印象真的很深刻,边角的漫无目的优化也许并不是最好的办法,也许只是在逃避真正的问题。在真正的进行具体细节的优化前,确实应该抓住真正的瓶颈,把最关键的问题解决后,性能才能明显提升,之后才应该去做细微的优化。所以在我看来,Focal Loss在目标检测算法发展史上有里程碑式的意义,就是因为它解决了一个瓶颈问题(one-stage检测精度总是比two-stage低)。

3、部分代码实现
整个程序的框架如下图所示:
以下是对各个文件的作用解释:
(1).idea、.temp_file、pycache文件夹:在Pycharm中运行所需要的文件夹(新建工程时会自动加入)
(2)annotations文件夹:存放的是验收时测试图片的所有标签文件
(3)img文件夹:存放检验代码性能时的测试集图片(即验收时900张图片的存放地址)
(4)logs文件夹:存放训练过程中生成的权重文件(模型)
(5)model_data文件夹:如下图所示,classes.txt中存放的是类名(rebar\coil\brickwork),还有一个COCO数据集的预训练权重,我们就是在该预训练权重的基础上进行训练的。

(6)nets文件夹:存放的是Retinanet网络搭建部分的代码(Resnet\FPN\Classsubnet、Boxsubnet)
(7)results文件夹:如下图所示,存放的是训练过程中不同模型的评估结果。不过需要运行另外三个特定的py文件。我们在此次完成课题的过程中并没有使用。

(8)utils文件夹:里面存放的py文件主要是用于获取先验框的。
(9)VOCdevkit文件夹:存放VOC格式的数据集,如下所示内部还有三个子文件夹和一个.py文件。Annotations存放的是测试集的所有.xml标签文件,ImageSets存放的是训练时所需要的四个文件(如下图)。JPEGImages存放的是测试集图片。voc2retinanet能够根据测试集生成下列四个txt文件。

(10)2007_test、2007_train、2007_val也是训练时需要使用的文件,可由下面的voc_annotation.py生成。
(11)compute_AP:验收时在完成对所有图片的计数后,执行该函数可以计算该模型的AP值和Error rate。
(12)newfile:由于比赛要求我们把每章图片的检测结果按照特定格式放到一个txt文件中,所以我们新建了newfile.txt用来存放每张图片对应各个类别的计数结果。
(13)predict:执行预测的py文件
(14)retinanet:存放检测图片的核心类和类方法
(15)testGPU:是我为了测试电脑是否正常使用GPU进行训练的程序。
(16)train:执行训练的文件
(17)video、Vision_For_prior:与打开摄像头的动态检测有关的文件,这次也没用到
(18)voc_annotation:用于生成上面的三个2007的文件。
下面就大概看一下以下几个比较重要的部分吧
(1)训练网络部分代码及流程(train.py)
文字描述这个还是不太容易,不如直接把代码和注释贴上来吧,有这些注释肯定能看懂。简单来说,训练部分主要是读入标签文件和测试文件,然后配置训练的各项参数。比如常规的batchsize、epoch,此处还设置了防止过拟合的early stopping(一定世代的loss没有下降就会认为达到了过拟合点)和梯度截断参数clipnorm,防止某一次的learning rate过大。而且训练轮次一共分为两大轮,第一大轮是冻结了某些参数(迁移学习的思想,不同的项目浅层的特征都差不多,冻结后参数比较少可以提升训练效率),第二大轮是解冻参数后的情况,一般这一轮的Batch size会设置得比较小防止参数过多内存溢出。
我的注释还是很多,因为一开始很多东西都不懂,只好一个一个去查。但其实不会特别麻烦,只要把这个掌握清楚了,之后再看其他网络的代码就容易许多了(熟悉了函数,熟悉了相似的结构)。
此外,训练部分还有两个步骤需要提到。
(1)对真实框的处理
在预测部分,每个特征层的预测结果,num_priors x 4的卷积用于预测该特征层上每一个网格点上每一个先验框的变化情况。也就是说,我们直接利用retinanet网络预测到的结果,并不是预测框在图片上的真实位置,需要解码才能得到真实位置。(所谓解码其实就是把得到的数字按一定规则转换为我们需要的位置值)
而在训练的时候,我们需要计算loss函数,这个loss函数是相对于Retinanet网络的预测结果的。我们需要把图片输入到当前的Retinanet网络中,得到预测结果;同时还需要把真实框的信息,进行编码,这个编码是把真实框的位置信息格式转化为Retinanet预测结果的格式信息。也就是,我们需要找到每一张用于训练的图片的每一个真实框对应的先验框,并求出如果想要得到这样一个真实框,我们的预测结果应该是怎么样的。
然后,我们可以获得真实框对应的所有的iou较大先验框,并计算真实框对应的所有iou较大的先验框应该有的预测结果。但是由于原始图片中可能存在多个真实框,可能同一个先验框会与多个真实框重合度较高,我们只取其中与真实框重合度最高的就可以了。因此我们还要经过一次筛选,将上述代码获得的真实框对应的所有的iou较大先验框的预测结果中,iou最大的那个真实框筛选出来。
而focal会忽略一些重合度相对较高但是不是非常高的先验框,一般将重合度在0.4-0.5之间的先验框进行忽略。
(2)利用处理完的真实框与对应图片的预测结果计算loss
