学习思路
1、先看官方文档,学习如何使用python调用caffe2包,包括
- Basics of Caffe2 - Workspaces, Operators, and Nets
- Toy Regression
- Image Pre-Processing
- Loading Pre-Trained Models
- MNIST - Create a CNN from Scratch
caffe2官方教程以python语言为主,指导如何使用python调用caffe2,文档依次从最基本caffe中的几个重要的类的概念、如何使用基础类搭建一个小网络、如何数据预处理、如何使用预训练的模型、如何构造复杂的网络来讲述caffe2的使用。初学者可以先行学习官方文档caffe2-tutorials,理解caffe2 中的网络构建、网络训练的理念与思路,体会caffe2与caffe在整体构造上的不同。
2、结合着caffe2源码看python实际调用的c++类
在python中,caffe2这个包中类与函数大部分是封装了源码文件夹caffe2/caffe2/core下的c++源文件,如基础数据类Tensor,操作类Operator等,通过使用python中类的使用,找到对应c++源码中类和函数的构造和实现,可以为使用c++直接构建和训练网络打下准备。
以下总结基于官方文档和部分网络资料。
基础知识
首先从我们自己的角度出发来思考,假设我们自己需要写一个简单的多层神经网络并训练,一般逻辑上我们需要考虑数据的定义、数据的流动 、数据的更新。
- 数据如何定义:训练数据和网络参数以什么形式存储
- 数据如何流动:训练数据经过哪些运算得到输出,其实就是网络的定义
- 数据如何更新:使用什么样的梯度更新方法与参数,其实就是如何训练
在caffe中,数据储存在Blob类的实例当中,在这里,我们可以理解blob就像是numpy中数组,起的作用就是存储数据。输入的blobs经过不同层的往前传递,得到输出的blobs,caffe中,我们可以认为对数据最基本的运算单位是layer。每一层的layer定义了不同的计算方式,数据经过不同的层,都做了相应的运算,由这些layers组合到一起网络即构成了net,net本质上是一个计算网络。当数据流动的方式构建好了,反向传递的梯度计算的方式也确定,在这个基础之上,caffe中使用solver类来给定梯度更新的规则,网络在solver的控制下,不断让数据前传,再反传求梯度,再使用梯度更新权值,循环往复。
所以对应着caffe中,基础组成有四类:
- blob:存储数据和权值
- layer:输入数据blob 形式,输出数据blob形式,层定义了计算
- net:由多个layers组成,构成整体的网络
- solver:定义了训练规则
再看caffe2中:
在caffe2中,operator是caffe2中的特色,取代了caffe中layer作为net的基本构造单位。如下图所示,我们可以使用一个InnerProduct操作运输符号来完成InnerProductLayer的功能。operator的接口定义在caffe2/proto/caffe2.proto,一般来说,operator接受一串输入,产生一串输出。
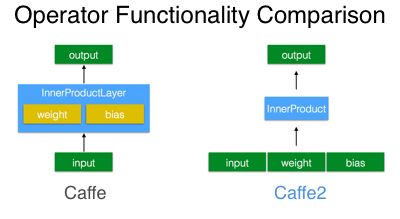
由于operator定义很基础,很抽象,因此caffe2中的权值初始化、前传、反传、梯度更新都可以用operator实现,所以solver、layer类在caffe2中都不是必要的。在caffe2中,对应的基础组成有
- blob:存储数据
- operator:输入blob,输出blob,定义了计算规则
- 网络:net,由多个operator组合实现
- workspace:caffe中没有,可以理解成变量的空间,便于管理网络和变量
具体使用和理解如下,先用python:
在使用之前,我们先导入caffe2.core和workspace,基础的类和函数都在其中。同时我们需要导入caffe2.proto来对protobuf文件进行必要操作。
