Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks
从树结构的长短期记忆网络改进语义表示

图1:上:链结构LSTM网络。下:具有任意分支因子的树状结构LSTM网络。
1 简介
用于短语和句子的分布式表示的大多数模型——即使用实值向量来表示意义的模型——属于三个类别之一:
- 词袋模型
- 序列模型
- 树结构模型
在词袋模型中,短语和句子表示独立于词序:例如,它们可以通过平均构成词表示来生成(Landauer和Dumais,1997; Foltz等,1998)。相反,序列模型构造句子表示作为令牌序列的顺序敏感函数(Elman,1990; Mikolov,2012)。最后,树形结构模型根据句子上的给定句法结构,从其构成的子词组成每个短语和句子表示(Goller和Kuchler,1996; Socher等,2011)。
对顺序不敏感的模型不足以完全捕捉自然语言的语义,因为它们无法解释由于词序或句法结构的差异导致的意义差异(例如,“猫爬树”与“猫爬树”) )。因此,我们转向有序的顺序或树状结构模型。特别是,树状结构模型是一种语言上具有吸引力的选择,因为它们与句子结构的句法解释有关。那么,一个自然的问题是:在多大程度上(如果有的话)我们可以用树状结构模型做得更好,而不是句子表示的顺序模型?在本文中,我们通过直接比较最近用于实现若干NLP任务中的最新结果的顺序模型类型与其树结构化泛化来解决该问题。
在我们的评估中,我们证明了Tree-LSTMs的经验强度作为表示句子的模型。我们在两个任务上评估Tree-LSTM架构:句子对的语义相关性预测和从电影评论中得出的句子的情感分类。我们的实验表明,Tree-LSTM在两个任务上都优于现有系统和顺序LSTM基线。我们的模型和实验的实现可以在https://github.com/stanfordnlp/treelstm上找到。
2 LSTM
2.1 概述
递归神经网络(RNN)能够通过在隐藏状态向量上递归应用转换函数来处理任意长度的输入序列。在每个时间步,隐藏状态是网络在时间接收的输入矢量及其先前隐藏状态的函数。例如,输入向量可以是文本正文中第t个单词的向量表示(Elman,1990; Mikolov,2012)。隐藏状态可以被解释为直到时间t观察到的记号序列的d维分布式表示。
通常,RNN转换函数是一个自然变换,然后是逐点非线性,如双曲正切函数:
不幸的是,具有这种形式的转变函数的RNN的问题在于,在训练期间,梯度向量的组分可以在长序列上指数地增长或衰减(Hochreiter,1998; Bengio等,1994)。随着梯度爆炸或消失的这个问题使得RNN模型难以学习序列中的长距离相关性。
LSTM架构(Hochreiter和Schmidhuber,1997)通过引入能够长时间保持状态的存储器单元来解决学习长期依赖性的问题。虽然已经描述了许多LSTM变体,但在这里我们描述了Zaremba和Sutskever(2014)使用的版本。
我们在每个时间步骤t将LSTM单元定义为中的向量集合:输入门,忘记门,输出门,存储器单元和隐藏状态。门控向量,和的元素位于中。我们将d称为LSTM的记忆维度。
LSTM的计算公式如下:

