最长公共子序列
-
题目描述
给出1-n的两个排列P1和P2,求它们的最长公共子序列。
-
输入输出格式
输入格式:
第一行是一个数n,
接下来两行,每行为n个数,为自然数1-n的一个排列。
输出格式:
一个数,即最长公共子序列的长度
-
输入输出样例
输入样例#1:
5
3 2 1 4 5
1 2 3 4 5
输出样例#1:
3
说明
【数据规模】
对于50%的数据,n≤1000
对于100%的数据,n≤100000
转化成最长上升子序列然后 nlogn 解决。
#include
#include
#include
#include
#define MAXN 1000005
#define INF 233333333
using namespace std;
int n,a[MAXN],b[MAXN],f[MAXN],cnt;
int main() {
scanf("%d",&n);
for(int i=1,gg;i<=n;i++) {
scanf("%d",&gg);
a[gg]=i;
}
for(int i=1,gg;i<=n;i++) {
scanf("%d",&gg);
if(a[gg]>0) b[cnt++]=a[gg];
}
fill(f,f+n,INF);
for(int i=0;i 最小(最大)生成树
-
题目描述
如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出orz
-
输入输出格式
输入格式:
第一行包含两个整数N、M,表示该图共有N个结点和M条无向边。(N<=5000,M<=200000)
接下来M行每行包含三个整数Xi、Yi、Zi,表示有一条长度为Zi的无向边连接结点Xi、Yi
输出格式:
输出包含一个数,即最小生成树的各边的长度之和;如果该图不连通则输出orz
-
输入输出样例
输入样例#1:
1 2 2
1 3 2
1 4 3
2 3 4
3 4 3
输出样例#1:
7
-
说明
时空限制:1000ms,128M
数据规模:
对于20%的数据:N<=5,M<=20
对于40%的数据:N<=50,M<=2500
对于70%的数据:N<=500,M<=10000
对于100%的数据:N<=5000,M<=200000
样例解释:
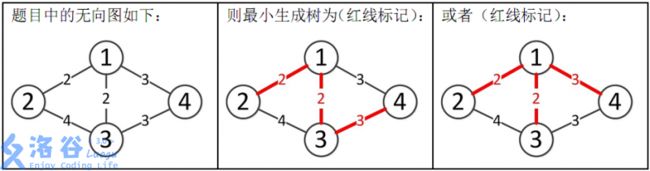
所以最小生成树的总边权为2+2+3=7
kruskal不断加小边,直到加到n-1条边图就变成了树。
#include
#include
#include
#include
#define MAXN 200005
using namespace std;
struct edge {
int u,v,w;
}e[MAXN];
int n,m,tot;
int fa[MAXN];
bool comp(edge a,edge b) {
return a.w 并查集
-
题目描述
如题,现在有一个并查集,你需要完成合并和查询操作。
-
输入输出格式
输入格式:
第一行包含两个整数N、M,表示共有N个元素和M个操作。
接下来M行,每行包含三个整数Zi、Xi、Yi
当Zi=1时,将Xi与Yi所在的集合合并
当Zi=2时,输出Xi与Yi是否在同一集合内,是的话输出Y;否则话输出N
输出格式:
如上,对于每一个Zi=2的操作,都有一行输出,每行包含一个大写字母,为Y或者N
-
输入输出样例
输入样例#1:
4 7
2 1 2
1 1 2
2 1 2
1 3 4
2 1 4
1 2 3
2 1 4
输出样例#1:
N
Y
N
Y
-
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据,N<=10,M<=20;
对于70%的数据,N<=100,M<=1000;
对于100%的数据,N<=10000,M<=200000。
#include
#include
#include
#define MAXN 10005
using namespace std;
int n,m,fa[MAXN];
int find(int x) {
if(fa[x]!=x) return fa[x]=find(fa[x]);
}
void merge(int x,int y) {
fa[find(x)]=fa[find(y)];
}
int main() {
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++) fa[i]=i;
for(int i=1;i<=m;i++) {
int opt,x,y;
scanf("%d%d%d",&opt,&x,&y);
if(opt==1) {
if(find(x)!=find(y)) merge(x,y);
}
else {
if(find(x)==find(y)) puts("Y");
else puts("N");
}
}
return 0;
}
单源最短路
-
题目描述
如题,给出一个有向图,请输出从某一点出发到所有点的最短路径长度。
-
输入输出格式
输入格式:
第一行包含三个整数N、M、S,分别表示点的个数、有向边的个数、出发点的编号。
接下来M行每行包含三个整数Fi、Gi、Wi,分别表示第i条有向边的出发点、目标点和长度。
输出格式:
一行,包含N个用空格分隔的整数,其中第i个整数表示从点S出发到点i的最短路径长度(若S=i则最短路径长度为0,若从点S无法到达点i,则最短路径长度为2147483647)
输入输出样例
输入样例#1:
4 6 1
1 2 2
2 3 2
2 4 1
1 3 5
3 4 3
1 4 4
输出样例#1:
0 2 4 3
-
说明
时空限制:1000ms,128M
数据规模:
对于20%的数据:N<=5,M<=15
对于40%的数据:N<=100,M<=10000
对于70%的数据:N<=1000,M<=100000
对于100%的数据:N<=10000,M<=500000
样例说明:

SPFA
#include
#include
#include
#define maxn 1001000
using namespace std;
int read() {
int x=0,f=1;char ch=getchar();
while(ch<'0' || ch>'9'){if(ch=='-')f=-1;ch=getchar();}
while(ch>='0' && ch<='9'){x=x*10+ch-'0';ch=getchar();}
return x*f;
}
struct queue {
int Q[500005],head,tail;
queue() {
head=0,tail=0;
}
void push(int a) {
Q[++tail]=a;
return ;
}
void pop() {
head++;
return ;
}
bool empty() {
return head>=tail;
}
int front() {
return Q[head+1];
}
int size() {
if(head<=tail) return tail-head;
}
};
struct Edge {
int next,to,cost;
}e[maxn];
int num,head[maxn<<1],dist[maxn],vis[maxn],n,m,s;
void insert(int u,int v,int w) {
num++;
e[num].to=v;
e[num].cost=w;
e[num].next=head[u];
head[u]=num;
}
void clearlove(){
for(int i=0;i<=10010;i++)dist[i]=2147483647;
}
void spfa(int s) {
clearlove();
queue q;
dist[s]=0;
vis[s]=1;
q.push(s);
while(!q.empty()) {
int u=q.front();
q.pop();
vis[u]=0;
for(int i=head[u];i;i=e[i].next) {
int to=e[i].to;
if(dist[to]>dist[u]+e[i].cost) {
dist[to]=dist[u]+e[i].cost;
if(!vis[to]) {
vis[to]=1;
q.push(to);
}
}
}
}
}
int main() {
n=read(),m=read(),s=read();
for(int i=1;i<=m;i++) {
int u=read(),v=read(),w=read();
insert(u,v,w);
}
spfa(s);
for(int i=1;i<=n;i++)
printf("%d ",dist[i]);
return 0;
}
最近公共祖先(LCA)
-
题目描述
如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先。