# We'll also import a few standard python libraries
from matplotlib import pyplot
import numpy as np
import time
# These are the droids you are looking for.
from caffe2.python import core, workspace
from caffe2.proto import caffe2_pb2
# Let's show all plots inline.
%matplotlib inline
1、workspace
我们可以把workspace理解成matlab中变量存储区,我们可以把定义好的数据blob或net放到都在一个workspace中,也可以用不用的workspace来区分。
下面我们打印一下当前workspace中blob情况。Blobs()取出blob,HasBlobs(name)判断是否有此名字的blob。
print("Current blobs in the workspace: {}".format(workspace.Blobs()))
print("Workspace has blob 'X'? {}".format(workspace.HasBlob("X")))
一开始,当然结果是啥也没有。
我们使用FeedBlob来给当前workspace添加blob,再打印出来:
X = np.random.randn(2, 3).astype(np.float32)
print("Generated X from numpy:\n{}".format(X))
workspace.FeedBlob("X", X)
Generated X from numpy:
[[-0.56927377 -1.28052795 -0.95808828]
[-0.44225693 -0.0620895 -0.50509363]]
print("Current blobs in the workspace: {}".format(workspace.Blobs()))
print("Workspace has blob 'X'? {}".format(workspace.HasBlob("X")))
print("Fetched X:\n{}".format(workspace.FetchBlob("X")))
Current blobs in the workspace: [u'X']
Workspace has blob 'X'? True
Fetched X:
[[-0.56927377 -1.28052795 -0.95808828]
[-0.44225693 -0.0620895 -0.50509363]]
当然,我们也用多个名字定义多个workspace,并且可以切换工作空间。我们可以使用currentworkspace()在访问当前工作空间,使用switchworkspace(name)来切换工作空间。
print("Current workspace: {}".format(workspace.CurrentWorkspace()))
print("Current blobs in the workspace: {}".format(workspace.Blobs()))
# Switch the workspace. The second argument "True" means creating
# the workspace if it is missing.
workspace.SwitchWorkspace("gutentag", True)
# Let's print the current workspace. Note that there is nothing in the
# workspace yet.
print("Current workspace: {}".format(workspace.CurrentWorkspace()))
print("Current blobs in the workspace: {}".format(workspace.Blobs()))
Current workspace: default
Current blobs in the workspace: ['X']
Current workspace: gutentag
Current blobs in the workspace: []
总结一下,在这里workspace功能类似于matlab中的工作区,变量存储在其中,我们可以通过工作区去访问在工作区中net和blob。
2、Operators
通常我们在python中,可以使用core.CreateOperator来直接创造,也可以使用core.Net来访问创建operator,还可以使用modelHelper来访问创建operators。在这里我们使用core.CreateOperator来简单理解operator,在实际情况下,我们创建网络的时候,不会直接创建每个operator,这样太麻烦,一般使用modelhelper来帮忙我们创建网络。
# Create an operator.
op = core.CreateOperator(
"Relu", # The type of operator that we want to run
["X"], # A list of input blobs by their names
["Y"], # A list of output blobs by their names
)
# and we are done!
上面的代码创建了一个Relu运算符,在这里需要知道,在python中创建一个operator,只是定义了一个operator,其实并没有运行这个operator。在上面代码中创建的op,实际上是一个protobuf对象。
print("Type of the created op is: {}".format(type(op)))
print("Content:\n")
print(str(op))
Type of the created op is:
Content:
input: "X"
output: "Y"
name: ""
type: "Relu"
在创造op之后,我们在当前的工作区中添加输入X,然后使用RunOperatorOnce运行这个operator。运行之后,我们对比下得到的结果。
workspace.FeedBlob("X", np.random.randn(2, 3).astype(np.float32))
workspace.RunOperatorOnce(op)
print("Current blobs in the workspace: {}\n".format(workspace.Blobs()))
print("X:\n{}\n".format(workspace.FetchBlob("X")))
print("Y:\n{}\n".format(workspace.FetchBlob("Y")))
print("Expected:\n{}\n".format(np.maximum(workspace.FetchBlob("X"), 0)))
Current blobs in the workspace: ['X', 'Y']
X:
[[ 1.03125858 1.0038228 0.0066975 ]
[ 1.33142471 1.80271244 -0.54222912]]
Y:
[[ 1.03125858 1.0038228 0.0066975 ]
[ 1.33142471 1.80271244 0. ]]
Expected:
[[ 1.03125858 1.0038228 0.0066975 ]
[ 1.33142471 1.80271244 0. ]]
此外,operator相对于layer更为抽象。operator不仅仅可以替代layer类,还可以接受无参数的输入来输出数据,从而用来生成数据,常用来初始化权值。下面这一段就可以用来初始化权值。
op = core.CreateOperator(
"GaussianFill",
[], # GaussianFill does not need any parameters.
