1、Hive出现背景
Hive是Facebook开发并贡献给Hadoop开源社区的。它是建立在Hadoop体系架构上的一层SQL抽象,使得数据相关人员使用他们最为熟悉的SQL语言就可以进行海量数据的处理、分析和统计工作,
而不是必须掌握Java等编程语言和具备开发MapReduce程序的能力。Hive SQL实际上先被SQL解析器进行解析然后被Hive框架解析成一个MapReduce可执行计划,并按照该计划生成MapReduce任务后交给Hadoop集群处理。
由于Hive SQL是翻译为MapReduce任务后在Hadoop集群执行的,而Hadoop是一个批处理系统,所以Hive SQL是高延迟的,不但翻译成的MapReduce任务执行延迟高,任务提交和处理过程也会消耗时间,因此即使Hive处理
的数据集非常小(比如即MB,几十MB),在执行时也会出现延迟现象。这样Hive的性能就不能很好地和传统的Oracle数据库、MySQL数据库进行比较。Hive不能提供数据排序和查询缓存功能,也不提供在线事务处理、更不提供
实时的查询和记录级的更新,但它能很好的处理不变的大规模数据集,当然这是 和其根植于Hadoop近似线性的可扩展性分不开的。
2、Hive基本架构
作为基于Hadoop的主要数据仓库解决方案,Hive SQL是主要的交互接口,实际的数据保存在HDFS文件中,真正的计算和执行则由MapReduce完成。而它们之间的桥梁是Hive引擎。下面是架构图:
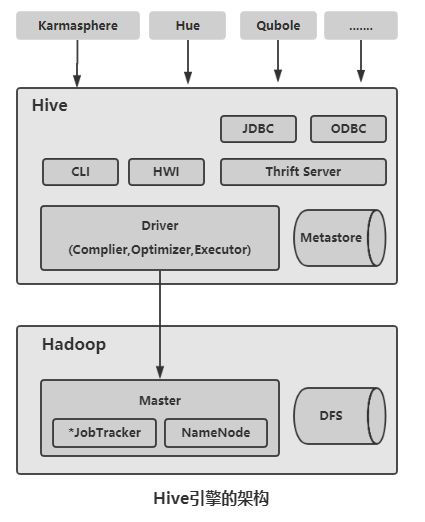
Hive组件包括UI组件、Driver组件(Complier,Optimizer和Executor)、Metastore组件、CLI(Command Line Interface, 命令行接口)、JDBC/ODBC、Thrift Server和Hive Web Interface(HWI)等。
Driver组件:核心组件,整个Hive的核心,该组件包括Complier(编译)、Optimizer(优化器)和Executor(执行器),它们的作用是对Hive SQL语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架。
Metastore组件:元数据服务组件,这个组件存储Hive的元数据。Hive的元数据存储在关系数据库里,Hive支持的关系数据库有Derby和MySQL。默认情况下,Hive元数据保存在内嵌的Derby数据库中,只能允许一个会话链接,
只适合简单的测试。实际生产中不适用,为了支持多用户会话,需要一个独立的元数据库(如MySQL),Hive内部对MySQL提供了很好的支持。
CLI:命令行接口。
Thrift Server:提供JDBC和ODBC接入的能力,用来进行可扩展且跨语言 的服务开发。Hive集成了该服务,能让不同的编程 语言调用Hive的接口。
Hive Web Interface(HWI):Hive客户端提供了一个通过网页方式访问Hive所提供的服务,这个接口对应Hive的HWI组件。
Hive通过CLI、JDBC/ODBC,或者HWI接收相关的Hive SQL查询,并通过Driver组件进行编译、分析优化,最后变成可执行的MapReduce。Hive主要组件执行过程如下图:

3、Hive SQL
Hive SQL是Hive用户使用Hive的主要工具。Hive SQL是类似于ANSI SQL标准的SQL语言,但两者又不完全相同。Hive SQL和MySQL的SQL方言最为接近,但两者之前也存在显著差异,比如Hive不支持行级数据插入、
更新和删除,也不支持事务等。
3.1、Hive关键概念
3.1.1、Hive数据库
Hive中的数据库从本质上来说仅仅是一个目录或命名空间,但是对于具有很多用户和组的集群来说,这个概念非常有用。首先,这样可以避免表命名冲突;其次,它等同于数据型数据库在的数据库概念呢,是一组表或表
的逻辑组,非常容易理解。
3.1.2、Hive表
Hive中的表(Table)和关系数据库中的table在概念上是类似的,每个table在Hive在都有一个对应的目录存储数据,如果么有指定表的数据库,那么HIve会通过{HIVE_HOME}/conf/hive-site.xml配置文件中的hive.metastore.
