响应式在前端领域已经变得十分流行,很多主流框架都采用响应式来进行页面的展示刷新。本文主要是探索一下响应式在移动端Android上的一些实践,包括对响应式思想的理解,以及目前Android上实现响应式的一些手段,最后聊聊响应式在Android开发上的一些应用。如果你也在传统的开发模式过程中随着项目代码的增加以及业务逻辑复杂度的增加发现诸如大量的繁琐回调、不可控的内存泄漏、空指针等问题,希望本文的一些分享可以给你带来一点点新的选择。
本文主要包括以下几部分:
一. 响应式编程思想
二. 响应式的实现手段:订阅发布模式、LiveData、RxJava
三. 响应式的应用:MVVM、事件总线
四. 总结
一. 响应式编程思想
概念:响应式编程是一种通过异步和数据流来构建事物关系的编程模型。
相信大家看到这句话和我差别不大,一定还是不大明白这句话的含义,那么如何更加通俗易懂的理解,是一个问题,那么我们一步步来理解。
1. 响应式的由来
我们先来聊一聊响应式的由来,对于它的由来,我们可能需要先从一段常见的代码片段看起:
int a=1;
int b=a+1;
System.out.print(“b=”+b) // b=2
a=10;
System.out.print(“b=”+b) // b=11
上面是一段很常见的代码,简单的赋值打印语句,但是这种代码有一个缺陷,那就是如果我们想表达的并不是一个赋值动作,而是b和a之间的关系,即无论a如何变化,b永远比a大1。那么可以想见,我们就需要花额外的精力去构建和维护一个b和a的关系。
而响应式编程的想法正是企图用某种操作符帮助你构建这种关系。它的思想完全可以用下面的代码片段来表达:
int a=1;
int b <= a+1; // <= 符号只是表示a和b之间关系的操作符
System.out.print(“b=”+b) // b=2
a=10;
System.out.print(“b=”+b) // b=11
这就是是响应式的思想,它希望有某种方式能够构建关系,而不是执行某种赋值命令。
至此你可能不禁要问,我们为什么需要构建关系的代码而不是命令式的代码呢?如果你翻一翻自己正在开发的APP,你就能看到的每一个交互的页面其实内部都包含了一系列的业务逻辑。而产品的每个需求,其实也对应了一系列的业务逻辑相互作用。总之,我们的开发就是在构建一系列的业务逻辑之间的关系。你说我们是不是需要构建关系的代码?
说回响应式,前期由于真实的编程环境中并没有构建关系的操作符,主流的编程语言并不支持这种构建关系的方式,所以一开始响应式主要停留在想的层面,直到出现了Rx和一些其他支持这种思想的框架,才真正把响应式编程引入到了实际的代码开发中。
Rx是响应式拓展,即支持响应式编程的一种拓展,为响应式在不同语言中的实现提供指导思想。
2. 什么是响应式编程
说完了了响应式的由来,我们就可以谈谈什么是响应式编程了。
响应式编程是一种通过异步和数据流来构建事务关系的编程模型。这里每个词都很重要,“事务的关系”是响应式编程的核心理念,“数据流”和“异步”是实现这个核心理念的关键。为了帮助大家理解这个概念,我们不妨以APP初始化业务为例来拆解一下这几个词。
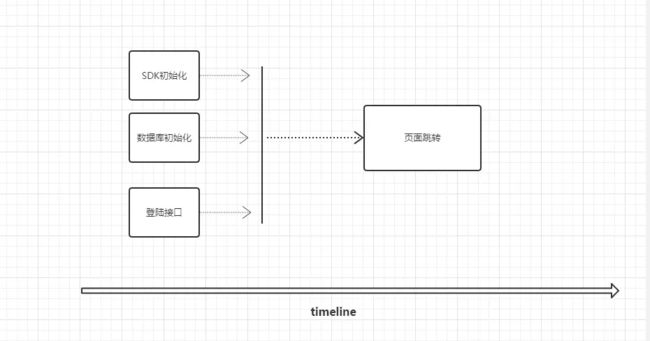
3. 事务的关系
- 事务 是一个十分宽泛的概念,它可以是一个变量,一个对象,一段代码,一段业务逻辑.....但实际上我们往往把事务理解成一段业务逻辑(下文你均可以将事务替换为业务逻辑来理解),比如上图中,事务就是指
APP初始化中的四个业务逻辑。 - 事务的关系 这种关系不是类的依赖关系,而是业务之间实际的关系。比如
APP初始化中,SDK初始化,数据库初始化,登陆接口,他们共同被跳转页面业务所依赖。但是他们三个本身并没有关联。这也只是业务之间较为简单的关系,实际上,根据我们的需求App端会产生出许多业务之间错综复杂的关系。
4. 数据流
数据流只是事务之间沟通的桥梁。
比如在APP初始化中,SDK初始化,数据库初始化,登陆接口这些业务完成之后才会去安排页面跳转的操作,那么这些上游的业务在自己工作完成之后,就需要通知下游,通知下游的方式有很多种,其中最棒的的方式就是通过数据(事件)流。每一个业务完成后,都会有一条数据(一个事件)流向下游,下游的业务收到这条数据(这个事件),才会开始自己的工作。