-
输入输出格式
输入格式:
第一行包含三个正整数N、M、S,分别表示树的结点个数、询问的个数和树根结点的序号。
接下来N-1行每行包含两个正整数x、y,表示x结点和y结点之间有一条直接连接的边(数据保证可以构成树)。
接下来M行每行包含两个正整数a、b,表示询问a结点和b结点的最近公共祖先。
输出格式:
输出包含M行,每行包含一个正整数,依次为每一个询问的结果。
-
输入输出样例
输入样例#1:
5 5 4
3 1
2 4
5 1
1 4
2 4
3 2
3 5
1 2
4 5
输出样例#1:
4
4
1
4
4
-
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=10,M<=10
对于70%的数据:N<=10000,M<=10000
对于100%的数据:N<=500000,M<=500000
样例说明:
该树结构如下:
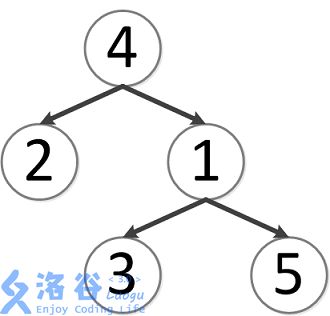
第一次询问:2、4的最近公共祖先,故为4。
第二次询问:3、2的最近公共祖先,故为4。
第三次询问:3、5的最近公共祖先,故为1。
第四次询问:1、2的最近公共祖先,故为4。
第五次询问:4、5的最近公共祖先,故为4。
故输出依次为4、4、1、4、4。
倍增
#include
#include
#include
#include
#define MAXN 5000500
using namespace std;
int read() {
int x=0,f=1;char ch=getchar();
while(ch<'0' || ch>'9') {if(ch=='-')f=-1;ch=getchar();}
while(ch>='0' && ch<='9') {x=x*10+ch-'0';ch=getchar();}
return x*f;
}
struct edge {
int u,v,next;
}e[MAXN];
int num,head[MAXN],n,m,s;
int fa[MAXN][30],deep[MAXN];
void insert(int u,int v) {
num++;
e[num].v=v;
e[num].next=head[u];
head[u]=num;
}
void dfs(int x) {
deep[x]=deep[fa[x][0]]+1;
for(int i=0;fa[x][i];i++) fa[x][i+1]=fa[fa[x][i]][i];
for(int i=head[x];i;i=e[i].next) {
if(!deep[e[i].v]) {
fa[e[i].v][0]=x;
dfs(e[i].v);
}
}
}
int lca(int x,int y) {
if(deep[x]>deep[y]) swap(x,y);
for(int i=20;i>=0;i--) {
if(deep[fa[y][i]]>=deep[x]) y=fa[y][i];
}
if(x==y) return x;
for(int i=20;i>=0;i--) {
if(fa[x][i]!=fa[y][i]) x=fa[x][i],y=fa[y][i];
}
return fa[x][0];
}
int main() {
n=read(),m=read(),s=read();
for(int i=1;i 树链剖分
#include
#include
#include
#include
#include
#define MAXN 500005
using namespace std;
int n,m,s,fa[MAXN],deep[MAXN],size[MAXN],top[MAXN];
vector vec[MAXN];
void dfs(int x) {
size[x]=1;
deep[x]=deep[fa[x]]+1;
for(int i=0; isize[s])s=vec[x][i];
}
if(s) {
top[s]=top[x];
Get_heavy_edge(s);
}
for(int i=0;ideep[y]) swap(x,y);
return x;
}
int main() {
scanf("%d%d%d",&n,&m,&s);
for(int i=1;i<=n-1;i++) {
int u,v;
scanf("%d%d",&u,&v);
vec[u].push_back(v);
vec[v].push_back(u);
}
dfs(s);
Get_heavy_edge(s);
for(int i=1;i<=m;i++) {
int x,y;
scanf("%d%d",&x,&y);
printf("%d\n",lca(x,y));
}
return 0;
}
负环
-
题目描述
暴力枚举/SPFA/Bellman-ford/奇怪的贪心/超神搜索
-
输入输出格式
输入格式:
第一行一个正整数T表示数据组数,对于每组数据:
第一行两个正整数N M,表示图有N个顶点,M条边
接下来M行,每行三个整数a b w,表示a->b有一条权值为w的边(若w<0则为单向,否则双向)
输出格式:
共T行。对于每组数据,存在负环则输出一行"YE5"(不含引号),否则输出一行"N0"(不含引号)。
-
输入输出样例
输入样例#1:
2
3 4
1 2 2
1 3 4
2 3 1
3 1 -3
3 3
1 2 3
2 3 4
3 1 -8
输出样例#1:
N0
YE5
说明
N,M,|w|≤200 000;1≤a,b≤N;T≤10 建议复制输出格式中的字符串。
此题普通Bellman-Ford或BFS-SPFA会TLE
#include
#include
#include
#include
#define MAXN 200005
using namespace std;
int read() {
int x=0,f=1;char ch=getchar();
while(ch<'0' || ch>'9') {if(ch=='-')f=-1;ch=getchar();}
while(ch>='0' && ch<='9') {x=x*10+ch-'0';ch=getchar();}
return x*f;
}
struct edge {
int u,v,w,next;
}e[MAXN<<1];
int n,m,t;
int num,head[MAXN<<1];
int vis[MAXN],dis[MAXN];
void insert(int u,int v,int w) {
num++;
e[num].v=v;
e[num].next=head[u];
e[num].w=w;
head[u]=num;
}
void clear() {
num=0;
memset(e,0,sizeof(e));
memset(head,0,sizeof(head));
memset(dis,0,sizeof(dis));
memset(vis,0,sizeof(vis));
}
bool spfa_dfs(int u) {
vis[u]=1;
for(int k=head[u];k;k=e[k].next) {
int v=e[k].v,w=e[k].w;
if(dis[u]+w 缩点
-
题目背景
缩点+DP
-
题目描述
给定一个n个点m条边有向图,每个点有一个权值,求一条路径,使路径经过的点权值之和最大。你只需要求出这个权值和。
允许多次经过一条边或者一个点,但是,重复经过的点,权值只计算一次。
-
输入输出格式
输入格式:
第一行,n,m
第二行,n个整数,依次代表点权
第三至m+2行,每行两个整数u,v,表示u->v有一条有向边
输出格式:
共一行,最大的点权之和。
-
输入输出样例
输入样例#1:
2 2
1 1
1 2
2 1
输出样例#1:
2
-
说明
n<=104,m<=105,|点权|<=1000 算法:Tarjan缩点+DAGdp
#include
#include
#include
#include
#include
#define MAXN 10005
#define MAXM 500005
using namespace std;
struct edge {
int u,v,next;
}e[MAXM<<1];
int num,head[MAXN<<1];
void ins(int u,int v) {
num++;
e[num].u=u;
e[num].v=v;
e[num].next=head[u];
head[u]=num;
}
int cnt,DFN[MAXN],LOW[MAXN],Time,belong[MAXN],stack[MAXN],top;
bool inst[MAXN];
vector bcc[MAXN];
int n,m,w[MAXN],gg[MAXN];
void tarjan(int u) {
LOW[u]=DFN[u]=++Time;
inst[u]=true;
stack[top++]=u;