["W"],
shape=[100, 100], # shape argument as a list of ints.
mean=1.0, # mean as a single float
std=1.0, # std as a single float
)
print("Content of op:\n")
print(str(op))
Content of op:
output: "W"
name: ""
type: "GaussianFill"
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 100
ints: 100
}
arg {
name: "mean"
f: 1.0
}
workspace.RunOperatorOnce(op)
temp = workspace.FetchBlob("Z")
pyplot.hist(temp.flatten(), bins=50)
pyplot.title("Distribution of Z")
3、Nets
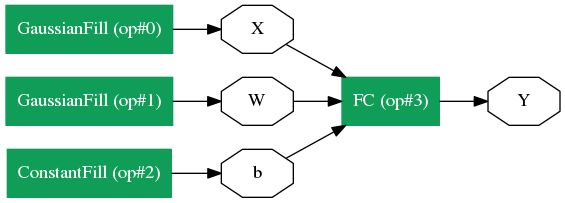
Nets是一系列operator的集合,从本质上,是由operator构成的计算图。Caffe2中core.net 封装了源码中 NetDef 类。我们举个栗子,创建网络来实现以下的公式。
X = np.random.randn(2, 3)
W = np.random.randn(5, 3)
b = np.ones(5)
Y = X * W^T + b
首先创建网络:
net = core.Net("my_first_net")
print("Current network proto:\n\n{}".format(net.Proto()))
Current network proto:
name: "my_first_net"
首先使用生成权值和输入,在这里,使用core.net来访问创建:
X = net.GaussianFill([], ["X"], mean=0.0, std=1.0, shape=[2, 3], run_once=0)
print("New network proto:\n\n{}".format(net.Proto()))
W = net.GaussianFill([], ["W"], mean=0.0, std=1.0, shape=[5, 3], run_once=0)
b = net.ConstantFill([], ["b"], shape=[5,], value=1.0, run_once=0)
生成输出:
Y = net.FC([X, W, b], ["Y"])
我们打印下当前的网络:
print("Current network proto:\n\n{}".format(net.Proto()))
Current network proto:
name: "my_first_net"
op {
output: "X"
name: ""
type: "GaussianFill"
arg {
name: "std"
f: 1.0
}
arg {
name: "run_once"
i: 0
}
arg {
name: "shape"
ints: 2
ints: 3
}
arg {
name: "mean"
f: 0.0
}
}
op {
output: "W"
name: ""
type: "GaussianFill"
arg {
name: "std"
f: 1.0
}
arg {
name: "run_once"
i: 0
}
arg {
name: "shape"
ints: 5
ints: 3
}
arg {
name: "mean"
f: 0.0
}
}
op {
output: "b"
name: ""
type: "ConstantFill"
arg {
name: "run_once"
i: 0
}
arg {
name: "shape"
ints: 5
}
arg {
name: "value"
f: 1.0
}
}
op {
input: "X"
input: "W"
input: "b"
output: "Y"
name: ""
type: "FC"
}
在这里,我们可以画出来定义的网络:
from caffe2.python import net_drawer
from IPython import display
graph = net_drawer.GetPydotGraph(net, rankdir="LR")
display.Image(graph.create_png(), width=800)
和operator类似,在这里我们只定义了一个net,但是并没有运行net的计算。当我们在python运行网络时,实际上在c++层面做了两件事情:
- 由protobuf定义初始化c++ 的net对象
- 调用初始化了的net的run函数
在python中有两种方法来运行一个net:
- 方法1:使用workspace.RunNetOnce,初始化网络,运行网络,然后销毁网络。
- 方法2:先使用workspace.CreateNet初始化网络,然后使用workspace.RunNet来运行网络
方法一:
workspace.ResetWorkspace()
print("Current blobs in the workspace: {}".format(workspace.Blobs()))
workspace.RunNetOnce(net)
print("Blobs in the workspace after execution: {}".format(workspace.Blobs()))
# Let's dump the contents of the blobs
for name in workspace.Blobs():
print("{}:\n{}".format(name, workspace.FetchBlob(name)))
Current blobs in the workspace: []
Blobs in the workspace after execution: ['W', 'X', 'Y', 'b']
W:
[[-0.29295802 0.02897477 -1.25667715]
[-1.82299471 0.92877913 0.33613944]
[-0.64382178 -0.68545657 -0.44015241]
[ 1.10232282 1.38060772 -2.29121733]
[-0.55766547 1.97437167 0.39324901]]
X:
[[-0.47522315 -0.40166432 0.7179445 ]
[-0.8363331 -0.82451206 1.54286408]]
Y:
[[ 0.22535783 1.73460138 1.2652775 -1.72335696 0.7543118 ]
[-0.71776152 2.27745867 1.42452145 -4.59527397 0.4452306 ]]
b:
[ 1. 1. 1. 1. 1.]