loss的计算分为两个部分:
1、Smooth Loss:获取所有正标签的框的预测结果的回归loss。
2、Focal Loss:获取所有未被忽略的种类的预测结果的交叉熵loss。
import nets.retinanet as retinanet
import numpy as np
import keras
from keras.optimizers import Adam
from nets.retinanet_training import Generator
from nets.retinanet_training import focal,smooth_l1
from keras.callbacks import TensorBoard, ModelCheckpoint,ReduceLROnPlateau, EarlyStopping
from utils.utils import BBoxUtility
from utils.anchors import get_anchors
import tensorflow as tf
#某一次报错的时候修改,这是为了程序开始运行,需要GPU的时候才申请GPU的使用。本电脑的GPU为2G,运行极容易出现内存溢出的现象,后面改用Google的colab平台进行训练
config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True))
sess = tf.compat.v1.Session(config=config)
if __name__ == "__main__":
NUM_CLASSES = 3 #类别数为3
input_shape = (600, 600, 3) #输入图片的大小
annotation_path = '2007_train.txt' #训练所需标签文件(图片名+目标框的信息)的路径
inputs = keras.layers.Input(shape=input_shape) #按方式二(输入输出层方式)构建模型(好处:可以获取隐藏层的信息——每一层的输出都可以取出查看)
model = retinanet.resnet_retinanet(NUM_CLASSES,inputs) #resnet_retinanet为Retinanet的整体网络结构,其存放在retinanet文件中
priors = get_anchors(model) #该函数通过输入该网络来得到先验框
bbox_util = BBoxUtility(NUM_CLASSES, priors)
#------------------------------------------------------#
# 训练自己的数据集时会提示维度不匹配正常
# 预测的东西不一样,自然维度也不匹配
#------------------------------------------------------#
#在训练好的coco数据集权重上继续训练,用自己训练出的权重进行训练效果并不太好,经常会出现loss增加的情况
#model.load_weights("model_data/resnet50_coco_best_v2.1.0.h5",by_name=True,skip_mismatch=True)
#使用自己已经训练的模型继续训练
model.load_weights("logs/2ep038-loss0.800-val_loss0.746.h5", by_name=True, skip_mismatch=True)
#输入的数据集其中0.1用于验证,0.9用于训练
val_split = 0.1
with open(annotation_path) as f: #根据annotation的路径打开标签文件,并将其赋给f对象
lines = f.readlines() #readline函数读取标签文件中的每一行的值,并存放到lines这个列表中
np.random.seed(10101)
"""
seed( ) 用于指定随机数生成时所用算法开始的整数值。
1.如果使用相同的seed( )值,则每次生成的随即数都相同;
2.如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。
3.设置的seed()值仅一次有效
"""
np.random.shuffle(lines) #最好不要让网络通过完全相同的minibatch,如果框架允许,在每个epoch都shuffle一次。随机打乱顺序
np.random.seed(None) #shuffle的作用:增加随机性。提高网络的泛化性能,避免因为有规律的数据出现,导致权重更新时的梯度过于极端,避免最终模型过拟合或欠拟合。
num_val = int(len(lines)*val_split)#标签文件的行数即为总训练数据数,乘以其比例0.1则为训练过程中用来做测试评估当前模型好坏的验证集的数量
num_train = len(lines) - num_val #总测试数据减去验证集即为训练集的数量
# 训练参数设置
logging = TensorBoard(log_dir="logs")#log_dir: 用来保存Tensorboard的日志文件等内容的位置。默认保存在当前文件夹下的logs文件夹之下
#Save the model after every epoch.