for(int i=head[u];i;i=e[i].next) {
int v=e[i].v;
if(inst[v]) {
LOW[u]=min(LOW[u],DFN[v]);
}
else if(!DFN[v]) {
tarjan(v);
LOW[u]=min(LOW[u],LOW[v]);
}
}
if(LOW[u]==DFN[u]) {
int now;
cnt++;
do {
now=stack[--top];
inst[now]=false;
belong[now]=cnt;
bcc[cnt].push_back(now);
w[cnt]+=gg[now];
} while(now!=u);
}
}
vector G[MAXN];
int du[MAXN];
void Shrinking_point() {
for(int i=1;i<=m;i++) {
int u=belong[e[i].u],v=belong[e[i].v];
if(u!=v) G[u].push_back(v),du[v]++;
}
}
struct queue {
int Q[500005],head,tail;
queue() {
head=0,tail=0;
}
void push(int a) {
Q[++tail]=a;
return ;
}
void pop() {
head++;
return ;
}
bool empty() {
return head>=tail;
}
int front() {
return Q[head+1];
}
int size() {
if(head<=tail) return tail-head;
}
void clear() {
head=tail=0;
memset(Q,0,sizeof(Q));
}
};
int dist[MAXN],ans;
bool vis[MAXN];
void clearlove() {
for(int i=0;i<=cnt;i++) dist[i]=0;
fill(vis,vis+cnt+1,false);
}
int SPFA(int s) {
int res=0;
clearlove();
queue q;
dist[s]=w[s];
vis[s]=1;
q.push(s);
while(!q.empty()) {
int u=q.front();
q.pop();
vis[u]=0;
for(int i=0;i 割点
-
题目背景
割点
-
题目描述
给出一个n个点,m条边的无向图,求图的割点。
-
输入输出格式
输入格式:
第一行输入n,m
下面m行每行输入x,y表示x到y有一条边
输出格式:
第一行输出割点个数
第二行按照节点编号从小到大输出节点,用空格隔开
-
输入输出样例
输入样例#1:
6 7
1 2
1 3
1 4
2 5
3 5
4 5
5 6
输出样例#1:
1
5
-
说明
n,m均为100000
tarjan 图不一定联通!!!
#include
#include
#include
#include
#define MAXN 100005
using namespace std;
int read() {
int x=0,f=1;char ch=getchar();
while(ch<'0' || ch>'9') {if(ch=='-')f=-1;ch=getchar();}
while(ch>='0' && ch<='9') {x=x*10+ch-'0';ch=getchar();}
return x*f;
}
struct edge {
int u,v,next;
}e[MAXN<<1];
int head[MAXN<<1],num;
void ins(int u,int v) {
num++;
e[num].u=u;
e[num].v=v;
e[num].next=head[u];
head[u]=num;
}
int n,m,ans;
int dfn[MAXN],low[MAXN],Time;
bool cut[MAXN],in[MAXN];
int root,child;
void tarjan(int u,int fa) {
int child=0;
dfn[u]=low[u]=++Time;
in[u]=true;
for(int i=head[u];i;i=e[i].next) {
int v=e[i].v;
if(in[v] && v!=fa) {
low[u]=min(low[u],dfn[v]);
}
else if(!dfn[v]) {
tarjan(v,u);
child++;
low[u]=min(low[u],low[v]);
if((fa!=root && dfn[u]<=low[v]) || (fa==root && child>1)) {
if(!cut[u]) ans++;
cut[u]=true;
}
}
}
}
int main() {
n=read(),m=read();
for(int i=1;i<=m;i++) {
int u=read(),v=read();
ins(u,v);
ins(v,u);
}
root=-1;
for(int i=1;i<=n;i++) if(!dfn[i]) tarjan(i,root);
printf("%d\n",ans);
for(int i=1;i<=n;i++) if(cut[i]) printf("%d ",i);
return 0;
}
网络最大流
-
题目描述
如题,给出一个网络图,以及其源点和汇点,求出其网络最大流。
-
输入输出格式
输入格式:
第一行包含四个正整数N、M、S、T,分别表示点的个数、有向边的个数、源点序号、汇点序号。
接下来M行每行包含三个正整数ui、vi、wi,表示第i条有向边从ui出发,到达vi,边权为wi(即该边最大流量为wi)
输出格式:
一行,包含一个正整数,即为该网络的最大流。
-
输入输出样例
输入样例#1:
4 5 4 3
4 2 30
4 3 20
2 3 20
2 1 30
1 3 40
输出样例#1:
50
-
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=10,M<=25
对于70%的数据:N<=200,M<=1000
对于100%的数据:N<=10000,M<=100000
样例说明:
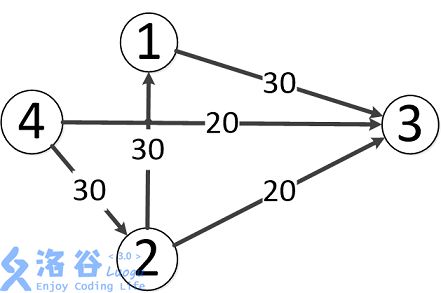
题目中存在3条路径:
4-->2-->3,该路线可通过20的流量
4-->3,可通过20的流量
4-->2-->1-->3,可通过10的流量(边4-->2之前已经耗费了20的流量)
故流量总计20+20+10=50。输出50。
#include
#include
#include
#include
#define MAXN 200005
#define MAXM 500005
#define INF 0x7fffffff
using namespace std;
int read() {
int x=0,f=1;char ch=getchar();
while(ch<'0' || ch>'9') {if(ch=='-')f=-1;ch=getchar();}
while(ch>='0' && ch<='9') {x=x*10+ch-'0';ch=getchar();}
return x*f;
}
struct edge {
int u,v,f,next;
}e[MAXN<<1];
int head[MAXN<<1],num;
void ins(int u,int v,int f) {
num++;
e[num].u=u;
e[num].v=v;
e[num].f=f;
e[num].next=head[u];
head[u]=num;
}
int n,m,S,T,ans;
int qu[MAXN<<1],deep[MAXN<<1];
bool bfs() {
int h=0,t=1;
memset(deep,-1,sizeof(deep));
qu[h]=S;
deep[S]=0;
while(h 二分图匹配
-
题目背景
二分图
-
题目描述
给定一个二分图,结点个数分别为n,m,边数为e,求二分图最大匹配数
-
输入输出格式
输入格式:
第一行,n,m,e
第二至e+1行,每行两个正整数u,v,表示u,v有一条连边
输出格式:
共一行,二分图最大匹配
-
输入输出样例
输入样例#1:
1 1 1
1 1
输出样例#1:
1
-
说明

网络流算法
#include
#include
#include
#include
#include
#define MAXN 550000
using namespace std;
inline int read() {
int x=0,f=1;char ch=getchar();
while(ch<'0' || ch>'9'){if(ch=='-')f=-1;ch=getchar();}
