背景
我们公司作为一个业内领先的新闻资讯类公司,基于机器学习的推荐排序、自然语言处理、图像识别等算法能力必不可少,所以我们公司的机器学习平台也有多年的历史。之前底层资源管理一直是基于Mesos+Marathon的,但随着业务的发展,Mesos+Marathon组合由于功能有限已经不能满足业务需求,所以我们决定对底层技术进行升级。而Kubernetes(以下简称K8s)作为当下最火爆的容器编排工具,以其功能强大、根正苗红、社区活跃等优势风靡全球,已经成为很多公司的不二选择。大树底下好乘凉,所以,我们也果断选择放弃Mesos+Marathon,转而投靠K8s。
这篇文章,就以我们这两个月来在K8s平台上的建设历程为依据,为大家讲述基于K8s的机器学习平台搭建过程。由于内容较多,这个主题会分为多篇来讲,这一篇主要讲【基础环境搭建】。
由于我所用的机器安装的都是CentOS 7操作系统,所以这篇文章中描述的安装过程都是基于 CentOS 7 的,并不适用于Ubuntu、Debian 等系统。
一、准备
首先,需要准备若干台(按照自己的实际需求决定)CPU及GPU机器,其中CPU机器作为Master节点,GPU机器作为Worker节点(当然,如果你比较壕也可以用GPU机器作为Master节点)。
然后参考《使用Kubeadm搭建Kubernetes(1.13.1)集群》搭建K8s集群(按自己需求决定是否要使用高可用架构)。此处不建议在Master节点上运行机器学习任务,因为机器学习任务通常对资源需求较高,可能会导致Master节点运行缓慢甚至宕机,影响集群的稳定性。
系统环境
以下是我们在实际搭建时所用的系统环境:
| 软件 | 版本 |
|---|---|
| K8s | 1.13.1 |
| Docker | 18.09.6 |
| Nvidia-docker | 2.2.2 |
| CUDA | 10.2 |
| Nvidia/k8s-device-plugin | 1.0.0-beta |
| Nvidia-driver | NVIDIA-SMI 440.44 |
| Linux Kernel | 3.10.0-957.el7.x86_64 |
| OS | CentOS Linux release 7.6.1810 (Core) |
| GPU | Nvidia Geforce RTX 2080 Ti 家用版 |
GPU型号选用的是Nvidia Geforce RTX 2080 Ti 家用版,没有选择商用版,是因为商用版的价格是家用版的近6倍。且目前家用版在稳定性和性能方面可以满足我们的训练需求。
另外,Nvidia/k8s-device-plugin 需要依赖2.0版本以上的 Nvidia-docker。
提醒:上述软件一般建议安装最新稳定版本,因为最新稳定版本一般会对旧版本做兼容,并且功能也更加完善。而旧版本可能会出现不兼容而导致出错甚至宕机。
二、软件介绍
1、Nvidia-driver
Nvidia GPU的驱动程序。
2、CUDA
CUDA(Compute Unified Device Architecture,统一计算架构)是由 NVIDIA 所推出的并由其制造的图形处理单元(GPUs)实现的一种并行计算平台及程序设计模型。CUDA给程序开发人员提供直接访问CUDA GPUs中的虚拟指令集和并行计算组件的存储器。(摘自维基百科)
3、Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。(摘自百度百科)
4、Nvidia-docker
由于GPU属于特定的厂商产品,需要特定的驱动,Docker 本身并不支持GPU。以前如果要在 Docker 中使用GPU,就需要在 Container 中安装主机上使用GPU的driver,然后把主机上的GPU设备(例如:/dev/nvidia0)映射到 Container 中。所以这样的Docker image并不具备可移植性。
Nvidia-docker项目就是为了解决这个问题,它让Docker image不需要知道底层GPU的相关信息,而是通过启动 Container 时mount设备和驱动文件来实现的。
5、Nvidia/k8s-device-plugin
K8s 提供了Device Plugin 的机制,用于异构设备的管理场景。原理是会为每个特殊节点上启动一个针对某个设备的DevicePlugin pod, 这个pod需要启动grpc服务, 给kubelet提供一系列接口。
为了能够在K8s中管理和调度GPU,Nvidia提供了Nvidia GPU的Device Plugin。 主要功能如下:
- 公开集群每个节点上的GPU数量
- 跟踪GPU的运行状况
- 在K8s集群中运行启用GPU的容器
三、技术架构
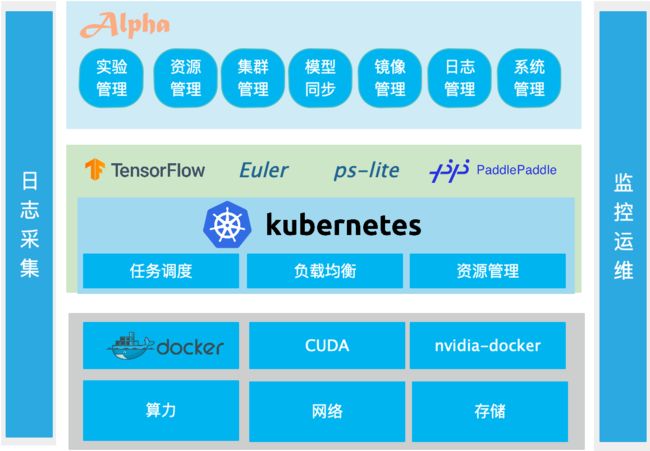
四、环境搭建
下面我们将一步步介绍上述各种软件的安装过程(由于Docker)
Nvidia-driver
GPU需要先安装驱动程序才能正常工作,一些Linux操作系统默认安装的驱动是 nouveau。 nouveau是一个自由及开放源代码显卡驱动程序,是为Nvidia的显示卡所编写,也可用于属于系统芯片的NVIDIA Tegra系列,此驱动程序是由一群独立的软件工程师所编写,Nvidia的员工也提供了少许帮助。
该项目的目标为利用逆向工程Nvidia的专有Linux驱动程序来创造一个开放源代码的驱动程序。但该驱动性能和稳定性较低,不能满足机器学习要求,所以要先禁用 nouveau,使用 Nvidia 官方推出的驱动。
1、显卡冲突
因为NVIDIA驱动会和系统自带nouveau驱动冲突,执行命令查看该驱动状态:
$ lsmod | grep nouveau
nouveau 1869689 0
mxm_wmi 13021 1 nouveau
video 24538 1 nouveau
i2c_algo_bit 13413 2 ast,nouveau
ttm 114635 2 ast,nouveau
drm_kms_helper 179394 2 ast,nouveau