但是,只有数据流是不能完全正确的构建出事务之间的关系的。我们依然需要异步编程。
5. 异步
异步编程本身是有很多优点的,比如挖掘多核心CPU的能力,提高效率,降低延迟和阻塞等等。但实际上,异步编程也给我们构建事务的关系提供了帮助。
在APP初始化中,我们能发现SDK初始化,数据库初始化,登陆接口这三个业务本身相互独立,应当在不同的线程环境中执行,以保证他们不会相互阻塞。而假如没有异步编程,我们可能只能在一个线程中顺序调用这三个相对耗时较多的业务,最终再去做页面跳转,这样做不仅没有忠实反映业务本来的关系,而且会让你的程序“反应”更慢
总的来说,异步和数据流都是为了正确的构建事务的关系而存在的。只不过,异步是为了区分出无关的事务,而数据流(事件流)是为了联系起有关的事务。
6. APP初始化应该怎么写
许多使用Rx编程的同学可能会使用这种方式来完成APP的初始化。
Observable.just(context)
.map((context)->{login(getUserId(context))})
.map((context)->{initSDK(context)})
.map((context)->{initDatabase(context)})
.subscribeOn(Schedulers.newThread())
.subscribe((context)->{startActivity()})
其实,这种写法并不是响应式的,本质上还是创建一个子线程,然后顺序调用代码最后跳转页面。这种代码依然没有忠实反映业务之间的关系。
在我心目中,响应式的代码应该是这样的:
Observable obserInitSDK=Observable.create((context)->{initSDK(context)}).subscribeOn(Schedulers.newThread())
Observable obserInitDB=Observable.create((context)->{initDatabase(context)}).subscribeOn(Schedulers.newThread())
Observable obserLogin=Observable.create((context)->{login(getUserId(context))})
.map((isLogin)->{returnContext()})
.subscribeOn(Schedulers.newThread())
Observable observable = Observable.merge(obserInitSDK,obserInitDB,obserLogin)
observable.subscribe(()->{startActivity()})
大家应该能很明显看到两段代码的区别,第二段代码完全遵照了业务之间客观存在的关系,可以说代码和业务关系是完全对应的。说白了还是低耦合, 分化了实现的步骤, 功能更独立, 自己的事情自己做, 最后在通过拼接(1⃣️将事务作为对象 2⃣️将事务和结果进行绑定),完成需求。
如果一定要追求链式,可以这样写:
Observable.just(context)
.observableOn(Schedulers.newThread())
.map((context)->{login(getUserId(context))})
.observableOn(Schedulers.newThread())
.map((context)->{initSDK(context)})
.observableOn(Schedulers.newThread())
.map((context)->{initDatabase(context)})
.observableOn(AndroidSchedulers.mainThread())
.subscribe((context)->{startActivity()})
那么这带来了什么好处呢?当initSDK,initDB,login都是耗时较长的操作时,遵照业务关系编写响应式代码可以极大的提高程序的执行效率,降低阻塞。
理论上讲,遵照业务关系运行的代码在执行效率上是最优的。
7. 为什么引入响应式编程
对响应式编程有了一些了解之后,我知道马上会由很多人跳出来说,不使用这些响应式编程我们还不是一样开发APP?