while(ch>='0' && ch<='9'){x=x*10+ch-'0';ch=getchar();}
return x*f;
}
struct edge {
int to,next,v;
}e[550000];
int head[MAXN<<1],ne=1,q[MAXN<<1],h[MAXN<<1],ans,n,m,S,T,ee;
inline void ins(int u,int v,int f) {
ne++;
e[ne].to=v;
e[ne].next=head[u];
e[ne].v=f;
head[u]=ne;
}
inline void insert(int u,int v,int f) {
ins(u,v,f);ins(v,u,0);
}
bool bfs() {
int t=0,w=1;
memset(h,-1,sizeof(h));
q[t]=S;h[S]=0;
while(tm) continue;
insert(u,v+n,1);
}
S=0,T=n+m+1;
for(int i=1;i<=n;i++) insert(S,i,1);
for(int i=1;i<=m;i++) insert(i+n,T,1);
dinic();
printf("%d",ans);
return 0;
}
树状数组
-
题目描述
如题,已知一个数列,你需要进行下面两种操作:
1.将某一个数加上x
2.求出某区间每一个数的和
-
输入输出格式
输入格式:
第一行包含两个整数N、M,分别表示该数列数字的个数和操作的总个数。
第二行包含N个用空格分隔的整数,其中第i个数字表示数列第i项的初始值。
接下来M行每行包含3个整数,表示一个操作,具体如下:
操作1: 格式:1 x k 含义:将第x个数加上k
操作2: 格式:2 x y 含义:输出区间[x,y]内每个数的和
输出格式:
输出包含若干行整数,即为所有操作2的结果。
-
输入输出样例
输入样例#1:
5 5
1 5 4 2 3
1 1 3
2 2 5
1 3 -1
1 4 2
2 1 4
输出样例#1:
14
16
-
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=8,M<=10
对于70%的数据:N<=10000,M<=10000
对于100%的数据:N<=500000,M<=500000
样例说明:
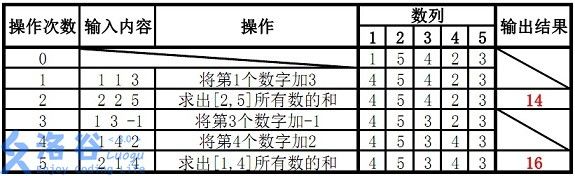
故输出结果14、16
#include
#include
#include
#define MAXN 500005
using namespace std;
int a[MAXN],c[MAXN],n,m;
int lowbit(int x) {
return x&(-x);
}
void modify(int p,int x) {
while(p<=n) {
c[p]+=x;
p+=lowbit(p);
}
return ;
}
int sum(int p) {
int sum=0;
while(p) {
sum+=c[p];
p-=lowbit(p);
}
return sum;
}
int query(int l,int r) {
return sum(r)-sum(l-1);
}
int main() {
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++) scanf("%d",&a[i]),modify(i,a[i]);
for(int i=1;i<=m;i++) {
int id,x,y;
scanf("%d%d%d",&id,&x,&y);
if(id==1) modify(x,y);
else printf("%d\n",query(x,y));
}
return 0;
}
-
题目描述
如题,已知一个数列,你需要进行下面两种操作:
1.将某区间每一个数数加上x
2.求出某一个数的和
-
输入输出格式
输入格式:
第一行包含两个整数N、M,分别表示该数列数字的个数和操作的总个数。
第二行包含N个用空格分隔的整数,其中第i个数字表示数列第i项的初始值。
接下来M行每行包含2或4个整数,表示一个操作,具体如下:
操作1: 格式:1 x y k 含义:将区间[x,y]内每个数加上k
操作2: 格式:2 x 含义:输出第x个数的值
输出格式:
输出包含若干行整数,即为所有操作2的结果。
-
输入输出样例
输入样例#1:
5 5
1 5 4 2 3
1 2 4 2
2 3
1 1 5 -1
1 3 5 7
2 4
输出样例#1:
6
10
-
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=8,M<=10
对于70%的数据:N<=10000,M<=10000
对于100%的数据:N<=500000,M<=500000
样例说明:
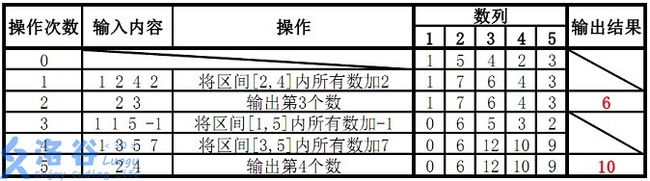
故输出结果为6、10
#include
#include
#define maxn 500000+5
using namespace std;
int n,m,pre,c[maxn];
int lowbit(int x) {
return x&(-x);
}
void modify(int pos,int x) {
while(pos<=n) {
c[pos]+=x;
pos+=lowbit(pos);
}
return ;
}
int query(int pos) {
int ans=0;
while(pos>0) {
ans+=c[pos];
pos-=lowbit(pos);
}
return ans;
}
int main() {
scanf("%d%d",&n,&m);
for(int i=1; i<=n; i++) {
int x;
scanf("%d",&x);
modify(i,x-pre);
pre=x;
}
while(m--) {
int id;
scanf("%d",&id);
if(id==1) {
int l,r,k;
scanf("%d%d%d",&l,&r,&k);
modify(l,k);
modify(r+1,-k);
} else {
int pos;
scanf("%d",&pos);
printf("%d\n",query(pos));
}
}
return 0;
}
线段树
-
题目描述
如题,已知一个数列,你需要进行下面两种操作:
1.将某区间每一个数加上x
2.求出某区间每一个数的和
-
输入输出格式
输入格式:
第一行包含两个整数N、M,分别表示该数列数字的个数和操作的总个数。
第二行包含N个用空格分隔的整数,其中第i个数字表示数列第i项的初始值。
接下来M行每行包含3或4个整数,表示一个操作,具体如下:
操作1: 格式:1 x y k 含义:将区间[x,y]内每个数加上k
操作2: 格式:2 x y 含义:输出区间[x,y]内每个数的和
输出格式:
输出包含若干行整数,即为所有操作2的结果。
-
输入输出样例
输入样例#1:
5 5
1 5 4 2 3
2 2 4
1 2 3 2
2 3 4
1 1 5 1
2 1 4
输出样例#1:
11
8
20
-
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=8,M<=10
对于70%的数据:N<=1000,M<=10000
对于100%的数据:N<=100000,M<=100000
(数据已经过加强_,保证在int64/long long数据范围内)
样例说明:
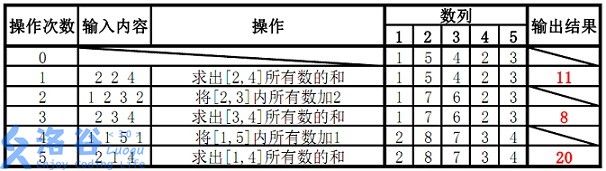
#include
#include
#include
#include
#define lson l,m,rt<<1
#define rson m+1,r,rt<<1|1
#define maxn 1000005
#define ll long long
using namespace std;
inline ll read() {
ll x=0,f=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){x=x*10+ch-'0';ch=getchar();}
return x*f;
}
ll a[maxn],sum[maxn<<2],col[maxn<<2];
void update(ll rt) {
sum[rt] = sum[rt<<1] + sum[rt<<1|1];
}
void color(ll l,ll r,ll rt,ll c) {
col[rt]+=c;
sum[rt]+=c*(r-l+1);
}
void push_col(ll l,ll r,ll rt) {
if(col[rt]) {
ll m=(l+r)>>1;
color(lson,col[rt]);
color(rson,col[rt]);