其中是当前时间步的输入,表示逻辑Sigmod函数,⊙表示元素乘法。直观地,遗忘门控制忘记前一个记忆细胞的程度,输入门控制每个单元的更新程度,输出门控制内部记忆状态的曝光。因此,LSTM单元中的隐藏状态向量是单元内部记忆细胞状态的门控局部视图。由于门控变量的值对于每个矢量元素而变化,因此模型可以学习在多个时间尺度上表示信息。
2.2 LSTM变种
两种常用的基本LSTM架构变体:
- 双向LSTM
- 多层LSTM(也称为堆叠或深LSTM)。
双向LSTM:双向LSTM(Graves等,2013)由两个并行运行的LSTM组成:一个在输入序列上,另一个在输入序列的反向上。在每个时间步,双向LSTM的隐藏状态是前向和后向隐藏状态的串联。此设置允许隐藏状态捕获过去和未来信息。
多层LSTM:在多层LSTM架构中,层l中LSTM单元的隐藏状态在同一时间步骤中用作层中LSTM单元的输入(Graves等,2013; Sutskever等,2014; Zaremba和Sutskever, 2014)。这里的想法是让更高层捕获输入序列的长度依赖性。
这两种变体可以组合成多层双向LSTM(Graves等,2013)。
3 树结构的LSTM
上一节中描述的LSTM体系结构的局限性在于它们仅允许严格的顺序信息传播。在这里,我们提出了基本LSTM架构的两个自然扩展:
- Child-Sum Tree-LSTM
- N-ary Tree-LSTM
两种变体都允许更丰富的网络拓扑,其中每个LSTM单元能够合并来自多个子单元的信息。
与标准LSTM单元一样,每个Tree-LSTM单元(由j索引)包含输入和输出门和,记忆细胞和隐藏状态。标准LSTM单元和Tree-LSTM单元之间的区别在于门控向量和记忆细胞更新取决于可能许多子单元的状态。另外,Tree-LSTM单元不是单个遗忘门,而是为每个孩子k包含一个遗忘门。这允许Tree-LSTM单元选择性地合并来自每个孩子的信息。例如,Tree-LSTM模型可以学习在语义相关性任务中强调语义头,或者它可以学习如何保持情感丰富的孩子的表达以用于情感分类。
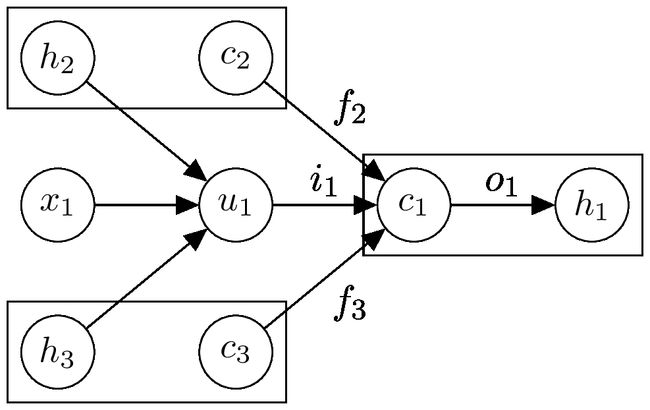
图2:组合具有两个子节点(下标2和3)的Tree-LSTM单元的记忆细胞
与标准LSTM一样,每个Tree-LSTM单元采用输入向量
3.1 Child-Sum Tree-LSTMs
给定树,让表示节点j的子集。Child-Sum Tree-LSTM转换方程式如下:

在公式(4)中,
直观地,我们可以将这些方程中的每个参数矩阵解释为编码Tree-LSTM单元的分量矢量,输入
依存树-LSTM。由于ChildSum Tree-LSTM单元在孩子隐藏状态
3.2 N-ary tree-LSTMs
N -ary Tree-LSTM可用于树结构,其中分支因子最多为N,并且子项是有序的,即它们可以从1到N索引。对于任何节点j,分别将其第k个孩子节点的隐藏状态和记忆细胞写为和。N-Tree Tree-LSTM转换方程如下:
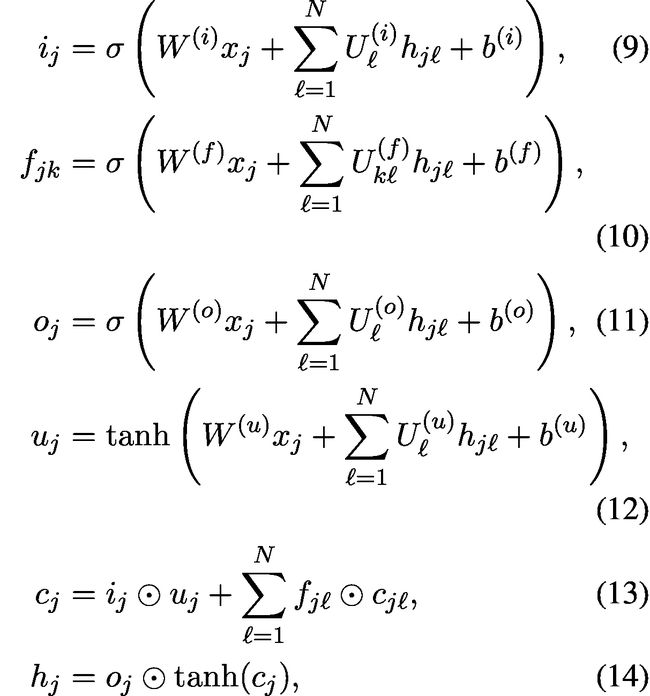
在公式(10)中,
为每个孩子k引入单独的参数矩阵允许N-Tree Tree-LSTM模型在单元的孩子的状态上学习比ChildSum Tree-LSTM更细粒度的条件。例如,考虑一个选区树应用程序,其中节点的左孩子节点对应于名词短语,右孩子节点对应动词短语。假设在这种情况下强调表示中的动词短语是有利的。然后可以训练
忘记门参数化。在Eq.10中,我们定义了包含“非对角线”参数矩阵
句法解析器生成的递归二叉树结构(Constituency Tree-LSTMs)。我们可以自然地将二叉树-LSTM单元应用于二值化选区树,因为区分了左右子节点。我们将二元树-LSTM的这种应用称为选区树-LSTM。注意,在选区树-LSTM中,节点j仅在它是叶节点时才接收输入向量
在本文的其余部分,我们将重点介绍依赖树-LSTM和选区树-LSTM的特殊情况。事实上,这些架构密切相关;由于我们只考虑二值化选区树,因此两个模型的参数化非常相似。关键区别在于组成参数的应用:依赖树与LSTM的依赖与头部,以及选区树-LSTM的左孩子与右孩子。
4 模型
我们现在描述两个应用上一节中描述的Tree-LSTM架构的特定模型。
4.1 Tree-LSTM分类
在此背景中,我们希望从树的一些子节点的一组离散类Y中预测标签。例如,解析树中节点的标签可以对应于该节点所跨越的短语的某些属性。
在每个节点j,我们使用softmax分类器来预测标签,给定在以j为根的子树中的节点处观察到的输入。分类器将节点处的隐藏状态作为输入:

代价函数是每个标记节点上正确类标签

其中m是训练集中标记节点的数量,上标k表示第k个标记节点,λ是L2正则化超参数。
4.2 句子对的语义相关性
给定句子对,我们希望预测在某个范围内的实值相似度得分,其中是整数。序列是一些序数相似度,其中较高的分数表示较高的相似度,并且我们允许实值分数考虑地面实况等级,这是几个人类注释者的评估的平均值。我们首先使用每个句子的解析树上的Tree-LSTM模型为对中的每个句子生成句子表示和。给定这些句子表示,我们使用神经网络预测的相似性得分,该神经网络同时考虑对之间的距离和角度:
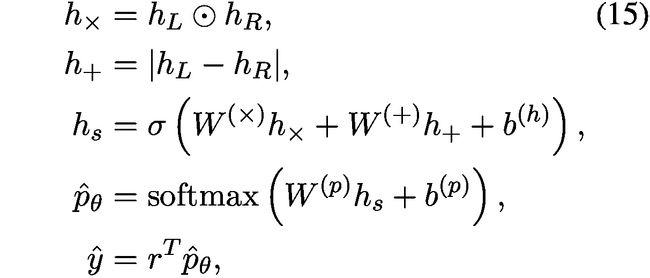
其中
我们希望给定模型参数θ的预测分布
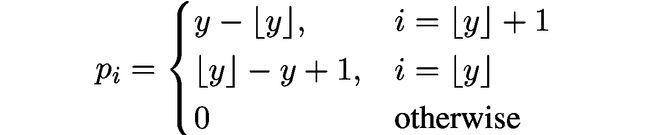
对于
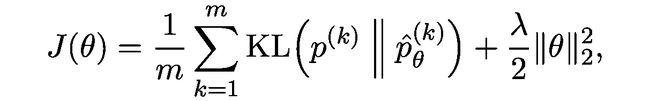
其中m是训练对的数量,上标k表示第k个句子对。