warehouse.dir属性来使用默认值(一般是 /user/hive/warehouse, 也可以根据实际的情况来修改这个配置),所有的table数据(不包括外部表)都保存在这个目录。
Hive分为两类,即内部表和外部表。所谓内部表(managed table)即Hive管理的表,Hive内部表的管理既包含逻辑以及语法上的,也包含实际物理意义上的,即创建Hive内部表时,数据将真实存在于表所在的目录内,删除
内部表时,物理数据和文件也一并删除。外部表(external table )则不然,其管理仅仅是在逻辑和语法意义上的,即新建表仅仅是指向一个外部目录而已。同样,删除时也不物理删除外部目录,而仅仅是将引用和定义删除。
考虑下面的语句:
CREATE TABLE my_managed_table(col1 STRING);
LOAD DATA INPATH '/user/root/data.txt' INTO table my_managed_table
上述语句会将hdfs:// user/root/data.txt 移动到Hive的对应目录hdfs://user/hive/warehouse/my_managed_table,但是载入数据的速度非常快,因为Hive只是把数据移动到对应的目录,不会对数据是否符合定义的Schema做校验,
这个工作通常在读取时候进行(即为Schema On Read)。
同时,my_managed_table使用DROP语句删除后,其数据和表的元数据被删除,不再存在,这就是 Hive managed的意思:
DROP TABLE my_managed_table;
外部表则不一样,数据的创建和删除完全由自己控制,Hive不管理这些数据,数据的位置在创建时指定:
CREATE EXTERNAL TABLE external_table(dummy STRING)
LOCATION '/user/root/external_table';
LOAD DATA INPATH '/user/root/data.txt' INTO TABLE exteranl_table;
指定EXTERNAL关键字后,Hive不会把数据移动warehouse目录中。事实上,Hive甚至不会校验外部表的目录是否存在。这使得我们可以在创建表之后再创建数据,当删除外部表时,Hive只删除元数据,而不会删除外部实际
物理文件。
选择内部表还是外部表?在大多数情况下,这两者的区别不是很明显。如果数据的所有处理都在Hive中进行,那么更倾向于选择内部表。但是如果Hive和其它工具针对相同的数据集做处理,那么外部表更合适。一种常见的模式
是使用外部表访问存储的HDFS(通常由其它工具创建)中 的初始数据,然后使用Hive转换数据并将其结果放在内部表中,相反,外部表也可以用于将Hive的处理结果导出供其它应用使用。使用外部表另一种场景是针对一个数据集,
关联多个Schema。
3.1.3、分区和桶
Hive 将表划分为分区(partition),partition根据分区字段进行。分区可以让数据的部分查询变得更快。表或者分区可以进一步被划分为桶(bucket)。桶通常在原始数据中加入一些额外的结构,这些结构可以用于高效查询。
例如,基于用户ID的分桶可以使用基于用户的查询非常快。
分区:
假设日志数据中,每条记录都带有时间戳。如果根据时间来分区,那么同一天的数据将被划分到同一个分区中。针对某一天或某几天数据的查询将会变得很高效,因为只需要扫描对应分区的文件。分区并不会导致跨度的的查询
变得低效。
分区可以通过多个维度来进行。例如,通过日期划分后,还可以根据国家进一步划分。
分区在创建表的时候使用PARTITIONED BY从句定义,该从句接收一个字段列表:
CREATE TABLE logs (ts BIGINT, line STRING) PARTITIONED BY (dt STRING, country STRING);