方法二:
workspace.ResetWorkspace()
print("Current blobs in the workspace: {}".format(workspace.Blobs()))
workspace.CreateNet(net)
workspace.RunNet(net.Proto().name)
print("Blobs in the workspace after execution: {}".format(workspace.Blobs()))
for name in workspace.Blobs():
print("{}:\n{}".format(name, workspace.FetchBlob(name)))
Current blobs in the workspace: []
Blobs in the workspace after execution: ['W', 'X', 'Y', 'b']
W:
[[-0.29295802 0.02897477 -1.25667715]
[-1.82299471 0.92877913 0.33613944]
[-0.64382178 -0.68545657 -0.44015241]
[ 1.10232282 1.38060772 -2.29121733]
[-0.55766547 1.97437167 0.39324901]]
X:
[[-0.47522315 -0.40166432 0.7179445 ]
[-0.8363331 -0.82451206 1.54286408]]
Y:
[[ 0.22535783 1.73460138 1.2652775 -1.72335696 0.7543118 ]
[-0.71776152 2.27745867 1.42452145 -4.59527397 0.4452306 ]]
b:
[ 1. 1. 1. 1. 1.]
在这里,大家可能比较疑惑为什么会有两种运行网络的方式,在之后的实际应用中,大家就会慢慢理解,在这里,暂时记住有这样两种运行网络的方式即可。
总结一下,在caffe2中
- workspace是工作空间,在worspace中,可以存储网络结构类Net和数据存储类Blob.
- 输入数据、权值、输出数据都存储在Blob中
- Operator类用来定义来数据如何计算,由多个operators构成Net,operator的作用强大
- Net类是由operator构成的整体。
应用举例
在基础知识中,我们理解了workspace,operator,net等基本的概念,在这里我们结合caffe2的官方文档简单举出几个例子。
栗子1-回归的小栗子
第一个栗子帮助大家理解caffe2框架网络构建、参数初始化、训练、图等的一些关于整体框架的理念。
假设我们要做训练一个简单的网络,拟合下面这样的一个回归函数:
y = wx + b
其中:w=[2.0, 1.5] b=0.5
一般训练数据是从外部读进来,在这里训练数据我们直接用caffe2中的operator生成,我们在后面的栗子中有会举例说明如何从外部读入数据。
首先导入必要的包:
from caffe2.python import core, cnn, net_drawer, workspace, visualize
import numpy as np
from IPython import display
from matplotlib import pyplot
在这里,首先我们需要建立两个网络图:
- 一个用来生成训练数据、初始化权值的网络图
- 一个用来用来训练,更新剃度的网络图
这里caffe2的思路和caffe不太一样,在caffe中,我们在训练网络中定义好了参数的初始化方式,网络加载时,程序会根据网络定义,自动初始化权值,我们只需要对这个网络,使用solver不断的前传和反传,更新参数即可。在caffe2中,我们要把所有网络的搭建、初始化、梯度生成、梯度更新都使用operator这样一个方式来实现,所有的数据的生成、流动都要在图中反映出来。这样,那么初始化这一部分我就需要一些operators来实现,这些operators组成的net,我们把它单独拿出来,称它为用于初始化的网络。我们可以结合着代码来理解。
首先,我们创建一个生成训练数据和初始化权值的网络。
init_net = core.Net("init")
# The ground truth parameters.
W_gt = init_net.GivenTensorFill(
[], "W_gt", shape=[1, 2], values=[2.0, 1.5])
B_gt = init_net.GivenTensorFill([], "B_gt", shape=[1], values=[0.5])
# Constant value ONE is used in weighted sum when updating parameters.
ONE = init_net.ConstantFill([], "ONE", shape=[1], value=1.)
# ITER is the iterator count.
ITER = init_net.ConstantFill([], "ITER", shape=[1], value=0, dtype=core.DataType.INT32)
# For the parameters to be learned: we randomly initialize weight
# from [-1, 1] and init bias with 0.0.
W = init_net.UniformFill([], "W", shape=[1, 2], min=-1., max=1.)
B = init_net.ConstantFill([], "B", shape=[1], value=0.0)
print('Created init net.')
