1、爬虫一些知识
(1)节点选择语法
XPath使用路径表达式来选取XML文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
nodename:选取此节点的所有子节点;
/:从根节点选取;
//:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置;
.:选取当前节点;
..:选取当前节点的父节点;
@:选取属性。
(2)Requests
注:无requests即下载安装:pip install requests
response = requests.get(url)
response的常用方法:
①response.text:获取str类型的响应
②response.content:获取bytes类型的响应
③response.status_code:获取状态码
④response.headers:获取响应头
⑤response.request:获取响应对应的请求
(3)为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
headers的形式:字典
2、爬虫——提取本地html中的数据
(1)建立一个index.html文件
Title
欢迎来到王者荣耀!
 伽罗
伽罗- 苏烈
- 孙策
- 大乔
- 射手
- 坦克
- 战士
- 辅助
这是div标签
被动:伽罗的普攻与技能伤害将会优先对目标的护盾效果造成一次等额的伤害
点击跳转至百度
这是第二个div标签
(2)读取html文件——使用xpath语法进行提取
注:没有lxml即下载安装:pip install lxml
from lxml import html
# 读取html文件
with open('./index.html', 'r', encoding='utf-8') as f:
html_date = f.read()
# print(html_date)
# 解析html文件,获得selector对象
selector = html.fromstring(html_date)
# selector中调用xpath方法
# 要获取标签中的内容,末尾要添加text()
h1 = selector.xpath('/html/body/h1/text()')
print(h1[0])
# // 可以代表从任意位置出发
# //标签1[@属性=属性值]/标签2[@属性=属性值]..../text()
a = selector.xpath('//div[@id="container"]/a/text()')
print(a)
# 获取 p标签的内容
p = selector.xpath('//div[@id="container"]/p/text()')
print(p)
# 获取属性
link = selector.xpath('//div[@id="container"]/a/@href')
print(link[0])
3、爬虫——Requests
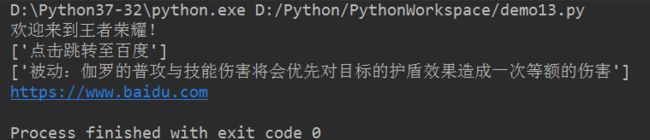
代码块1:
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response)
print(response.text) # 获取str类型的响应
print(response.content) # 获取bytes类型的响应
print(response.headers) # 获取响应头
print(response.status_code) # 获取状态码
代码块2:编码方式
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response.encoding)

import requests
url = 'https://www.taobao.com'
response = requests.get(url)
print(response.encoding)

import requests
url = 'http://www.dangdang.com'
response = requests.get(url)
print(response.encoding)

代码块3:响应头
# 200 ok、404 网页不存在、500 服务器错误、503 服务器超时
# 没有添加请求头的知乎网站
# resp = requests.get('https://www.zhihu.com')
# print(resp.status_code) # 显示400
# 使用字典定义请求头
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"}
resp = requests.get('https://www.zhihu.com', headers = headers)
print(resp.status_code)
# 显示200
4、爬虫——dangdang.com
import requests
from lxml import html
import pandas as pd
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def spider_dangdang(isbn):
book_list = []
# 目标站点地址
url = 'http://search.dangdang.com/?key={}&act=input'.format(isbn)
# print(url)
# 获取站点str类型的响应
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"}
resp = requests.get(url, headers=headers)
html_data = resp.text
# 将html页面写入本地
with open('dangdang.html', 'w', encoding='utf-8') as f:
f.write(html_data)
# 提取目标站的信息
selector = html.fromstring(html_data)
ul_list = selector.xpath('//div[@id="search_nature_rg"]/ul/li')
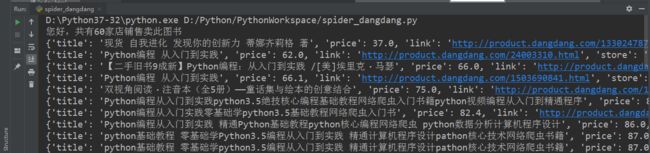
print('您好,共有{}家店铺售卖此图书'.format(len(ul_list)))
# 遍历 ul_list
for li in ul_list:
# 图书名称
title = li.xpath('./a/@title')[0].strip()
# print(title)
# 图书购买链接
link = li.xpath('./a/@href')[0]
# print(link)
# 图书价格
price = li.xpath('./p[@class="price"]/span[@class="search_now_price"]/text()')[0]
price = float(price.replace('¥', ''))
# print(price)
# 图书卖家名称
store = li.xpath('./p[@class="search_shangjia"]/a/text()')
# if len(store) == 0:
# store = '当当自营'
# else:
# store = store[0]
store = '当当自营' if len(store) == 0 else store[0]
# print(store)
# 添加每一个商家的图书信息
book_list.append({
'title':title,
'price':price,
'link':link,
'store':store
})
# 按照价格进行排序
book_list.sort(key=lambda x:x['price'])
# 遍历book_list
for book in book_list:
print(book)
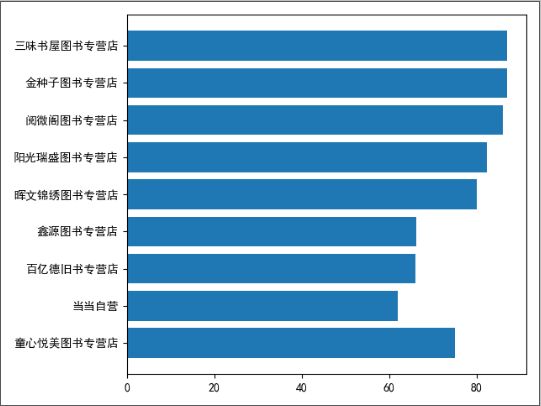
# 展示价格最低的前10家 柱状图
# 店铺的名称
top10_store = [book_list[i] for i in range(10)]
# x = []
# for store in top10_store:
# x.append(store['store'])
x = [x['store'] for x in top10_store]
print(x)
# 图书的价格
y = [x['price'] for x in top10_store]
print(y)
# plt.bar(x, y)
# plt.bar(x, y, rotation=75)
plt.barh(x, y) # 横向
plt.show()
# 存储成csv文件
df = pd.DataFrame(book_list)
df.to_csv('dangdang.csv')
spider_dangdang('9787115428028') # 调用
['童心悦美图书专营店', '当当自营', '百亿德旧书专营店', '鑫源图书专营店', '童心悦美图书专营店', '晖文锦绣图书专营店', '阳光瑞盛图书专营店', '阅微阁图书专营店', '金种子图书专营店', '三味书屋图书专营店']
[37.0, 62.0, 66.0, 66.1, 75.0, 80.1, 82.4, 86.0, 87.0, 87.0]