# 指定保存的权重文件的路径和名称;监视器;需要监视的值,此处要监视的是验证集上的损失val_loss;save_weights_only=true:保证只有模型的权重被保存,而不是整个模型被保存;
# save_best_only=False:不是只有最佳模型才被保存。period周期:多少个epoch执行一次checkpoint检查点,做一次评估,保存一次模型。此处是一个epoch就做一次评估.
checkpoint = ModelCheckpoint('logs/3ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=False, period=1)
#verbose:信息展示模式,0或1。为1表示输出epoch模型保存信息,默认为0表示不输出该信息
#两个世代val_loss没有下降的话,就将learning_rate减少到原来的一半,防止越过最优点
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=2, verbose=1)#学习率下降的多少,并且将其输出显示出来
#此处使用的防止过拟合的方法(early stopping)
#当发现有6个patience的val_loss没有下降,则会认为已经达到过拟合点,选择提前结束本轮的训练,
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=6, verbose=1)
"""Early stopping函数:监测值不再改善时,停止训练
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。
Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,
当accuracy不再提高时,就停止训练。这种做法很符合直观感受,因为accurary都不再提高了,在继续训练也是无益的,只会提高训练的时间。
那么该做法的一个重点便是怎样才认为validation accurary不再提高了呢?并不是说validation accuracy一降下来便认为不再提高了,
因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy又上去了,所以不能根据一两次的连续降低就判断不再提高。
一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。
此时便可以停止迭代了(Early Stopping)。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30……
"""
BATCH_SIZE = 4
gen = Generator(bbox_util, BATCH_SIZE, lines[:num_train], lines[num_train:], #列表的表示形式,序号为0~numtrain作为训练集,序号为numtrain~最后作为验证集
(input_shape[0], input_shape[1]),NUM_CLASSES)
#(input_shape[0], input_shape[1])为输入图片的大小,shape的第一维和第二维即为长和宽的比例
#------------------------------------------------------#
# 主干特征提取网络特征通用,冻结训练可以减少训练参数,加快训练速度
# 也可以在训练初期防止权值被破坏。
# 提示OOM或者显存不足调小Batch_size
#------------------------------------------------------#
for i in range(174): #为什么是174?
model.layers[i].trainable = False #冻结,使这些层的权重不会更新,只训练底层参数 “迁移学习”的思想,对于不同的特征提取网络,浅层的特征是相同的
#为了使之生效,在修改 trainable 属性之后,需要在模型上调用 compile()进行装载,理解为配备好模型训练前的准备工作,比如优化器的选择,比如损失函数(回归的损失函数和分类的损失函数)的选择。
model.compile(loss={
'regression' : smooth_l1(),
'classification': focal()
},optimizer=keras.optimizers.Adam(lr=1e-4, clipnorm=0.001) #初始学习率为10^-4,clipnorm帮助进行梯度裁剪,防止梯度下降导致越过最低点
)#梯度范数缩放: 在梯度向量的L2向量范数(平方和)超过阈值时,将损失函数的导数更改为具有给定的向量范数。例如,可以将范数指定为1.0,这意味着,如果梯度的向量范数超过1.0,则向量中的值将重新缩放,以使向量范数等于1.0。在Keras中通过在优化器上指定 clipnorm 参数实现:
#梯度范数缩放:就算loss的求导值很大,但为了保证稳定,一次梯度下降不会过多,设置一次的下降值不会超过clipnorm(0.001)
model.fit_generator( gen.generate(True),
steps_per_epoch=num_train//BATCH_SIZE, #每个训练epoch的步长,训练数量除以每一个批处理的数量
validation_data=gen.generate(False),
validation_steps=num_val//BATCH_SIZE, #每个验证集的步长,验证集数目除以一次批处理的数目
epochs=15,
verbose=1,
initial_epoch=0, #设置训练时候应用的回调函数(理解为模型优化过程遵守的规则)
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
#解冻部分层的权值,和其他参数一起参与训练更新(此处会极大的增加网络中的参数量)。使用第一阶段以训练完成的网络权重继续训练,此时学习率应设置得比上一次要小。
for i in range(174):
model.layers[i].trainable = True
model.compile(loss={
'regression' : smooth_l1(),
'classification': focal()
},optimizer=keras.optimizers.Adam(lr=1e-5, clipnorm=0.001) #
)
model.fit_generator( gen.generate(True),
steps_per_epoch=num_train//BATCH_SIZE,
validation_data=gen.generate(False),
validation_steps=num_val//BATCH_SIZE,
epochs=40,
verbose=1,
initial_epoch=15,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
"""
对于小型,简单化的数据集,直接使用Keras的.fit函数,
实际项目中,训练数据会很大,简单地使用model.fit将整个训练数据读入内存将不再适用,所以需要改用model.fit_generator分批次读取,并且我们还可以利用其进行数据增强。
fit_generator函数各参量意义:
generator:生成器函数,输出应该是形为(inputs,target)或者(inputs,targets,sample_weight)的元组,生成器会在数据集上无限循环
steps_per_epoch: 顾名思义,每轮的步数,整数,当生成器返回steps_per_epoch次数据时,进入下一轮。
epochs :整数,数据的迭代次数
verbose:日志显示开关。0代表不输出日志,1代表输出进度条记录,2代表每轮输出一行记录
validation_data:验证集数据.