col[rt]=0;
}
}
void build(ll l,ll r,ll rt) {
if(l==r) {
sum[rt] = a[l];
return ;
}
ll m=(l+r)>>1;
build(lson);
build(rson);
update(rt);
}
ll query(ll l,ll r,ll rt,ll L,ll R) {
if(L<=l && R>=r)return sum[rt];
push_col(l,r,rt);
ll ret=0;
ll m=(l+r)>>1;
if(L<=m) ret+=query(lson,L,R);
if(m=r) {
color(l,r,rt,v);
return ;
}
push_col(l,r,rt);
ll m=(l+r)>>1;
if(L<=m) modify(lson,L,R,v);
if(m -
题目描述
如题,已知一个数列,你需要进行下面两种操作:
1.将某区间每一个数加上x
2.将某区间每一个数乘上x
3.求出某区间每一个数的和
-
输入输出格式
输入格式:
第一行包含三个整数N、M、P,分别表示该数列数字的个数、操作的总个数和模数。
第二行包含N个用空格分隔的整数,其中第i个数字表示数列第i项的初始值。
接下来M行每行包含3或4个整数,表示一个操作,具体如下:
操作1: 格式:1 x y k 含义:将区间[x,y]内每个数乘上k
操作2: 格式:2 x y k 含义:将区间[x,y]内每个数加上k
操作3: 格式:3 x y 含义:输出区间[x,y]内每个数的和对P取模所得的结果
输出格式:
输出包含若干行整数,即为所有操作3的结果。
-
输入输出样例
输入样例#1:
5 5 38
1 5 4 2 3
2 1 4 1
3 2 5
1 2 4 2
2 3 5 5
3 1 4
输出样例#1:
17
2
-
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=8,M<=10
对于70%的数据:N<=1000,M<=10000
对于100%的数据:N<=100000,M<=100000
(数据已经过加强_)
样例说明:
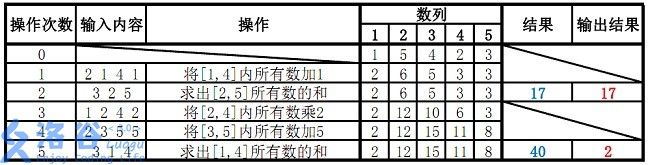
故输出应为17、2(40 mod 38=2)
#include
using namespace std;
const long long maxn=1000000*4+10;
long long sum[maxn],add[maxn],mul[maxn];
#define root 1,n,1
#define ls l,m,o<<1
#define rs m+1,r,o<<1|1
inline void read(long long& x) {
char c=getchar();
long long p=1,n=0;
while(c<'0'||c>'9') {
if(c=='-')p=-1;
c=getchar();
}
while(c>='0'&&c<='9') {
n=n*10+c-'0';
c=getchar();
}
x=p*n;
}
long long ql,qr,val;
long long n,m,MOD;
inline void pushup(long long o) {
sum[o]=(sum[o<<1]+sum[o<<1|1])%MOD;
}
inline void pushdown(long long o,long long m) {
if(add[o]||mul[o]!=1) {
long long ad=add[o],mu=mul[o];
sum[o<<1]=(sum[o<<1]*mu+ad*(m-(m>>1)))%MOD;
sum[o<<1|1]=(sum[o<<1|1]*mu+ad*(m>>1))%MOD;
add[o<<1]=(add[o<<1]*mu+ad)%MOD;
add[o<<1|1]=(add[o<<1|1]*mu+ad)%MOD;
mul[o<<1]=(mul[o<<1]*mu)%MOD;
mul[o<<1|1]=(mul[o<<1|1]*mu)%MOD;
add[o]=0;
mul[o]=1;
}
}
void build(long long l,long long r,long long o) {
add[o]=0;
mul[o]=1;
if(l==r) {
read(sum[o]);
sum[o]=sum[o]%MOD;
return;
}
long long m=l+(r-l)/2;
build(ls);
build(rs);
pushup(o);
}
void update_plus(long long l,long long r,long long o) {
pushdown(o,r-l+1);
if(ql<=l&&r<=qr) {
add[o]+=val;
add[o]=add[o]%MOD;
sum[o]+=(r-l+1)*val;
sum[o]=sum[o]%MOD;
return;
}
long long m=l+(r-l)/2;
if(ql<=m)update_plus(ls);
if(qr>m)update_plus(rs);
pushup(o);
}
void update_mul(long long l,long long r,long long o) {
pushdown(o,r-l+1);
if(ql<=l&&r<=qr) {
mul[o]=mul[o]*val;
mul[o]=mul[o]%MOD;
sum[o]=sum[o]*val;
sum[o]=sum[o]%MOD;
return;
}
long long m=l+(r-l)/2;
if(ql<=m)update_mul(ls);
if(qr>m)update_mul(rs);
pushup(o);
}
long long query(long long l,long long r,long long o) {
pushdown(o,r-l+1);
if(ql<=l&&r<=qr) {
return sum[o];
}
long long m=l+(r-l)/2;
long long ret=0;
if(ql<=m)ret+=query(ls),ret=ret%MOD;
if(qr>m)ret+=query(rs),ret=ret%MOD;
return ret%MOD;
}
int main() {
read(n);
read(m);
read(MOD);
build(root);
for(long long i=1; i<=m; i++) {
long long op;
read(op);
if(op==1) {
read(ql);
read(qr);
read(val);
update_mul(root);
}
if(op==2) {
read(ql);
read(qr);
read(val);
update_plus(root);
}
if(op==3) {
read(ql);
read(qr);
printf("%lld\n",query(root)%MOD);
}
}
return 0;
}
ST表
-
题目背景
这是一道ST表经典题——静态区间最大值
请注意最大数据时限只有0.8s,数据强度不低,请务必保证你的每次查询复杂度为O(1)
-
题目描述
给定一个长度为N的数列,和M次询问,求出每一次询问的区间内数字的最大值。
-
输入输出格式
输入格式:
第一行包含两个整数N,M,分别表示数列的长度和询问的个数。第二行包含N
个整数(记为ai ),依次表示数列的第i项。
接下来M 行,每行包含两个整数li,ri ,表示查询的区间为[li,ri]
输出格式:
输出包含M 行,每行一个整数,依次表示每一次询问的结果。
输入输出样例
输入样例#1:
8 8
9 3 1 7 5 6 0 8
1 6
1 5
2 7
2 6
1 8
4 8
3 7
1 8
输出样例#1:
9
9
7
7
9
8
7
9
-
说明
#include
#include
#include
#include
#define MAXN 1000005
using namespace std;
int read() {
int x=0,f=1;char ch=getchar();
while(ch<'0' || ch>'9') {if(ch=='-')f=-1;ch=getchar();}
while(ch>='0' && ch<='9') {x=x*10+ch-'0';ch=getchar();}
return x*f;
}
int n,m;
int st[MAXN][30],a[MAXN],log_2[MAXN];
inline void ini_st() {
log_2[1]=0;
for(int i=2;i<=n;++i) {
log_2[i]=log_2[i-1];
if((1< 矩阵快速幂
-
题目背景
矩阵快速幂
-
题目描述
给定n*n的矩阵A,求A^k