5、爬虫——练习
电影名,上映日期,类型,上映国家,想看人数
根据想看人数进行排序
绘制即将上映电影想看人数占比图和即将上映电影国家的占比图
绘制top5最想看的电影
import requests
from lxml import html
from wordcloud import WordCloud
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def spider_movie(isbn):
movie_list = []
url = 'https://movie.douban.com/cinema/later/{}'.format(isbn)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"}
resp = requests.get(url, headers=headers)
html_data = resp.text
selector = html.fromstring(html_data)
div_list = selector.xpath('//div[@id="showing-soon"]/div')
print('共有{}部电影即将上映'.format(len(div_list)))
for div in div_list:
# 电影名
name = div.xpath('./div[@class="intro"]/h3/a/text()')[0]
# print(name)
# 上映日期
day = div.xpath('./div[@class="intro"]/ul/li/text()')[0]
# print(day)
# 类型
type = div.xpath('./div[@class="intro"]/ul/li/text()')[1]
# print(type)
# 上映国家
country = div.xpath('./div[@class="intro"]/ul/li/text()')[2]
# print(country)
# 想看人数
div_three = div.xpath('./div[@class="intro"]/ul/li')[3]
number = div_three.xpath('./span/text()')[0]
number = str(number).replace('人想看', '')
number = int(number)
# print(number)
# 添加电影信息
movie_list.append({
'name':name,
'day':day,
'type':type,
'country':country,
'number':number
})
# 排序
movie_list.sort(key=lambda x:x['number'], reverse=True)
# 遍历
for movie in movie_list:
print(movie)
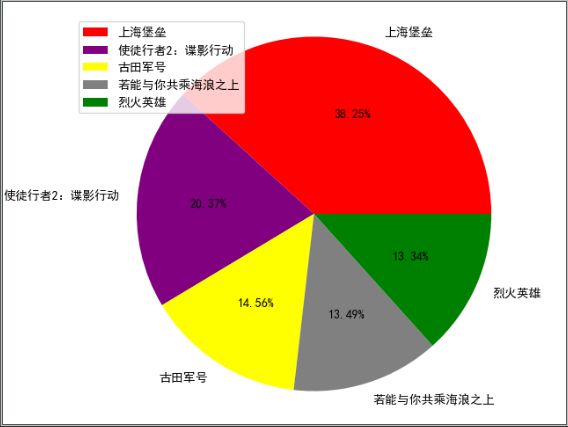
# 绘制即将上映电影最想看前五人数占比图
top5_movie = [movie_list[i] for i in range(5)]
labels = [x['name'] for x in top5_movie]
# print(labels)
counts = [x['number'] for x in top5_movie]
# print(counts)
colors = ['red', 'purple', 'yellow', 'gray', 'green']
plt.pie(counts, labels=labels, autopct='%1.2f%%', colors=colors)
plt.legend(loc=2)
plt.axis('equal')
plt.show()
# 绘制即将上映电影国家的占比图
total = [x['country'] for x in movie_list]
text = ''.join(total)
print(text)
words_list = jieba.lcut(text)
print(words_list)
counts = {}
excludes ={"大陆"}
for word in words_list:
if len(word) <= 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
print(counts)
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
numm = [] # 数量
labels = [] # 国家
for i in range(len(items)):
x, y = items[i]
numm.append(y)
if(x == "中国"):
x = "中国大陆"
labels.append(x)
plt.pie(numm, labels=labels, autopct='%1.2f%%')
plt.legend(loc=2)
plt.axis('equal')
plt.show()
# top5.png
text = ' '.join(labels)
WordCloud(
font_path='MSYH.TTC',
background_color='white',
width=800,
height=600,
collocations=False
).generate(text).to_file('top5.png')
spider_movie('chongqing')