.fit_generator函数假定存在一个为其生成数据的基础函数。
该函数本身是一个Python生成器。Keras在使用.fit_generator训练模型时的过程:
(1)Keras调用提供给.fit_generator的生成器函数
(2)生成器函数为.fit_generator函数生成一批大小为BS的数据
(3).fit_generator函数接受批量数据,执行反向传播,并更新模型中的权重。重复该过程直到达到期望的epoch数量(设定的epoch总数)
需要在调用.fit_generator时提供steps_per_epoch参数(.fit方法没有这样的参数)。
为什么我们需要steps_per_epoch?
请记住,Keras数据生成器意味着无限循环,它永远不会返回或退出。
由于该函数旨在无限循环,因此Keras无法确定一个epoch何时开始的,并且新的epoch何时开始。
因此,我们将训练数据的总数除以批量大小的结果作为steps_per_epoch的值。一旦Keras到达这一步,它就会知道这是一个新的epoch。
"""
(2)预测图片代码及流程(predict.py)
1、图片经过ResNet,FPN,classsubnet和boxsubnet后输出预测结果
但是这个预测结果还需要进行解码才能使用
2、预测结果的解码
我们通过对每一个特征层的处理,可以获得三个内容,分别是:
(1)num_priors x 4的卷积用于预测该特征层上每一个网格点上每一个先验框的变化情况。
(2)num_priors x num_classes的卷积用于预测该特征层上每一个网格点上每一个预测框对应的种类。
(3)每一个有效特征层对应的先验框对应着该特征层上每一个网格点上预先设定好的9个框。
我们利用 num_priors x 4的卷积与每一个有效特征层对应的先验框获得框的真实位置。
每一个有效特征层对应的先验框就是,如下图所示的作用:
每一个有效特征层将整个图片分成与其长宽对应的网格,如P3的特征层就是将整个图像分成75x75个网格;然后从每个网格中心建立9个先验框,一共75x75x9个,50625个先验框。

先验框虽然可以代表一定的框的位置信息与框的大小信息,但是其是有限的,无法表示任意情况,因此还需要调整,Retinanet利用4次256通道的卷积+num_priors x 4的卷积的结果对先验框进行调整。
num_priors x 4中的num_priors表示了这个网格点所包含的先验框数量,其中的4表示了框的左上角xy轴,右下角xy的调整情况。
Retinanet解码过程就是将对应的先验框的左上角和右下角进行位置的调整,调整完的结果就是预测框的位置了。
当然得到最终的预测结构后还要进行得分排序与非极大抑制筛选(同个区域可能有很多目标检测都符合置信度的要求,为了防止框的重叠(重复),要筛选出同一区域同一种类得分最大的框。)这一部分,这也基本上是所有目标检测通用的部分。
1、取出每一类得分大于confidence_threshold的框和得分。
2、利用框的位置和得分进行非极大抑制。
预测部分修改之后的代码:
from keras.layers import Input
from retinanet import Retinanet
import tensorflow as tf
from PIL import Image
import os
#import datetime
import time
#config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True))
#sess = tf.compat.v1.Session(config=config)
#程序计时器,启动计时器
start = time.clock()
retinanet = Retinanet()
#i=0
#while i<1:
path = 'F:\\retinanet-keras-master4\\img'
#print(os.listdir(path))
for picture in os.listdir(path):
#img = input('Input image filename:')
img = picture #此处即为图片名
#path,imgname = os.path.split(img)
try:
image = Image.open("img\\"+img)
except:
print('Open Error! Try again!')