当导入数据到分区表时,分区的值被显式指定:
LOAD DATA INPATH '/user/root/path'
INTO TABLE logs
PATITION(dt='2001-01-01', country='GB');
文件系统上,分区作为表目录的下一级目录存在,如下图:

在实际的SQL中,灵活指定分区将大大提高其效率,如下代码将仅会扫描2001-01-01目录下的GB目录:
select ts, dt, line from logs where dt = '2001-01-01' and country='GB'
分桶:
在表或者分区中使用桶通常由两个原因:
已经为大家精心准备了大数据的系统学习资料,从Linux-Hadoop-spark-......,需要的小伙伴可以点击进入
一个是为了高效查询。桶在表中加了特殊的结构,Hive在查询的时候可以利用这些结构提高效率。例如,如果两个表根据相同的字段进行分桶,则在对这两个表进行关联的时候,可以
使用map-side关联高效实现,前提是关联的字段在分桶中出现。
二是可以高效地进行抽样。在分析大数据集时,经常需要对部分抽样数据进行观察和分析,分桶有利于高效实现抽象。
为了让Hive对表进行分桶,通过CLUSTERED BY 从句在创建表的时候指定:
CREATE TABLE bucketed_users(id INT, name STRING)
CLUSTERED BY (id) INTO 4 BUCKETS;
指定表根据id字段进行分桶,并且分为4个桶。分桶时,Hive根据字段哈希后取余数来决定数据应该放哪个桶,因此每个桶都是整体数据的随机抽样。
在map-side的关联中,两个表根据相同的字段进行分桶,因此处理左边表的bucket时,可以直接从外表对应的bucket中提取数据进行关联操作。map-side关联的两个表不一定需要完全相同bucket数量,只要成倍数即可。
需要注意的是,Hive并不会对数据是否满足表定义中的分桶进行校验,只有在查询时出现异常才会报错。因此,一种更好的方式是将分桶的工作交给Hive来完成(设置hive.enforce.bucketing属性为true即可)。
3.2、Hive数据库
创建数据库
创建数据库的完整语法如下:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_name]
[LOCATION hdfs_path]
[WITH DBPROPERTIES(property_name=property_value,...)];
例如:
hive> create database my_hive_test if not exists
commit 'this is my first hive database'
with dbproperties(‘creator’ ='mike', 'date' = '2018-08-10');
切换数据库
hive> use my_hive_test;
查看数据库
hive> describe database my_hive_test;
删除数据库
hive> drop database my_hive_test;
默认情况下,Hive不允许用户删除一个包含表的数据库。用户要么先删除数据库中的表,再删除数据库;要么在删除命令的最后加上关键字CASCADE,这样Hive会先删除数据库中的表,再删除数据库,
命令如下(务必谨慎使用此命令):
hive>drop database my_hive_test CASCADE;
已经为大家精心准备了大数据的系统学习资料,从Linux-Hadoop-spark-......,需要的小伙伴可以点击进入
查看所有数据库
hive>show databases;
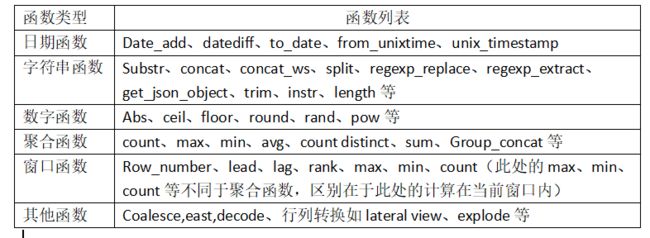
4、Hive函数列表
参考资料:《离线和实时大数据开发实战》