接下来,我们定义一个用来训练的网络。
train_net = core.Net("train")
# First, we generate random samples of X and create the ground truth.
X = train_net.GaussianFill([], "X", shape=[64, 2], mean=0.0, std=1.0, run_once=0)
Y_gt = X.FC([W_gt, B_gt], "Y_gt")
# We add Gaussian noise to the ground truth
noise = train_net.GaussianFill([], "noise", shape=[64, 1], mean=0.0, std=1.0, run_once=0)
Y_noise = Y_gt.Add(noise, "Y_noise")
# Note that we do not need to propagate the gradients back through Y_noise,
# so we mark StopGradient to notify the auto differentiating algorithm
# to ignore this path.
Y_noise = Y_noise.StopGradient([], "Y_noise")
# Now, for the normal linear regression prediction, this is all we need.
Y_pred = X.FC([W, B], "Y_pred")
# The loss function is computed by a squared L2 distance, and then averaged
# over all items in the minibatch.
dist = train_net.SquaredL2Distance([Y_noise, Y_pred], "dist")
loss = dist.AveragedLoss([], ["loss"])
我们来画出我们定义的训练网络的图:
graph = net_drawer.GetPydotGraph(train_net.Proto().op, "train", rankdir="LR")
display.Image(graph.create_png(), width=800)

在这里,通过上面的图,我们可以看到init_net部分生成了训练数据、初始化的权值W,以及用来生成计算过程中需要的常数矩阵,而train_net构建了前向计算过程。
但是我们还没有定义如何反向传导,和很多其他的深度学习框架类似,caffe2支持自动梯度推导,自动生成产生梯度的operator。
接下来,我们给train_net加上梯度运算:
# Get gradients for all the computations above.
gradient_map = train_net.AddGradientOperators([loss])
graph = net_drawer.GetPydotGraph(train_net.Proto().op, "train", rankdir="LR")
display.Image(graph.create_png(), width=800)

可以看到,网络后半部分进行了求梯度运算,输出了各学习参数的梯度值,当我们得到这些梯度值后,我们再获得当前训练的学习率,我们就可以使用梯度下降方法更新参数。
接下来,我们在train_net加上SGD更新的部分:
# Increment the iteration by one.
train_net.Iter(ITER, ITER)
# Compute the learning rate that corresponds to the iteration.
LR = train_net.LearningRate(ITER, "LR", base_lr=-0.1,
policy="step", stepsize=20, gamma=0.9)
# Weighted sum
train_net.WeightedSum([W, ONE, gradient_map[W], LR], W)
train_net.WeightedSum([B, ONE, gradient_map[B], LR], B)
# Let's show the graph again.
graph = net_drawer.GetPydotGraph(train_net.Proto().op, "train", rankdir="LR")
display.Image(graph.create_png(), width=800)

到这里,整个模型的参数初始化、前传、反传、梯度更新全都使用operator定义好了。这个就是caffe2中使用operator的威力,它使得caffe2较caffe具有不可比拟的灵活性。在这里注意,我们只是定义了网络,还没有运行网络,下面让我们来运行它们:
workspace.RunNetOnce(init_net)
workspace.CreateNet(train_net)
print("Before training, W is: {}".format(workspace.FetchBlob("W")))
print("Before training, B is: {}".format(workspace.FetchBlob("B")))
True
Before training, W is: [[-0.77634162 -0.88467366]]
Before training, B is: [ 0.]
#run the train net 100 times
for i in range(100):
workspace.RunNet(train_net.Proto().name)
print("After training, W is: {}".format(workspace.FetchBlob("W")))
print("After training, B is: {}".format(workspace.FetchBlob("B")))
print("Ground truth W is: {}".format(workspace.FetchBlob("W_gt")))
print("Ground truth B is: {}".format(workspace.FetchBlob("B_gt")))
在这里,我们需要注意一点,我们使用了RunNetOnce和RunNet两种不同的方式来运行网络,还记得两种运行网络的方式么?