continue
else:
# 打开一个文件,把该图片的运行结果写入文件
f = open(r"F:\retinanet-keras-master4\newfile.txt", "a")
f.write(img+"\n")
r_image,rebar,coil,brickwork = retinanet.detect_image(image)
print(r_image, rebar, coil, brickwork)
f.write("rebar:"+str(rebar)+"\n")
f.write("coil:"+str(coil)+"\n")
f.write("brickwork:"+str(brickwork)+"\n")
# 关闭打开的文件
f.close()
r_image.show()
retinanet.close_session()
#计算启动时间和结束时间的时间差
end = time.process_time()
print('运行时间 : %s 秒'%(end-start))
(3)数据增强部分
似乎在这个文件里没有数据增强部分,只是在每一轮开始前shuffle了一下改变图片次序。
4、训练过程及预测过程
训练过程
(1)首先将训练集的图片和标签分别放在VOC2007文件夹下的JPEGImages文件夹和Annotations文件夹下,这边要注意的是,训练图片的文件名和其对应的标签文件的文件名要相同。而且命名的时候不要出现空格,否则第二步运行的时候就会出错。
(2)运行同一个文件夹下的voc2retinanet.py文件。在运行之前需要将标签文件的路径和生成的文件的保存路径改成自己对应文件夹的路径,而且生成的文件应保存在ImageSets下的Main文件夹中。运行之后会生成test.txt/train.txt/trainval.txt/val.txt。

(3)接着运行voc_annotation.py文件。只需要将类别名改为自己需要的类别名即可。运行后会生成2007_test.txt/2007_train.txt/2007_val.txt三个文件。
(4)在训练前还需要修改model_data里面的voc_classes.txt文件,需要将classes改成自己的classes。如下图是我的classes文件里的类别。
(5)最后就是运行train.py文件。运行之前需要把类别数NUM_CLASSES改为自己的类别数,下面的图片输入尺寸也可以改,还有再下面的测试数据集中验证集的比例也可以改。不过我只改了类别数,其他都没改。

预测过程
预测过程就简单许多了,只需要运行predict.py文件即可。原博主提供的代码是需要我们预先在img文件夹中存入要测试的图片,之后运行预测文件的时候要人为输入图片的路径和名称,就能跳出检测后的图片。不过一次只能检测单张图片。但是验收时需要连续测试900张图片,所以我在predict.py中加入了循环读取和将结果写入新文件的程序,并把一些图片显示的不必要的部分删去。运行前把900张图片放入img文件夹,运行predict.py文件之后就可以在newfile.txt中看到每张图片的所有预测结果。
5、网络训练调参过程及结果
(1)调整的参数及对应参数作用
我们在调参的时候调整了如下参数的值:
batch size、epoch、learning rate、置信度、patience、clipnorm。
batch size:训练时每一批处理的图片数。这个参数主要受电脑的显存资源牵制。我用本机的GPU进行训练的时候,batchsize不能大过6,而且当我把batchsize调整到2时,训练到参数解冻的时候还是会内存溢出。即使是在Colaboratory在线进行训练的时候,batchsize一般也只调到8,否则还是会在解冻参数后内存溢出。一般来说,解冻前的batch size都会比解冻后的batch size来得大。而且batch size不能设置得过小,否则处理一个batch,网络都学不到什么东西,容易引起走偏“振荡”(因为受个体影响太明显,无法确认下降的大方向)。此外,有博主说,将batch size设置为2的次方有利于GPU进行高效运算。
batch size设置大的好处
1)内存的利用率提高了,大矩阵乘法的并行化效率提高。
2)跑完一次epoch(全数据集)所需迭代次数减少,对于相同的数据量的处理速度进一步加快。
3)一定范围内,batchsize越大,其确定的下降方向就越准,引起训练震荡越小。
坏处:容易内存溢出
总结:
1)batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。
2)随着batchsize增大,处理相同的数据量的速度越快。