-
输入输出格式
输入格式:
第一行,n,k
第2至n+1行,每行n个数,第i+1行第j个数表示矩阵第i行第j列的元素
输出格式:
输出A^k
共n行,每行n个数,第i行第j个数表示矩阵第i行第j列的元素,每个元素模10^9+7
-
输入输出样例
输入样例#1:
2 1
1 1
1 1
输出样例#1:
1 1
1 1
-
说明
n<=100, k<=10^12, |矩阵元素|<=1000 算法:矩阵快速幂
普通快速幂同理
#include
#include
#include
#include
#define ll long long
#define maxn 100+5
#define mod 1000000007
using namespace std;
ll n,m;
struct Matrix {
ll a[maxn][maxn];
void clear() {
memset(a,0,sizeof(a));
}
Matrix() {
this->clear();
}
Matrix operator *(const Matrix &b)const {
Matrix c;
for(ll i=0; i>=1,k=k*k)
if (n&1) ret=ret*k;
return ret;
}
int main() {
Matrix x;
cin>>n>>m;
for(ll i=0; i>x.a[i][j];
x=fastm(x,m);
for(ll i=0; i 线性筛素数
-
题目描述
如题,给定一个范围N,你需要处理M个某数字是否为质数的询问(每个数字均在范围1-N内)
-
输入输出格式
输入格式:
第一行包含两个正整数N、M,分别表示查询的范围和查询的个数。
接下来M行每行包含一个不小于1且不大于N的整数,即询问该数是否为质数。
输出格式:
输出包含M行,每行为Yes或No,即依次为每一个询问的结果。
-
输入输出样例
输入样例#1:
100 5
2
3
4
91
97
输出样例#1:
Yes
Yes
No
No
Yes
-
说明
时空限制:500ms 128M
数据规模:
对于30%的数据:N<=10000,M<=10000
对于100%的数据:N<=10000000,M<=100000
样例说明:
N=100,说明接下来的询问数均不大于100且不小于1。
所以2、3、97为质数,4、91非质数。
故依次输出Yes、Yes、No、No、Yes。
#include
#include
#include
#include
using namespace std;
const int maxn=10000000;
int prime[maxn],n,tot,m;
bool vis[maxn];
bool is_prime(int x) {
int k=sqrt(x+0.5);
for(int i=2; i<=k; i++)
if(x%i==0) return false;
return true;
}
void Eratosthenes() {
int m=sqrt(n+0.5);
vis[1]=true;
for(int i=2; i<=m; i++)
if(vis[i]==false)
for(int j=i*i; j<=n; j+=i)
vis[j]=true;
return;
}
void GetPrime() {
for(int i=2; i<=n; i++) {
if(vis[i]==false) prime[++tot]=i;
for(int j=1; j<=tot&&i*prime[j]<=n; j++) {
vis[i*prime[j]]=true;
if(i%prime[j]==0) break;
}
}
return;
}
void solve() {
GetPrime();
for(int i=1; i<=tot; i++)
printf("%d ",prime[i]);
return;
}
int main() {
cin>>n>>m;
Eratosthenes();
while(m--) {
int a;
cin>>a;
if(!vis[a]) cout<<"Yes"< 乘法逆元
-
题目背景
这是一道模板题
-
题目描述
给定n,p求1~n中所有整数在模p意义下的乘法逆元。
-
输入输出格式
输入格式:
一行n,p
输出格式:
n行,第i行表示i在模p意义下的逆元。
-
输入输出样例
输入样例#1:
10 13
输出样例#1:
1
7
9
10
8
11
2
5
3
4
-
说明

线性
#include
#define N 3000010
typedef long long ll;
using namespace std;
int inv[N],n,p;
int main() {
cin>>n>>p;
inv[1]=1;
puts("1");
for(int i=2; i<=n; i++) {
inv[i]=(ll)(p-p/i)*inv[p%i]%p;
printf("%d\n",inv[i]);
}
return 0;
}
扩展欧几里得
#include
#include
using namespace std;
int ex_gcd(int a,int b,int &x,int &y) {
if (a==0&&b==0) return -1;
if (b==0){x=1;y=0;return a;}
int d=ex_gcd(b,a%b,y,x);
y-=a/b*x;
return d;
}
int inv(int a,int n) {
int x,y;
int d = ex_gcd(a,n,x,y);
return (x%n+n)%n;
}
int main() {
int a,p;
scanf("%d%d",&a,&p);
for(int i=1;i<=a;i++)
printf("%d\n",inv(i,p));
return 0;
}
扩展欧几里得(EXGCD)
-
题目描述
求关于 x 的同余方程 ax ≡ 1 (mod b)的最小正整数解。
-
输入输出格式
输入格式:
输入只有一行,包含两个正整数 a, b,用一个空格隔开。
输出格式:
输出只有一行,包含一个正整数 x0,即最小正整数解。输入数据保证一定有解。
-
输入输出样例
输入样例#1:
3 10
输出样例#1:
7
-
说明
【数据范围】
对于 40%的数据,2 ≤b≤ 1,000;
对于 60%的数据,2 ≤b≤ 50,000,000;
对于 100%的数据,2 ≤a, b≤ 2,000,000,000。
#include
#include
using namespace std;
int a,b,x,y,k;
void exgcd(int a,int b) {
if(b==0) {
x=1;
y=0;
return;
}
exgcd(b,a%b);
k=x;
x=y;
y=k-a/b*y;
return;
}
int main() {
cin>>a>>b;
exgcd(a,b);
cout<<(x+b)%b;
return 0;
}
字符串哈希
-
题目描述
如题,给定N个字符串(第i个字符串长度为Mi,字符串内包含数字、大小写字母,大小写敏感),请求出N个字符串中共有多少个不同的字符串。
友情提醒:如果真的想好好练习哈希的话,请自觉,否则请右转PJ试炼场:)
-
输入输出格式
输入格式:
第一行包含一个整数N,为字符串的个数。
接下来N行每行包含一个字符串,为所提供的字符串。
输出格式:
输出包含一行,包含一个整数,为不同的字符串个数。
-
输入输出样例
输入样例#1:
5
abc
aaaa
abc
abcc
12345
输出样例#1:
4
-
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=10,Mi≈6,Mmax<=15;
对于70%的数据:N<=1000,Mi≈100,Mmax<=150
对于100%的数据:N<=10000,Mi≈1000,Mmax<=1500
样例说明:
样例中第一个字符串(abc)和第三个字符串(abc)是一样的,所以所提供字符串的集合为{aaaa,abc,abcc,12345},故共计4个不同的字符串。
#include
#include
#include
#include
#define MAXN 10005
#define seed 20020207
#define ULL unsigned long long
using namespace std;
int n;
long long h[MAXN];
string s[MAXN];
ULL hash(string s) {
ULL value=0;
int x=1;
for(int i=0;i>s[i];
h[i]=hash(s[i]);
}
int ans=0;
sort(h+1,h+n+1);
for(int i=1;i<=n;i++) {
if(h[i]!=h[i+1]) ans++;
}
printf("%d",ans);