- 方法1:使用workspace.RunNetOnce,这个函数会初始化网络,运行网络,然后销毁网络。
- 方法2:先使用workspace.CreateNet初始化网络,然后使用workspace.RunNet来运行网络
一开始我也不明白为什么要有两种方式运行网络,现在结合init_net和train_net来看,就非常明白了。RunNetOnce用来运行生成权值和数据的网络,常用于初始化,这样的网络一次生成完,权值输出或数据就存在当前的workspace中,网络本身就没有存在的必要了,就直接销毁,而RunNet可以用来重复训练网络,一开始使用CreateNet,不断迭代调用RunNet就可以不断运行网络更新参数了。
以下是训练结果:
After training, W is: [[ 1.95769441 1.47348857]]
After training, B is: [ 0.45236012]
Ground truth W is: [[ 2. 1.5]]
Ground truth B is: [ 0.5]
,总结一下:
- caffe2中使用operator完成初始化参数、前传、反传、梯度更新
- caffe2中一个模型通常包含一个初始化网络,一个训练网络
最后,还要说明一点,这个例子中,我们直接使用operator来构建网络。对于常见的深度网络,直接用operator构建会步骤会非常繁琐,所以caffe2中为了简化网络的搭建,又封装了model_helper类来帮助我们方便地搭建网络,譬如对于卷积神经网络中的常见的层,我们就可以直接使用model_helper来构建。在之后的栗子中也有说明。
栗子二-图像预处理
众所周知,网络中训练需要做一系列的数据预处理,在这里,caffe和caffe2中处理的方式一样。都需要经过XXX等步。因为没有什么区别,在这里就不举了,直接参考官方教程Image Pre-Processing,解释非常清楚。给个赞。
栗子三-加载预训练模型
首先,我们使用一个caffe2中定义的下载模块去下载一个预训练好的模型,命令行中输入如下的命令会下载squeezenet这个预训练模型:
python -m caffe2.python.models.download -i squeezenet
当下载完成时,在caffe2/python/model底下有一个squeezenet文件,文件夹底下有两个文件init_net.pb,predict_net.pb分别保存了权值和网络定义。
在python中我们使用caffe2的workspace来存放这个模型的网络定义和权重,并且把它们加载到blob、init_net和predict_net。我们需要使用一个workspace.Predictor来接收两个protobuf,然后剩下的就可以交给caffe2了。
所以一般加载预测模型只需要几步:
1、读入protobuf文件
with open("init_net.pb") as f:
init_net = f.read()
with open("predict_net.pb") as f:
predict_net = f.read()
2、使用workspace中的Predictor来加载从protobuf中取到的blobs:
p = workspace.Predictor(init_net, predict_net)
3、运行网络,得到结果:
results = p.run([img])
需要注意的这里的img是预处理过的图像。
以下是官方文档下的一个完整的栗子:
首先配置一下问文件路径等,导入常用包:
# where you installed caffe2\. Probably '~/caffe2' or '~/src/caffe2'.
CAFFE2_ROOT = "~/caffe2"
# assumes being a subdirectory of caffe2
CAFFE_MODELS = "~/caffe2/caffe2/python/models"
# if you have a mean file, place it in the same dir as the model
%matplotlib inline
from caffe2.proto import caffe2_pb2
import numpy as np
import skimage.io
import skimage.transform
from matplotlib import pyplot
import os
from caffe2.python import core, workspace
import urllib2
print("Required modules imported.")
IMAGE_LOCATION = "https://cdn.pixabay.com/photo/2015/02/10/21/28/flower-631765_1280.jpg"
# What model are we using? You should have already converted or downloaded one.
# format below is the model's:
# folder, INIT_NET, predict_net, mean, input image size
# you can switch the comments on MODEL to try out different model conversions
MODEL = 'squeezenet', 'init_net.pb', 'predict_net.pb', 'ilsvrc_2012_mean.npy', 227
# codes - these help decypher the output and source from a list from AlexNet's object codes to provide an result like "tabby cat" or "lemon" depending on what's in the picture you submit to the neural network.
# The list of output codes for the AlexNet models (also squeezenet)
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac071eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"
print "Config set!"
定义数据预处理的函数:
def crop_center(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]
def rescale(img, input_height, input_width):
print("Original image shape:" + str(img.shape) + " and remember it should be in H, W, C!")
print("Model's input shape is %dx%d") % (input_height, input_width)
aspect = img.shape[1]/float(img.shape[0])
print("Orginal aspect ratio: " + str(aspect))
if(aspect>1):
# landscape orientation - wide image
res = int(aspect * input_height)
imgScaled = skimage.transform.resize(img, (input_width, res))
if(aspect<1):
# portrait orientation - tall image
res = int(input_width/aspect)
imgScaled = skimage.transform.resize(img, (res, input_height))
if(aspect == 1):
imgScaled = skimage.transform.resize(img, (input_width, input_height))
pyplot.figure()
pyplot.imshow(imgScaled)
pyplot.axis('on')
pyplot.title('Rescaled image')
print("New image shape:" + str(imgScaled.shape) + " in HWC")
return imgScaled
print "Functions set."