在这里我希望你理解一点,当我们用老办法开发APP的时候,其实做了很多妥协,比如上面的APP初始化业务,三个无关耗时操作为了方便,我们往往就放在一个线程环境中去执行,从而牺牲了程序运行的效率。而且实际开发中,这种类似的业务逻辑还有很多,甚至更加复杂。假如不引入响应式的思路,不使用Rx的编程模型,我们面对这么些复杂的业务关系真的会很糟心。假如你做一些妥协,那就会牺牲程序的效率,假如你千辛万苦构建出业务关系,最终写出来的代码也一定很复杂难以维护。所以,响应式编程其实是一种更友好更高效的开发方式。
根据个人经验来看,响应式编程至少有如下好处:
- 在业务层面实现代码逻辑分离,方便后期维护和拓展
- 极大提高程序响应速度,充分发掘CPU的能力
- 帮助开发者提高代码的抽象能力和充分理解业务逻辑
- Rx丰富的操作符会帮助我们极大的简化代码逻辑
注:
由于这篇文章讲的是响应式编程,因此更多的使用的 `Rx` 这个名称,而不是`RxJava`,
因为`RxJava`只是响应式编程在`Java`语言中的实现。
不过里面的伪代码都是使用`RxJava`来编写的,希望大家能够理解。
二. 实现响应式的手段
上面说的响应式主要还是一种编程思想,而如何来实现这样一种思想呢?当然订阅发布模式是基础,而像RxJava、LiveData等的出现,让响应式编程的实现手段变得更加的丰富。
1. 订阅发布模式
订阅发布模式是实现响应式的基础,这种模式我们都很熟悉了,主要是通过把观察者的回调注册进被观察者来实现二者的订阅关系,当被观察者notify的时候,则所有的观察就会自动响应。这种模式也实现了观察者和被观察者的解耦。
简单理解:A 是被观察者,B、C、D 是观察者。
当 A 发生变化时发出通知告知 B、C、D,
然后 B、C、D 可根据 A 发送的数据来做具体的事情。
重要作用:
解耦,也就是将观察者和被观察者解耦。
解耦的好处不用多说,设计模式中 单一职责原则
也表明我们希望每个实体(类、函数、模块等)能引起其改变的原因只有它自己,
也就是说,我们希望观察者的逻辑和被观察者的逻辑是分离的。
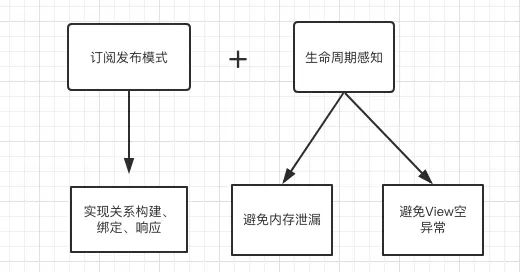
2. LiveData
LiveData是google发布的lifecycle-aware components中的一个组件,除了能实现数据和View的绑定响应之外,它最大的特点就是具备生命周期感知功能,这使得他具备以下几个优点:
- 解决内存泄漏问题。由于
LiveData会在Activity/Fragment等具有生命周期的lifecycleOwner onDestory的时候自动解绑,所以解决了可能存在的内存泄漏问题。之前我们为了避免这个问题,一般有注册绑定的地方都要解绑,而LiveData利用生命周期感知功能解决了这一问题。 - 解决常见的 View 空异常。我们通常在一个异步任务回来后需要更新
View,而此时页面可能已经被回收,导致经常会出现View空异常,而LiveData由于具备生命周期感知功能,在界面可见的时候才会进行响应,如界面更新等,如果在界面不可见的时候发起notify,会等到界面可见的时候才进行响应更新。所以就很好的解决了空异常的问题。 - 确保UI界面的数据状态。
LiveData遵循观察者模式。LiveData在生命周期状态更改时通知Observer对象,更新这些Observer对象中的UI。观察者可以在每次应用程序数据更改时更新UI,而不是每次发生更改时更新UI。 - 配置的改变。当前Activity配置改变(如屏幕方向),导致重新从
onCreate走一遍,这时观察者们会立刻收到配置变化前的最新数据。 - 共享资源。只需要一个
LocationLivaData,连接系统服务一次,就能支持所有的观察者。
LiveData的实现上可以说是 订阅发布模式+生命周期感知,对于Activity/Fragment等LifecycleOwner来说LiveData是观察者,监听者生命周期,而同时LiveData又是被观察者,我们通过观察LiveData,实现数据和View的关系构建。
LiveData是粘性的,这是你在使用前需要知道的,以免因为粘性造成一些问题,使用
EventBus的时候我们知道有一种事件模式是粘性的,特点就是消息可以在
observer注册之前发送,当
observer注册时,依然可接收到之前发送的这个消息。而
LiveData天生就是粘性的,下面会讲解为什么他是粘性的,以及如果在一些业务场景上不想要
LiveData是粘性的该怎么做。
LiveData的实现原理
单纯的贴源码,分析源码可能比较枯燥,所以下面就尽量以抛出问题,
然后解答的方式来解析LiveData的原理。
1). LiveData是如何做到感知Activity/Fragment的生命周期?