return 0;
}
KMP
-
题目描述
如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。
-
输入输出格式
输入格式:
第一行为一个字符串,即为s1
第二行为一个字符串,即为s2
输出格式:
若干行,每行包含一个整数,表示s2在s1中出现的位置
接下来1行,包括length(s2)个整数,表示前缀数组next[i]的值。
-
输入输出样例
输入样例#1:
ABABABC
ABA
输出样例#1:
1
3
0 0 1
-
说明
时空限制:1000ms,128M
数据规模:
设s1长度为N,s2长度为M
对于30%的数据:N<=15,M<=5
对于70%的数据:N<=10000,M<=100
对于100%的数据:N<=1000000,M<=1000000
样例说明:
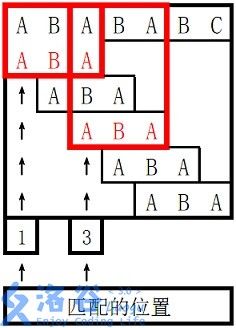
所以两个匹配位置为1和3,输出1、3
#include
#include
#include
#include
#include
#include
using namespace std;
const int maxn=1001;
int Next[maxn];
vector Ans;
inline void Get_Next(string s) {
int l=s.length(),t;
Next[0]=-1;
for(int i=1;i=0)
t=Next[t];
if(s[t+1]==s[i])
Next[i]=t+1;
else
Next[i]=-1;
}
}
inline void KMP(string s1,string s2) {
Get_Next(s2);
int l1=s1.length();
int l2=s2.length();
int i=0,j=0;
while(j>s1>>s2;
l=s2.length();
KMP(s1,s2);
for(int i=0;i AC自动机
-
题目背景
这是一道简单的AC自动机模板题。
用于检测正确性以及算法常数。
管理员提示:本题数据内有重复的单词,且重复单词应该计算多次,请各位注意
-
题目描述
给定n个模式串和1个文本串,求有多少个模式串在文本串里出现过。
-
输入输出格式
输入格式:
第一行一个n,表示模式串个数;
下面n行每行一个模式串;
下面一行一个文本串。
输出格式:
一个数表示答案
-
输入输出样例
输入样例#1:
2
a
aa
aa
输出样例#1:
2
-
说明
subtask1[50pts]:∑length(模式串)<=106,length(文本串)<=106,n=1;
subtask2[50pts]:∑length(模式串)<=106,length(文本串)<=106;
#include
#include
#include
#include
using namespace std;
struct Trie {
int ch[26];
int end;
int fail;
}AC[1000000];
int cnt=0;
int index(char c) {
return c-'a';
}
void Build_Trie(string s) {
int l=s.length();
int now=0;
for(int i=0;i q;
for(int i=0;i<26;i++) {
if(AC[0].ch[i]!=0) {
AC[AC[0].ch[i]].fail=0;
q.push(AC[0].ch[i]);
}
}
while(!q.empty()) {
int u=q.front();
q.pop();
for(int i=0;i<26;i++) {
if(AC[u].ch[i]!=0) {
AC[AC[u].ch[i]].fail=AC[AC[u].fail].ch[i];
q.push(AC[u].ch[i]);
}
else
AC[u].ch[i]=AC[AC[u].fail].ch[i];
}
}
}
int AC_work(string s) {
int l=s.length();
int now=0,ans=0;
for(int i=0;i>s;
Build_Trie(s);
}
Get_fail();
cin>>s;
printf("%d",AC_work(s));
return 0;
}
-
题目描述
有N个由小写字母组成的模式串以及一个文本串 T 。每个模式串可能会在文本串中出现多次。你需要找出哪些模式串在文本串 T 中出现的次数最多。
-
输入输出格式
输入格式:
输入含多组数据。
每组数据的第一行为一个正整数 N ,表示共有 N 个模式串, 1≤N≤150 。接下去 N 行,每行一个长度小于等于 70 的模式串。下一行是一个长度小于等于 106 的文本串 T 。
输入结束标志为 N=0 。
输出格式:
对于每组数据,第一行输出模式串最多出现的次数,接下去若干行每行输出一个出现次数最多的模式串,按输入顺序排列。
输入输出样例
输入样例#1:
2
aba
bab
ababababac
6
beta
alpha
haha
delta
dede
tata
dedeltalphahahahototatalpha
0
输出样例#1:
4
aba
2
alpha
haha
#include
#include
#include
#include
#include
#include
#include
using namespace std;
struct Tree {
int fail;
int vis[26];
int end;
} AC[100000];
int cnt;
struct Result {
int num;
int pos;
} Ans[100000];
bool operator <(Result a,Result b) {
if(a.num!=b.num)
return a.num>b.num;
else
return a.pos Q;
for(int i=0; i<26; ++i) {
if(AC[0].vis[i]!=0) {
AC[AC[0].vis[i]].fail=0;
Q.push(AC[0].vis[i]);
}
}
while(!Q.empty()) {
int u=Q.front();
Q.pop();
for(int i=0; i<26; ++i) {
if(AC[u].vis[i]!=0) {
AC[AC[u].vis[i]].fail=AC[AC[u].fail].vis[i];
Q.push(AC[u].vis[i]);
} else
AC[u].vis[i]=AC[AC[u].fail].vis[i];
}
}
}
int AC_Query(string s) {
int l=s.length();
int now=0,ans=0;
for(int i=0; i>n;
if(n==0)break;
cnt=0;
Clean(0);
for(int i=1; i<=n; ++i) {
cin>>s[i];
Ans[i].num=0;
Ans[i].pos=i;
Build(s[i],i);
}
AC[0].fail=0;
Get_fail();
cin>>s[0];
AC_Query(s[0]);
sort(&Ans[1],&Ans[n+1]);
cout< 高精度
#include
#include
#include
#include
#include
#include
#include
#include
#define MAX_L 2005 //最大长度,可以修改
using namespace std;
class BN {
public:
int len, s[MAX_L];//数的长度,记录数组
//构造函数
BN();
BN(const char*);
BN(int);
bool sign;//符号 1正数 0负数
string toStr() const;//转化为字符串,主要是便于输出
friend istream& operator>>(istream &,BN &);//重载输入流
friend ostream& operator<<(ostream &,BN &);//重载输出流
//重载复制
BN operator=(const char*);
BN operator=(int);
BN operator=(const string);
//重载各种比较
bool operator>(const BN &) const;
bool operator>=(const BN &) const;
bool operator<(const BN &) const;
bool operator<=(const BN &) const;
bool operator==(const BN &) const;
bool operator!=(const BN &) const;
//重载四则运算
BN operator+(const BN &) const;