3)随着batchsize增大,达到相同精度所需要的epoch数量越来越多。
4)由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。 5)由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
6)过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。
【batch size设置技巧参考资料】https://blog.csdn.net/zqx951102/article/details/88918948
epoch:每次处理完全部测试集图片就算一个epoch。一般epoch我都是设置20 25 50这样。我们的程序最开始是有部分参数被冻结不参与梯度下降更新的,几个轮次完之后才解冻,全部参数一起参与更新。我一般设置epoch1=epoch2(意思是冻结训练的总轮数与解冻训练的总轮数相等),不过我们这么多次都没有一次是跑到最后的,都在中间某一回合就early stopping了。
learning rate:初始学习率调大一些可以提高收敛速度,且有利于跳出局部最优解。
置信度:置信度关系到先验框的筛选,我们初始设置的置信度是0.5,后面改到0.7发现效果并没有更好,后来尝试改到0.6,发现这样的效果还是比较好的。对于置信度我们就调整了这两次,之后就没调整过。
patience:这是为了防止过拟合而设置的参数。当发现有patience个世代的val_loss没有下降,则会认为已经达到过拟合点,选择提前结束本轮的训练,即达到early stopping。
clipnorm:我们设置的初始学习率为10^-4,clipnorm参数帮助进行梯度裁剪,防止梯度下降导致越过最低点
梯度范数缩放:就算loss的求导值很大,但为了保证稳定,一次梯度下降不会过多,我们设置一次的下降值不会超过clipnorm(0.001)
有一个问题一直没有解决,就是为什么基于自己训练好的权重继续训练效果并不好
我们在训练过程中经常发生内存溢出还有early stopping的情况,并且常常觉得训练得并不够,于是就想在目前最好的模型的基础上进行训练,但是效果往往并不好,常常loss反而增大了,而且不收敛了。取出其中的权值文件进行测试,效果也不是很好。这个问题一直没有解决,因此我们这次试用的预训练权重都是提供的别的COCO数据集上的预训练权重。
训练阶段补充对比:
我们后面其实还实现了EfficienDet-D4和YOLOv4两个网络,在训练的时候我们发现这三个网络还是有很大差别的。
EfficienDet-D4收敛速度很快,loss下降的速度非常快。(4位数-->2位数-->1位数-->小数),训练轮次少即可得到很高的精度,loss在0.0几。
YOLOv4初始的loss非常大,且下降的速度明显慢于EfficienDet-D4,在loss到50多的时候,变化很奇怪,下降特别慢,几乎要收敛,如下图所示。因为YOLOv4并没有训练出很满意的结果,所以最终也并没有用其去验收。

而对于Retinanet,算是适中,初始loss在10以内,第二轮就降到了3左右,之后就平缓下降,等到early stopping的时候loss大概在0.8。
(2)过程记录
我们调整的参数主要是上面提到的那几个,但是因为受到内存溢出的影响,所以batch size和epoch动得相对较少,其他的参数动得比较多,具体搭配已经记不清了,所以下面的记录就只写了batch size和epoch。
(1)最开始:使用CPU训练 Batch size = 2 epoch1=10 epoch2=40,训练速度太慢,只训练得到第13轮的模型,试了几张图片,发现检测效果还是挺好的。这个模型其实一直保留到最后,因为确实效果不错。
(2)开始使用GPU加速训练,但因为显存不够总是训练到第十轮就终止了。(下一大轮是参数解冻,解冻后参数大大增加,GPU还是无法负荷) 我调整Batch size最大只能到6,这些只跑到第10轮的模型效果都很差。冻结了的参数还是需要参与训练才能到达一个比较好的地方。
(3)学习使用Colab 在线用GPU进行训练
第一次:Batch size=16 epoch1=20 epoch2=80 跑到第33轮出现early stopping ,ep33loss=0.886
该模型的检测精度高,但对砌体的检测比较有问题。
程序设定有6个世代不下降的时候,会认为到了early stopping的地步,停止 训练
第二次:Batch size=10 epoch1=20 epoch2=60