# set paths and variables from model choice and prep image
CAFFE2_ROOT = os.path.expanduser(CAFFE2_ROOT)
CAFFE_MODELS = os.path.expanduser(CAFFE_MODELS)
# mean can be 128 or custom based on the model
# gives better results to remove the colors found in all of the training images
MEAN_FILE = os.path.join(CAFFE_MODELS, MODEL[0], MODEL[3])
if not os.path.exists(MEAN_FILE):
mean = 128
else:
mean = np.load(MEAN_FILE).mean(1).mean(1)
mean = mean[:, np.newaxis, np.newaxis]
print "mean was set to: ", mean
# some models were trained with different image sizes, this helps you calibrate your image
INPUT_IMAGE_SIZE = MODEL[4]
# make sure all of the files are around...
if not os.path.exists(CAFFE2_ROOT):
print("Houston, you may have a problem.")
INIT_NET = os.path.join(CAFFE_MODELS, MODEL[0], MODEL[1])
print 'INIT_NET = ', INIT_NET
PREDICT_NET = os.path.join(CAFFE_MODELS, MODEL[0], MODEL[2])
print 'PREDICT_NET = ', PREDICT_NET
if not os.path.exists(INIT_NET):
print(INIT_NET + " not found!")
else:
print "Found ", INIT_NET, "...Now looking for", PREDICT_NET
if not os.path.exists(PREDICT_NET):
print "Caffe model file, " + PREDICT_NET + " was not found!"
else:
print "All needed files found! Loading the model in the next block."
# load and transform image
img = skimage.img_as_float(skimage.io.imread(IMAGE_LOCATION)).astype(np.float32)
img = rescale(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
img = crop_center(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print "After crop: " , img.shape
pyplot.figure()
pyplot.imshow(img)
pyplot.axis('on')
pyplot.title('Cropped')
# switch to CHW
img = img.swapaxes(1, 2).swapaxes(0, 1)
pyplot.figure()
for i in range(3):
# For some reason, pyplot subplot follows Matlab's indexing
# convention (starting with 1). Well, we'll just follow it...
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))
# switch to BGR
img = img[(2, 1, 0), :, :]
# remove mean for better results
img = img * 255 - mean
# add batch size
img = img[np.newaxis, :, :, :].astype(np.float32)
print "NCHW: ", img.shape
运行一下,输出结果:
Functions set.
mean was set to: 128
INIT_NET = /home/aaron/models/squeezenet/init_net.pb
PREDICT_NET = /home/aaron/models/squeezenet/predict_net.pb
Found /home/aaron/models/squeezenet/init_net.pb ...Now looking for /home/aaron/models/squeezenet/predict_net.pb
All needed files found! Loading the model in the next block.
Original image shape:(751, 1280, 3) and remember it should be in H, W, C!
Model's input shape is 227x227
Orginal aspect ratio: 1.70439414115
New image shape:(227, 386, 3) in HWC
After crop: (227, 227, 3)
NCHW: (1, 3, 227, 227)



当图像经过处理之后,就可以按照前面的安排加载和运行网络。
# initialize the neural net
with open(INIT_NET) as f:
init_net = f.read()
with open(PREDICT_NET) as f:
predict_net = f.read()
p = workspace.Predictor(init_net, predict_net)
# run the net and return prediction
results = p.run([img])
# turn it into something we can play with and examine which is in a multi-dimensional array
results = np.asarray(results)
print "results shape: ", results.shape
results shape: (1, 1, 1000, 1, 1)
这里输出来了1000个值,表示这张图片分别对应1000类的概率。我们可以取出来其中概率最高的值,来找到它对应的标签:
# the rest of this is digging through the results
results = np.delete(results, 1)
index = 0
highest = 0
arr = np.empty((0,2), dtype=object)
arr[:,0] = int(10)
arr[:,1:] = float(10)
for i, r in enumerate(results):