lifecycle-aware compents的核心就是生命周期感知,要明白LiveData为什么能感知生命周期,就要知道Google的这套生命周期感知背后的原理是什么,下面基于之前lifeycycle这套东西对源码进行分析总结:
首先Activity/Fragment是LifecycleOwner(26.1.0以上的support包中Activity已经默认实现了LifecycleOwner接口),内部都会有一个LifecycleRegistry存放生命周期State、Event等。而真正核心的操作是,每个Activity/Fragment在启动时都会自动添加进来一个Headless Fragment(无界面的Fragment),由于添加进来的Fragment与Activity的生命周期是同步的,所以当Activity执行相应生命周期方法的时候,同步的也会执行Headless Fragment的生命周期方法,由于这个这个Headless Fragment对我们开发者来说是隐藏的,它会在执行自己生命周期方法的时候更新Activity的LifecycleRegistry里的生命周期State、Event,并且notifyStateChanged来通知监听Activity生命周期的观察者。这样就到达了生命周期感知的功能,所以其实是一个隐藏的Headless Fragment来实现了监听者能感知到Activity的生命周期。
基于这套原理,只要LiveData注册了对Activity/Fragment的生命周期监听,也就拥有了感知生命周期的能力。从LiveData的源码里体现如下:
@MainThread
public void observe(@NonNull LifecycleOwner owner, @NonNull Observer observer) {
if (owner.getLifecycle().getCurrentState() == DESTROYED) {
// ignore
return;
}
LifecycleBoundObserver wrapper = new LifecycleBoundObserver(owner, observer);
ObserverWrapper existing = mObservers.putIfAbsent(observer, wrapper);
if (existing != null && !existing.isAttachedTo(owner)) {
throw new IllegalArgumentException("Cannot add the same observer"
+ " with different lifecycles");
}
if (existing != null) {
return;
}
owner.getLifecycle().addObserver(wrapper);
}
下面附一张当时对Google lifecycle-aware原理进行源码分析随手画的图:
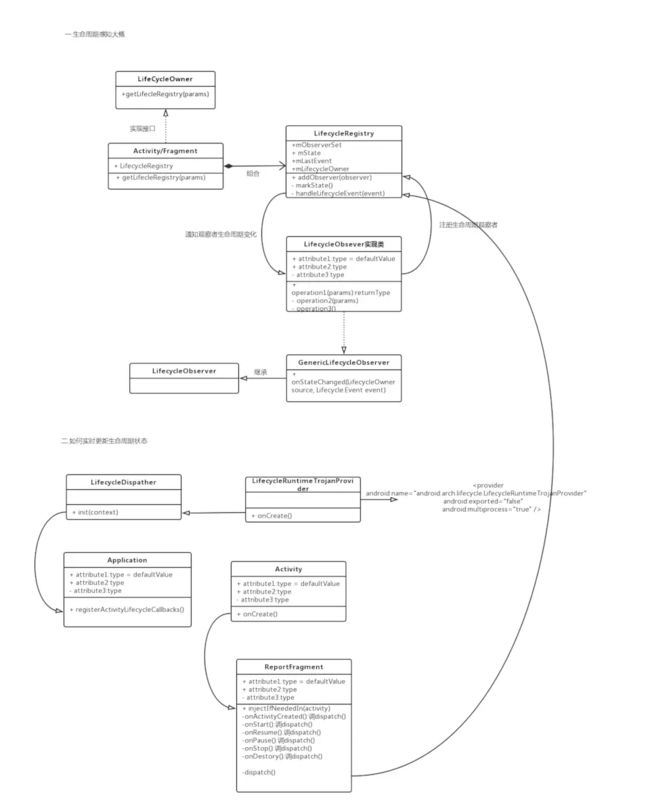
所以到这里我们基本上已经知道了生命周期感知这套东西的原理,接下来我们就可以来看看
LiveData的实现原理了,下我把
LiveData的源码抽象为一张流程图来展示,下面的其他问题都可以在这张图中找到答案:

可以看到,在
LiveData所依附的
Activity/
Fragment生命周期发生改变或者通过
setValue()改变
LiveData数据的时候都会触发
notify,但是触发后,真正要走到最终的响应(即我们注册进去的
onChanged()回调)则中间要经历很多判断条件,这也是为什么
LiveData能具有自己那些特点的原因。
2). LiveData为什么可以避免内存泄漏?