这次的loss的降低速度比上次要快一些,跑到第39轮出现early stopping, ep39loss=0.800,其效果还是很好,比上一次的更加精确。但是对于砌体的检测仍然比其他两类的检测效果要来的差(主要表现在把两个视为一个)
(3)最终模型选择
我们最终根据loss以及val_loss的值,取出loss最小的,即2ep038-loss0.800-val_loss0.746.h5的权值文件。这是loss和验证集上val_loss综合最优的。后面验收的时候测出来AP值为61,但是error rate有三十多。还是参数调得不够好。
二、扩展
1、EfficienDet-D4的实现
我们在实现了Retinanet之后,通过网上很多资料都知道它速度慢的毛病。比如其与YOLOv3的对比:YOLOv3的速度非常快,比起YOLOv3,Retinanet大约需要3.8倍的时间来处理一张图像。而且YOLOv3准确度也不低。有博主测试显示YOLOv3处理一张图片50多ms ,而Retinanet需要花费的时间则为198ms。既然已经入门完毕,那我们就再看看有没有比较新的,更高效的算法。后来我们看到了下面这张图:发现EfficienDet的精度很高啊,而且从横坐标来看似乎处理速度也很快。我们去看了相关的博客还有其论文笔记,发现这就是一个追求高效的网络,这从它的命名EfficientDet其实就能看出来了。当然我们也知道很多小组都在使用YOLOv5做,甚至使用的同一个代码,而YOLOv5算是最新提出的目标检测算法了吧,性能肯定很好。
这个时候的心理就有点奇怪了,就觉得,既然大家都用这个,那我们就不要跟他们用一样的了..用一样的网络的话岂不是所有时间都花在调参上了,而调参又是一门“玄学”,这既不稳妥也不符合我们的想法(我们想着是把时间用到入门检测算法上 而不是把时间花在调参上)大概是有点想出奇制胜的想法,又觉得别人用什么就跟着用什么没意思,所以我和赵同学便毅然决然地开始学习实现EfficienDet了。
综合速度和精度还有参数数量,我们选择的是EfficienDet-D4


EfficienDet基本结构
我觉得其实EfficienDet是Retinanet性能的升级版本。因为EfficienDet的整体结构就是以Retinanet为Baseline创建(特征提取+特征加强+预测部分),但对特征提取和特征融合强化部分的进行了优化。
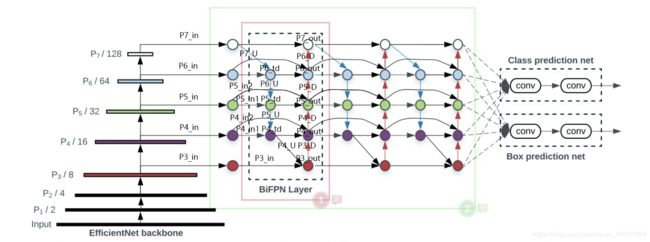
EfficienDet与Retinanet的结构差别:
(1)EfficienDet以EfficientNet作为主干特征提取网络
(深度、宽度、分辨率的最优解,寻求一个最好的平衡,可以提取出最好的特征)
卷积神经网络精度提升的方法
- 网络深度的增加,典型的如resnet,就是通过残差网络的堆叠,增加网络层数,以此来提升精度。
- 网络宽度的增加,通过增加每层网络的特征层数,提取更多的特征,以此来提升精度。
- 图像分辨率的增加,分辨率越高的图像,所能获取的信息越多,网络能够学习到更多的特征,从而提升精度。
EfficientNet特点
【参考资料】https://blog.csdn.net/qq128252/article/details/110953858
历史的实验经验表明,对于卷积神经网络的提升,着重点在于网络深度,网络宽度,分辨率这三个维度。因此,efficientnet应运而生,efficientnet结合了这三个优点,很好的平衡深度、宽度和分辨率这三个维度,通过一组固定的缩放系数统一缩放这三个维度。举个栗子,如果我们需要使用 2 N 2^N 2N的计算机资源,我们可以对网络深度放大 α N α^N αN,对网络宽度放大 β N β^N βN,对分辨率放大 γ N γ^N γN。

如上图,(a)是baseline基准网络。(b)是网络宽度的缩放。(c)是网络深度的缩放。(d)是分辨率的缩放。(e)是平衡综合网络深度,网络宽度,分辨率三个维度。
其中,baseline基准网络是通过网络结构搜索得到,基于baseline基准网络进行放大得到的一系列网络就是EfficientNet网络。
如下图,是EfficientNet和其他网络的比较,我们可以看出EfficientNet相对于其他网络,有了质的突破。

(2)中间特征加强是BiFPN layer(双向特征金字塔)简单来说就是先上采样融合后下采样融合,提取、融合特征,可串联好多这样的子模块,最后提取到具有高语义信息的特征。经过特征强化输出的每个特征层后也都连着回归子网和分类子网。class subnet和box subnet与Retinanet是相似的。并且根据BiFPN layer单元模块数的不同,可以分为B0,B1,B2......B7,对应的网络就是EfficienDet-D0到EfficienDet-D7。