drm 429744 5 ast,ttm,drm_kms_helper,nouveau
wmi 21636 2 mxm_wmi,nouveau
2、禁用nouveau
echo -e "blacklist nouveau\noptions nouveau modeset=0" > /etc/modprobe.d/blacklist.conf
之后使用 sudo reboot 命令重启机器。等重启完成后,再使用lsmod | grep nouveau命令查看nouveau是否已经禁用,如果已经禁用,该命令返回空。
3、查看显卡型号
需要依据显卡型号到 Nvidia 官网下载对应的驱动,可以使用下面的命令查看显卡型号:
$ lspci | grep -i --color 'vga\|3d\|2d'
05:00.0 VGA compatible controller: ASPEED Technology, Inc. ASPEED Graphics Family (rev 41)
18:00.0 VGA compatible controller: NVIDIA Corporation TU102 [GeForce RTX 2080 Ti] (rev a1)
3d:00.0 Ethernet controller: Intel Corporation Ethernet Connection X722 for 10GbE SFP+ (rev 09)
3d:00.1 Ethernet controller: Intel Corporation Ethernet Connection X722 for 10GbE SFP+ (rev 09)
d8:00.0 VGA compatible controller: NVIDIA Corporation TU102 [GeForce RTX 2080 Ti] (rev a1)
可以看到,我这里使用的显卡型号是 GeForce RTX 2080 Ti,然后到 https://www.nvidia.com/Download/index.aspx?lang=en-us ,按照自己的显卡型号和待安装机器操作系统信息下载对应的显卡驱动。
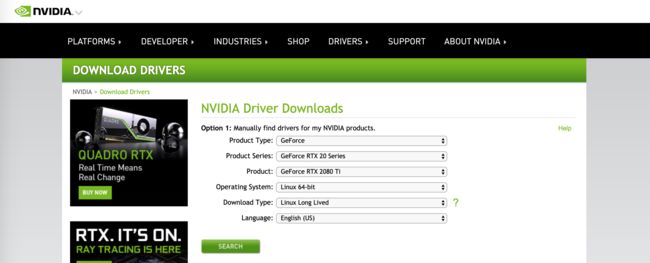
选择完成后点击“SEARCH”会跳转到下载页面,如果直接点击下载页面的“DOWNLOAD”按钮将自动下载到当前机器上,也可以通过点击鼠标右键,在菜单中选择“复制链接地址”得到文件下载路径,然后在待安装机器上使用wget命令进行下载。
在笔者写这篇文章时,最新的 Nvidia-driver 版本是440.44,下载后得到的文件名称是NVIDIA-Linux-x86_64-440.44.run。
4、安装驱动
驱动的安装有两种形式,一种是通过图形页面进行引导式安装,但这种形式不适合大规模批量部署。所以,我采用了另一种静默安装的形式,命令如下:
sudo sh NVIDIA-Linux-x86_64-440.44.run --accept-license --no-questions --silent
5、查看显卡状态
安装过程大约需要持续30s,安装完成后可以通过nvidia-smi验证是否成功,之后也可以通过该命令查询 GPU 运行状态。从下面的命令输出可以看到,在安装 Nvidia-driver 时,已经自动帮助我们安装好了 CUDA 10.2。一些旧版本的驱动安装文件中不包含 CUDA,需要自己下载安装,可以到 https://developer.nvidia.com/cuda-downloads 下载安装。
$ nvidia-smi
Fri Dec 20 22:36:28 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.44 Driver Version: 440.44 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 208... Off | 00000000:18:00.0 Off | N/A |
| 22% 33C P8 12W / 250W | 0MiB / 11019MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce RTX 208... Off | 00000000:D8:00.0 Off | N/A |
| 22% 36C P8 21W / 250W | 0MiB / 11019MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
6.指标解读
第一栏的Fan:N/A是风扇转速,从0到100%之间变动,这个速度是计算机期望的风扇转速,实际情况下如果风扇堵转,可能打不到显示的转速。有的设备不会返回转速,因为它不依赖风扇冷却而是通过其他外设保持低温)。
第二栏的Temp:是温度,单位摄氏度。
第三栏的Perf:是性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能。
第四栏下方的Pwr:是能耗,上方的Persistence-M:是持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态。
第五栏的Bus-Id是涉及GPU总线的东西,domain:bus:device.function
第六栏的Disp.A是Display Active,表示GPU的显示是否初始化。
第五第六栏下方的Memory Usage是显存使用率。
第七栏是浮动的GPU利用率。
第八栏上方是关于ECC的东西。
第八栏下方Compute M是计算模式。
注意:显存占用和GPU占用是两个不一样的指标,显卡是由GPU和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。
Docker
Docker相关的安装教程谷歌、百度上随处都是,你可以根据自己的需求选择合适的安装教程,这里就不再赘述。简单贴出一个基于yum的安装命令:
yum -y install docker
nvidia-docker
想要顺利安装 nvidia-docker 2.0,系统环境需要满足下面需求:
-
- Linux 内核版本 > 3.10
- 2.Docker 版本 >= 1.1
- 3.nvidia driver 版本 ~= 361.93
1、1.0和2.0的区别
nvidia-docker 1.0 作为Docker的一个包装,需要运行一个独立的daemon,与Docker的生态不能很好地兼容。 比如,docker-compose、docker swarm与Kubernetes,都不能很好的和 nvidia-docker 1.0 一起工作,所以 nvidia-docker 1.0 已经被官方废弃。
nvidia-docker 2.0 解决了这些问题,甚至能在非官方CUDA镜像以外的镜像工作。 nvidia-docker 1.0 是一个Volume Plugin,而nvidia-docker 2.0 则是一个Docker Runtime,机制的差异,带来了巨大的改进。
2、移除 nvidia-docker 1.0
如果你的机器上已经安装了 nvidia-docker 1.0,在安装 2.0 之前需要完全卸载 1.0,并停止和删除所有基于 1.0 运行的容器。下面是 CentOS 的删除命令:
# 如果已安装nvidia-docker,需要先进行卸载
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo yum remove nvidia-docker
3、安装 nvidia-docker 2.0
# 安装nvidia-docker2 repo
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
# 安装nvidia-docker,并重新加载docker配置
$ sudo yum install -y nvidia-docker2
$ sudo pkill -SIGHUP dockerd
# 在cuda:9.0容器中测试nvidia-smi命令
docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi
4、配置nvidia-docker2
安装后,需要配置新的Docker Runtime。 同时,也需要把默认的Runtime设为nvidia。
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime": "nvidia",
...
}
将以上内容加入/etc/docker/daemon.json文件中,然后重启Docker。
sudo systemctl restart docker
如果未进行上述配置,在启动 TensorFlow 训练时会抛出下面的错误:
ImportError: libcuda.so.1: cannot open shared object file: No such file or directory
Failed to load the native TensorFlow runtime.
k8s-device-plugin
运行NVIDIA GPU device plugin需要所有Node节点满足以下条件(如果允许Master节点部署Pod,那么Master节点也需要满足):
- nvidia driver 版本 ~= 361.93
- nvidia-docker版本 >= 2.0
- 将nvidia配置为Docker默认的runtime
- Kubernetes版本为 >= 1.11
1、安装k8s-device-plugin
在K8s平台上安装应用相对来说要简便很多,只需要有 YAML 文件即可实现快速安装。k8s-device-plugin 是以 DaemonSet 的形式运行在每一个K8s Worker节点上。在Master节点上执行下面的命令即可完成安装:
kubectl create -f https://github.com/NVIDIA/k8s-device-plugin/blob/master/nvidia-device-plugin.yml
稍等一会后,使用kubectl describe nodes查看节点信息,可以看到具有GPU的Node节点中可获取的资源已包括GPU
# 安装前
Capacity:
cpu: 8
ephemeral-storage: 51474024Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 41036940Ki
pods: 110
Allocatable:
cpu: 8
ephemeral-storage: 47438460440
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 40934540Ki
pods: 110
# 安装后
Capacity:
cpu: 8
ephemeral-storage: 51474024Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 41036940Ki
nvidia.com/gpu: 2
pods: 110
Allocatable:
cpu: 8
ephemeral-storage: 47438460440
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 40934540Ki
nvidia.com/gpu: 2
pods: 110
总结
本节我们一起学习了在 CentOS 7 环境下基于K8s的机器学习平台中基础环境的搭建过程,及所依赖的软件 nvidia-driver、nvidia-docker、Docker、k8s-device-plugin 的基本功能及安装步骤。学到这里,我们就可以开始运行我们的机器学习任务了。下一节我们将和大家一起学习如何实现日志收集及完成对任务和资源的基本监控,从而逐步将机器学习平台搭建的更加完善、易用。