通过上面,我们可以知道,当Activity/Fragment的生命周期发生改变时,LiveData中的监听都会被回调,所以避免内存泄漏就变得十分简单,可以看上图,当LiveData监听到Activity onDestory时则removeObserve,使自己与观察者自动解绑,这样就避免了内存泄漏。
源码上体现如下:
@Override
public void onStateChanged(LifecycleOwner source, Lifecycle.Event event) {
if (mOwner.getLifecycle().getCurrentState() == DESTROYED) {
removeObserver(mObserver);
return;
}
activeStateChanged(shouldBeActive());
}
3). LiveData为什么可以解决View空异常问题?
这个问题很简单,看上图,因为LiveData响应(比如更新界面操作View)只会在界面可见的时候,如果当前见面不可见,则会延迟到界面可见的时候再响应,所以自然就不会有View空异常的问题了。
那么LiveData是如何实现:
- 只在界面可见的时候才响应的
- 如果当前界面不可见,则会延迟到界面可见的时候再响应
关于问题1,因为LiveData是能感知到生命周期的,所以在它回调响应的时候会加一个额外的条件,就是当前的生命周期必须是可见状态的,才会继续执行响应,源码如下:
private void considerNotify(ObserverWrapper observer) {
//如果界面不可见,则不进行响应
if (!observer.mActive) {
return;
}
if (!observer.shouldBeActive()) {
observer.activeStateChanged(false);
return;
}
//如果mVersion不大于mLastVersion,说明数据没有发生变化,则不进行响应
if (observer.mLastVersion >= mVersion) {
return;
}
observer.mLastVersion = mVersion;
//noinspection unchecked
observer.mObserver.onChanged((T) mData);
}
@Override
boolean shouldBeActive() {
return mOwner.getLifecycle().getCurrentState().isAtLeast(STARTED);
}
关于问题2,在LiveData中有一个全局变量mVersion,而每个observer中有一个变量mLastVersion。当我们每次setValue()修改一次LiveData的值的时候,全局的mVersion就会+1,这样mVersion就大于mLastVersion:
@MainThread
protected void setValue(T value) {
assertMainThread("setValue");
mVersion++;
mData = value;
dispatchingValue(null);
}
复制代码而当界面重新可见的时候,只要判断到mVersion大于mLastVersion,则就会进行响应刷新View,响应后才会更新mLastVersion=mVersion。
4). LiveData为什么是粘性的?