训练过程记录:
(1)预训练权重是b4权重文件(即从EfficientNet的参数开始训练),使用全部数据集。
epoch1=50 epoch2=25 Batchsize = 4 跑到第47轮的时候出现early stopping直接进入下一轮,进入下一轮后一开始就发生内存溢出了,取中间的某个模型进行测试,效果还不错。但是预测速度并没有Retinanet快。
(2)使用d1预训练权重文件,使用全部数据集epoch1=25 epoch2=25 Batchsize = 4,仍然是跑到解冻参数部分就内存溢出了。取第25轮的模型,效果还可以,略逊于上一次提取的模型。
因为内存溢出好几次,我们没有什么更好的办法,batch size也不宜再调小(一批太少的话学不到什么新东西),所以决定把输入训练的图片减少。
(3)预训练权重是b4权重文件 只用第二批数据集
epoch1=25 epoch2=25 Batchsize = 4
这次终于在25轮之后没有内存溢出,跑到了38轮才early stopping 但预测效果还是没有第一次的好(因为我们在测试的时候选择的图片既有第一批数据集的也有第二批数据集的,而且还有自己拼接的两批数据集的图片合在一起的测试图片)尤其对于钢筋的数据来说,由于第二批的数据集和第一批的数据集还是有些差别,所以检测效果会差别有点明显。还是应该使用全部数据集进行训练。
我们检查了GPU的分配情况,发现分配正常,free GPU 将近15G 但是跑epoch1=2 epoch2=2 Batchsize=2的时候,输入全部的图, 还是在第二轮解冻参数后内存溢出。这是不太理解的地方,按理说16G的显存应该完全够我们使用。
后来有一次我们查找资料看到了一篇华科的硕士毕业论文,里面的batchsize也只设置为4,说是图片很多而且分辨率很高,所以数据量太大,只能设置为4。我去查看了一下我们的训练集的图片,有一些图片的分辨率确实很高。但是内存溢出这个问题确实大大限制了我们的调参训练。
但是不知道为何,EfficienDet的检测精度虽然很高,但是在速度上的优势并没有看出来,还不如Retinanet的速度。后面在网上查了一下,发现很多都是用Pytorch实现的EfficienDet,检测速度都很快。
后来我们开始思考,也查资料发现用Keras实现速度会比较慢,如果用Pytorch或者TensorFlow就会运行得快一些,但是后面没有时间再去从头好好整了,所以就放弃了使用其他的深度学习框架来搭建了。
2、YOLOv4的实现
其实这并没有什么可以讲的,无非是我们在发现EfficienDet的运行速度不符合预期后,为了验收不至于太难看而加急实现的,连网络的结构还没摸清就开始火急火燎按着步骤去训练了。当然还是不太顺利,之前在对比三个网络的训练过程的时候就提到过它的loss在50左右的时候一直不太降得下来,后来时间不够,我们也就没继续了。
3、对于使用第一批提供的标签
还记得之前老师提示过要把注意力放在计数上面。其实目标检测的计数思路是实现是对筛选出的目标框进行计数,但标签里给了计数的数量。计数这一信息应该怎么训练?或者说这个信息要怎么利用呢?
之后有一天我有了这样的想法:计数其实可以作为损失评估的一部分。损失函数或许可以改改?但是又觉得这改动太大了实在不确定。我觉得通过训练时给出目标物体的数量可以反过来把精度较低的框去掉,这样就能进一步保证计数的精度。相当于多一个维度作为反馈部分,应该是有利于计数精度的提升的。但最终我们并没有去尝试,一个是时间问题,还有一个是不太敢去动损失函数(毕竟Focal Loss相比原来稍微加了个系数项效果就差这么多了)
4、一点想法
目标检测算法的改进有时候就是一个小创新点(一个小trick)但是能起到很好的改进。一个网络性能好不好,感觉有点‘细节决定成败’的意味,从focal loss这个损失函数的小改进就能感受到。
5、之后想做的
想看看获奖同学的YOLOv5的代码,对于调参向他们取取经,毕竟YOLOv5的性能是真的好。虽然自己不喜欢调参,因为不确定性太高,似乎很不可控,而且硬件资源又捉襟见肘。不过调参还是相当重要的一部分,还是得面对。感受就不多说了,很多都在博客里面啰嗦过了。只能说有点后悔又觉得没什么好后悔的吧,一方面觉得如果自己一开始也去用YOLOv5,测试结果肯定比现在好,课题的分数肯定会比现在高;一方面又觉得我们做的工作可能比其他组的都要多(少了一些调参的时间,我和小赵跑去看代码,从这个函数调到另一个文件的某个函数,大致疏通整个流程),我觉得可能真实收获还更多,不知道算不算在自我安慰,不过这三篇博客写下来我觉得还是成就感满满的!
最后这一篇因为要赶deadline所以写得很匆忙,要是哪里有不对的,希望大家可以指出,一起交流啊~