一、误差分析
机器学习问题的推荐解决方法:
1. 先用简单粗暴,尽管可能效果一般的算法快速实现,并使用验证集测试;
2. 绘制学习曲线,来帮助判断是增加数据集还是增加特征项来提升系统的性能;
3. 误差分析:人工核查算法在验证集上预测错误的样本,并找出这些预测错误样本的规律或特征;
4. 优化算法,并对优化效果进行量化评估,即数值评估(numerical evaluation)。
下面解释一下其中一些问题:
问:先实现简单的算法的好处?
答:一旦有了初始的算法实现,我们就可以通过算法产生的错误进行误差分析来观察算法出现了什么误差,然后以此决定如何优化;也可以使用一些数值评价指标去试验你新的想法 / 特征,并判断你的新想法是否合理有效。
问:为什么使用验证集测试,而不使用测试集测试?
答:测试误差一般用于代表模型的泛化误差。因为我们一开始选用简单快速的算法实现,所以我们需要通过测试发现算法问题,进而不断调整算法(如增减特征、调参等等)。如果用测试集测试,测试误差就不能用于代表模型的泛化误差。
下面,举例说明误差分析的过程:假设我们已经实现了简单的算法完成垃圾邮件的分类,现在用验证集测试算法。然后发现有 100 个错误分类的邮件。下面就对这 100 个错误分类邮件进行误差分析。首先对这 100 个邮件进行分类。

假设这 100 个分为 12 个药物推销邮件(Pharma),4 个假货邮件(Replica/fake),53 个钓鱼邮件(Steal passwords),31 个其他推销邮件。
你会发现你算法在判断钓鱼邮件方面表现极差,这时候我们应该花费更多的时间仔细研究钓鱼邮件,看看是否能得到更好的特征来为它们正确分类。

又假设对这 53 个钓鱼邮件分析并分类,得到其中 5 个故意拼写错误、16 个使用了不正常的邮件路由、32 个使用了不常见的标点符号。这时候,我们将算法优化重心放在处理不常见的标点符号上。
最后,误差分析后就优化算法。计算并对比算法优化前后验证误差,判断量化算法优化的效果。这种方法又称为「数值评估(numerical evaluation)」
二、不对称分类的错误率
有时很难判断误差的减少是否来表示算法的改进效果。
比如,在预测癌症,其中只有占数据集 0.5% 的患癌()样例,学习算法训练后得到误差是 1%。然而学习算法改为恒返回 ,那么此时误差减少为 0.5%。但不能说明算法得到改进。
这类问题经常发生在「不对称分类」;不对称分类指的是其中一个类在整个数据集中非常罕见。换句话,一个类占比远大于另一类的占比。
在不对称分类中,误差已不是一种好的算法度量指标。取而代之,基于查准率和召回率的 是解决不对称分析问题的算法度量指标。
2.1查准率(Precision) / 召回率(Recall)
查准率(Precision):在我们预测 的所有患者中,实际上有多少癌症。
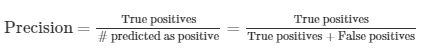
召回率(Recall):在实际患有癌症的所有患者中,我们正确检测到哪些患有癌症。

这两个指标让我们更好地了解决不对称分类问题的算法效果。其中,查准率和召回率越高越好。
之前的例子,如果我们始终返回 的算法,它的召回率 ,可见这个算法有很差的召回率,故此该算法不好。
注意:我们习惯把出现概率极小的情况 / 类设为 。
2.2查准率和召回率的权衡:
还是以癌症诊断为例, 代表患癌症。使用逻辑回归模型,一般情况下:
当 时,才预测 ;
当 时,预测 ;
如果,为了避免造成家属不必要的恐慌(毕竟被诊断为癌症对人是一种巨大的打击),我们只有在非常确信的情况下才预测患癌。此时,提高决策边界:
当 时,才预测 ;
当 时,预测 ;
提高决策边界,这会导致模型产生高查准率、低召回率;
反过来,为了不遗漏任何一个疑似癌症的患者,我们就要降低决策边界:
当 时,才预测 ;
当 时,预测 ;
降低决策边界,这会导致模型产生低查准率、高召回率。
改变决策边界,查准率与召回率变化趋势如下图所示。

注意:查准率和召回率任意一个值过高或者过低都不好。那么,如何选择决策边界,同时得到相对较高的查准率和召回率?
2.2
之前说过如果我们只有一个数值能够评估算法就好了, 但是现在对于不对称分类问题,我们需要两个数值,那么我们该如何评估算法?现在有三个相同的算法, 但是它们的决策边界不同, 对应的查准率和召回率如下图所示。我们该选择哪一个?
一般,的我们能想到的一个最简单做法是使用平均值,但是对于这三个算法均值最高的是算法,但是它的查准率只有 0.02。之前说过查准率过高或过低都不好。显然, 取平均值不是个好办法.
这个时候引进 的概念

PS:计算的查准率和召回率是验证集的查准率和召回率
有了这个权衡指标,我们就可以实现自动选择决策边界!!遍历决策边界,然后计算对应的 ,最后取能够得到 最大值的决策边界。
总结

数值评估除了常见一个数值指标:误差,还有两个数值指标:查准率和召回率。

使用 通过查准率和召回率评估算法优劣。