所谓粘性,也就是说消息在订阅之前发布了,订阅之后依然可以接受到这个消息,像EventBus实现粘性的原理是,把发布的粘性事件暂时存在全局的集合里,之后当发生订阅的那一刻,遍历集合,将事件拿出来执行。
而LiveData之所以本身就是粘性的,结合上面的原理图我们来分析一下,比如有一个数据(LiveData)在A页面setValue()之后,则该数据(LiveData)中的全局mVersion+1,也就标志着数据版本改变,然后再从A页面打开B页面,在B页面中开始订阅该LiveData,由于刚订阅的时候内部的数据版本都是从-1开始,此时内部的数据版本就和该 LiveData 全局的数据版本 mVersion 不一致,根据上面的原理图,B页面打开的时候生命周期方法一执行,则会进行notify,此时又同时满足页面是从不可见变为可见、数据版本不一致等条件,所以一进B页面,B页面的订阅就会被响应一次。这就是所谓的粘性,A页面在发消息的时候B页面是还没创建还没订阅该数据的,但是一进入B页面一订阅,之前在A中发的消息就会被响应。
那么有些业务场景我们是不想要这种粘性的,我们希望只有当我们订阅了该数据之后,该数据的改变才通知我们,通过上面的分析,这一点应该还是比较好办到的,只要我们订阅的时候将全局的mVersion同步到内部的数据版本,这样订阅时候就不会出现内部数据版本与全局的mVersion不一致,也就去除了粘性。我这里自定义了一个可以控制是否需要粘性的LiveData。
3. RxJava
当然我个人认为不管是链式写法,还是线程模型,异或是解决回调问题都谈不上是RxJava的核心优点,有很多人引入RxJava后项目里只是利用RxJava方便的线程模型来做简单的异步任务,其实如果只是做异步任务,有非常多种的方式可以替代RxJava。链式写法的话就更只是编码上的糖果了。如果在没有正确的理解RxJava的核心优势基础上在代码里对RxJava进行跟风式的滥用,很多时候你会发现,代码并没有变简洁,甚至有时候很简单的事情被搞的变复杂了。
我所理解的RxJava的核心优势应该是它可以对复杂逻辑进行拆分成为一个一个的Observable后,RxJava的各种操作符予这些解耦的Observable能够合理的进行再组织的能力,并且它给予了你足够丰富的再组织能力。这种分拆再组织的能力是十分强大的,只有运用好RxJava这种强大的能力,才能真正意义上使你原来非常复杂的揉在一团的逻辑代码变得清晰、简洁,本质上是因为RxJava给你提供了这种强大方便的组织能力,我觉得有点像一种编程模式,你可以放心的将复杂的逻辑拆块,最后RxJava给你提供了丰富的组织、变换、串联、控制这些块的能力,只有这个时候你才会真正觉得这是个好东西,而不应该是跟风使用,但是心里也说不清楚为什么要使用。
回到文章的主题响应式,Rxjava就不继续展开了,这篇只说关于文章主题响应式的,看一下RxJava基本使用的时候一般如下:
//step 1
Observable observable = Observable
.create(new OnSubscribe() {
@Override
public void call(Subscriber subscriber) {
subscriber.onNext("通知观察者");
subscriber.onCompleted();
} });
//step 2
Observer observer = new Observer() {
@Override
public void onCompleted() {
System.out.println("invoked in onCompleted ");
}
@Override
public void onError(Throwable e) {
System.out.println("invoked in onError ");
}
@Override
public void onNext(String str) {
Log.i("tag", "接收到消息" + str);
System.out.println("接收到消息: " + str);
}
};
//step 3
observable.subscribe(observer);
可以看到被观察者、观察者,然后通过subscribe()把他们进行绑定。当然可能不看源码的话唯一有一点疑惑的地方是:
这里notify观察者的方式是通过e.onNext(),然后就会触发Observer中的onNext。其实如果notify观察者的方式写成observer.onNext(),就非常明了了。从源码上看e.onNext()里最后调用到的就是observer.onNext(),所以就是普通的订阅发布模式。
到这里基本上可以知道,订阅发布模式是基础,LiveData和RxJava是基于订阅发布模式去实现自己不同的特点,比如LiveData的生命周期感知能力,RxJava的话自身具备的能力就更杂更强大一点。下面来看看响应式的应用,利用这些响应式手段,我们可以来做些什么,主要举两个例子。
三. 响应式的应用
1. MVVM
MVC、MVP、MVVM三者并不是说哪种模式一定优于其他模式,三者有自己各自的优缺点,主要看具体的项目和具体场景下哪种更适合你的需求,可以更加高效的提升你的项目代码质量和开发效率。