BN operator++();
BN operator++(int);
BN operator+=(const BN&);
BN operator-(const BN &) const;
BN operator--();
BN operator--(int);
BN operator-=(const BN&);
BN operator*(const BN &)const;
BN operator*(const int num)const;
BN operator*=(const BN&);
BN operator/(const BN&)const;
BN operator/=(const BN&);
//四则运算的衍生运算
BN operator%(const BN&)const;//取模(余数)
BN factorial()const;//阶乘
BN Sqrt()const;//整数开根(向下取整)
BN pow(const BN&)const;//次方
//一些乱乱的函数
void clean();
~BN();
};
#define max(a,b) a>b ? a : b
#define min(a,b) a>(istream &in, BN &num) {
string str;
in>>str;
num=str;
return in;
}
ostream &operator<<(ostream &out, BN &num) {
out<= 0; i--)
if (s[i] != num.s[i])
return sign ? (s[i] < num.s[i]) : (!(s[i] < num.s[i]));
return !sign;
}
bool BN::operator>(const BN&num)const {
return num < *this;
}
bool BN::operator<=(const BN&num)const {
return !(*this>num);
}
bool BN::operator>=(const BN&num)const {
return !(*this num || *this < num;
}
bool BN::operator==(const BN&num)const {
return !(num != *this);
}
BN BN::operator+(const BN &num) const {
if (sign^num.sign) {
BN tmp = sign ? num : *this;
tmp.sign = 1;
return sign ? *this - tmp : num - tmp;
}
BN result;
result.len = 0;
int temp = 0;
for (int i = 0; temp || i < (max(len, num.len)); i++) {
int t = s[i] + num.s[i] + temp;
result.s[result.len++] = t % 10;
temp = t / 10;
}
result.sign = sign;
return result;
}
BN BN::operator++() {
*this = *this + 1;
return *this;
}
BN BN::operator++(int) {
BN old = *this;
++(*this);
return old;
}
BN BN::operator+=(const BN &num) {
*this = *this + num;
return *this;
}
BN BN::operator-(const BN &num) const {
BN b=num,a=*this;
if (!num.sign && !sign) {
b.sign=1;
a.sign=1;
return b-a;
}
if (!b.sign) {
b.sign=1;
return a+b;
}
if (!a.sign) {
a.sign=1;
b=BN(0)-(a+b);
return b;
}
if (a= 0) g = 0;
else {
g = 1;
x += 10;
}
result.s[result.len++] = x;
}
result.clean();
return result;
}
BN BN::operator * (const BN &num)const {
BN result;
result.len = len + num.len;
for (int i = 0; i < len; i++)
for (int j = 0; j < num.len; j++)
result.s[i + j] += s[i] * num.s[j];
for (int i = 0; i < result.len; i++) {
result.s[i + 1] += result.s[i] / 10;
result.s[i] %= 10;
}
result.clean();
result.sign = !(sign^num.sign);
return result;
}
BN BN::operator*(const int num)const {
BN x = num;
BN z = *this;
return x*z;
}
BN BN::operator*=(const BN&num) {
*this = *this * num;
return *this;
}
BN BN::operator /(const BN&num)const {
BN ans;
ans.len = len - num.len + 1;
if (ans.len < 0) {
ans.len = 1;
return ans;
}
BN divisor = *this, divid = num;
divisor.sign = divid.sign = 1;
int k = ans.len - 1;
int j = len - 1;
while (k >= 0) {
while (divisor.s[j] == 0) j--;
if (k > j) k = j;
char z[MAX_L];
memset(z, 0, sizeof(z));
for (int i = j; i >= k; i--)
z[j - i] = divisor.s[i] + '0';
BN dividend = z;
if (dividend < divid) {
k--;
continue;
}
int key = 0;
while (divid*key <= dividend) key++;
key--;
ans.s[k] = key;
BN temp = divid*key;
for (int i = 0; i < k; i++)
temp = temp * 10;
divisor = divisor - temp;
k--;
}
ans.clean();
ans.sign = !(sign^num.sign);
return ans;
}
BN BN::operator/=(const BN&num) {
*this = *this / num;
return *this;
}
BN BN::operator%(const BN& num)const {
BN a = *this, b = num;
a.sign = b.sign = 1;
BN result, temp = a / b*b;
result = a - temp;
result.sign = sign;
return result;
}
BN BN::pow(const BN& num)const {
BN result = 1;
for (BN i = 0; i < num; i++)
result = result*(*this);
return result;
}
BN BN::factorial()const {
BN result = 1;
for (BN i = 1; i <= *this; i++)
result *= i;
return result;
}
void BN::clean() {
if (len == 0) len++;
while (len > 1 && s[len - 1] == '\0')
len--;
}
BN BN::Sqrt()const {
if(*this<0)return -1;
if(*this<=1)return *this;
BN l=0,r=*this,mid;
while(r-l>1) {
mid=(l+r)/2;
if(mid*mid>*this)
r=mid;
else
l=mid;
}
return l;
}
BN::~BN() {
}
int main() {return 0;}
目前想到的只有这些啦
如果有遗漏考场上现yy吧
预祝NOIp2017 RP++ 頑張って!
flag:拿了1=我就女装给你们看