下面所阐述的MVVM的优点和缺点,都是基于利用Google lifecycle-aware Components的LiveData+ViewModel来实现MVVM的基础上来说的。当然这些优缺点都是基于我们项目中应用实践以及个人的一些看法,所以还是要结合自己的实际场景。
1). MVVM优点
目前我们产线的项目中占比最大的还是MVP,最开始说了,其实使用MVP在解决代码解耦的基础上,我们写起代码通常是顺序性思维,比较流畅,后期去维护以及代码阅读上也相对流畅,同时在实际开发中它也引起了几个主要的问题:
内存泄漏。由于
Presenter里持有了Activity对象,所以当Presenter中执行了异步耗时操作时,有时候会引起Activity的内存泄漏。
解决方案: 一个是可以将Presenter对Activity的引用设置为软引用,还有一个就是去管理你的异步耗时任务,当Activity退出时保证他们被取消掉。View空指针异常。有的时候由于各种原因,
Activity已经被回收了,而此时Presenter中要更新view的话经常就会引起view空异常问题。
解决方案: 当然最简单的解决方案就是在Presenter中每次要回调更新界面的时候都判断下View(Activity)是否为空,但是这种方式显然太过烦琐可无法避免疏漏,所以我们可以利用 动态代理 来实现代理每个更新界面的方法,自动实现在每个更新界面方法之前都判断一下view是否为空。这样之后我们就可以大胆的写代码而不会出现view空异常。大量繁琐的回调。不知道当页面足够复杂的时候你是否也体会过
Presenter中大量的回调接口,有时候这种回调多了以后,总感觉这种方式来更新界面不是非常优雅。
上面说了几个MVP的缺点,以及为了解决这些缺点,你可以做的一些事。当然大量繁琐的回调这个缺点暂时没有很好的解决方案。
而 利用LiveData来实现MVVM,刚好能解决以上说的这几个问题,上面说了LiveData的优点就是能解决内存泄漏和View空异常,所以不用做任何额外的事,MVP的前两个问题就解决了。而第三个问题,由于在MVVM中ViewModel(相当于MVP中Presenter)并不持有view的引用,而是只处理数据逻辑,所以不存在大量繁琐回调的问题,只要在Activity中构建好数据与界面的关系,利用LiveData来绑定数据与界面的响应就可以了,之后只要ViewMoedl中数据发生变化,则响应的界面就会跟着响应改变。
所以相对于MVP来说,利用LiveData来实现的这套MVVM,不仅能解决上面说的这些问题,而且使得数据与界面的解耦更加彻底,ViewModel中只负责数据的逻辑处理,所以做单元测试也十分方便。只要在Activity中构建好数据与界面响应的关系即可。
2). MVVM缺点
当然在我看来MVVM也有自己的缺点,通过全篇对响应式的探讨,应该可以知道对于响应式来说,最重要的就是关系的构建,其实对于MVVM来说一切看起来都很美好,但是如果涉及到的页面逻辑足够复杂的时候,你是否依然能够建立清晰的关系,是否能够保证构建的关系一定可靠,就显得非常重要,一但你构建的关系有问题,则就会引起bug, 而且这种问题bug的排查似乎没有顺序性思维代码的那么直接。对于代码的阅读和维护上,其他人是否能正确的理解和用好你所构建的关系,可能也是一个问题。
最后,贴上一张利用LiveData+Viewmodel实现MVVM的架构图,也就是Google Architecture Components:

2. 事件总线
说到事件总线,我们可能第一个想到的就是EventBus,他是简单的利用了订阅发布模式来实现的,上面已经说了,几种实现响应式的手段的核心都是很相似的,所以自然用RxJava、LiveData也能非常简单的实现一个事件总线。
EventBus是基于基础的订阅发布模式去实现的,基本原理的话,就是在register的时候,解析所有的注解(早期是利用反射解析,后来为了提高性能,利用编译时注解生成代码),然后将观察者注册进全局map,之后在其他地方post一个消息就可以利用tag在全局集合里找到所有对应的观察者,然后notify就可以了。
而RxJava和LiveData的核心基础就是订阅发布模式,加上他们自己的优势特点,如LiveData的生命周期感知功能,所以利用他们产生的RxBus、LiveDataBus都只要很少的代码就能实现事件总线的功能,因为LiveData具有避免内存泄漏的优点,所以比EventBus和RxBus还多一个优点就是不用解绑。
如果想深入理解请详见:
Android消息总线的演进之路:用LiveDataBus替代RxBus、EventBus
四. 总结
这是作者对响应式编程在Android上一些个人见解,包括对响应式编程思想的理解,以及对在Android上响应式编程实现手段原理的一些解读,最后是对这些工具手段的具体应用。目前市面上各种响应式层出不穷,所以我们有必要去理解他,吸收他的优点。本文的重点偏向文章的主题响应式,文中的很多点比如lifecycle-aware、RxJava等展开讲的话都能有很大的篇幅,之后有时间可以归纳成文。
Demo参考
五. 参考资料
重新理解响应式编程
《Android源码设计模式解析与实战》
响应式编程在Android 中的一些探索
Android官网Android Jetpack系列(LiveData ,ViewModel,Room等)