# imagenet index begins with 1!
i=i+1
arr = np.append(arr, np.array([[i,r]]), axis=0)
if (r > highest):
highest = r
index = i
print index, " :: ", highest
# lookup the code and return the result
# top 3 results
# sorted(arr, key=lambda x: x[1], reverse=True)[:3]
# now we can grab the code list
response = urllib2.urlopen(codes)
# and lookup our result from the list
for line in response:
code, result = line.partition(":")[::2]
if (code.strip() == str(index)):
print result.strip()[1:-2]
985 :: 0.979059
daisy
栗子四-创建一个CNN模型
1、模型、帮助函数、brew
在前面我们已经基本介绍了在python中关于caffe2中基本的操作。
这个例子中,我们来简单搭建一个CNN模型。在这个需要说明一点:
- 在caffe中,我们通常说一个模型,其实就是一个网络,一个Net
- 而在caffe2中,我们通常使用modelHelper来代表一个model,而这个model包含多个Net,就像我们前面看到的,我们会使用一个初始化网络init_net,还有有一个训练网络net,这两个网络图都是model的一部分。
这一点需要大家区分开,不然容易疑惑。举例,如果我们要构造一个模型,只有一个FC层,在这里使用modelHelper来表示一个model,使用operators来构造网络,一般model有一个param_init_net和一个net。分别用于模型初始化和训练:
model = model_helper.ModelHelper(name="train")
# initialize your weight
weight = model.param_init_net.XavierFill(
[],
blob_out + '_w',
shape=[dim_out, dim_in],
**kwargs, # maybe indicating weight should be on GPU here
)
# initialize your bias
bias = model.param_init_net.ConstantFill(
[],
blob_out + '_b',
shape=[dim_out, ],
**kwargs,
)
# finally building FC
model.net.FC([blob_in, weights, bias], blob_out, **kwargs)
前面,我们说过在日常搭建网络的时候呢,我们通常不是完全使用operator搭建网络,因为使用这种方式,每个参数都需要我们手动初始化,以及每个operator都需要构造,太过于繁琐。我们想着,对于常用层,能不能把构造它的operators都封装起来,封装成一个函数,我们构造时只需给这个函数要提供必要的参数,函数中的代码就能帮助我们完成层初始化和operator的构建。
在caffe2中,为了便于开发者搭建网络,caffe2在python/helpers中提供了许多help函数,像上面例子中的FC层,使用python/helpers/fc.py来构造,非常简单就一行代码:
fcLayer = fc(model, blob_in, blob_out, **kwargs) # returns a blob reference
这里面help函数能够帮助我们将权值初始化和计算网络自动分开到两个网络,这样一来就简单多了。caffe2为了更方便调用和管理,把这些帮助函数集合到一起,放在brew这个包里面。可以通过导入brew这个包来调用这些帮助函数。像上面的fc层的实现就可以使用:
from caffe2.python import brew
brew.fc(model, blob_in, blob_out, ...)
我们使用brew构造网络就十分简单,下面的代码就构造了一个LeNet模型:
from caffe2.python import brew
def AddLeNetModel(model, data):
conv1 = brew.conv(model, data, 'conv1', 1, 20, 5)
pool1 = brew.max_pool(model, conv1, 'pool1', kernel=2, stride=2)
conv2 = brew.conv(model, pool1, 'conv2', 20, 50, 5)
pool2 = brew.max_pool(model, conv2, 'pool2', kernel=2, stride=2)
fc3 = brew.fc(model, pool2, 'fc3', 50 * 4 * 4, 500)
fc3 = brew.relu(model, fc3, fc3)
pred = brew.fc(model, fc3, 'pred', 500, 10)
softmax = brew.softmax(model, pred, 'softmax')
caffe2 使用brew提供很多构造网络的帮助函数,大大简化了我们构建网络的过程。但实际上,这些只是封装的结果,网络构造的原理和之前说的使用operators构建的原理是一样的。
2、创建一个CNN模型用于MNIST手写体数据集
首先,导入必要的包:
%matplotlib inline
from matplotlib import pyplot
import numpy as np
import os
import shutil
from caffe2.python import core, model_helper, net_drawer, workspace, visualize, brew
# If you would like to see some really detailed initializations,
# you can change --caffe2_log_level=0 to --caffe2_log_level=-1
core.GlobalInit(['caffe2', '--caffe2_log_level=0'])
print("Necessities imported!")
下载MNIST dataset,并且把数据集转成leveldb:
./make_mnist_db --channel_first --db leveldb --image_file ~/Downloads/train-images-idx3-ubyte --label_file ~/Downloads/train-labels-idx1-ubyte --output_file ~/caffe2_notebooks/tutorial_data/mnist/mnist-train-nchw-leveldb
./make_mnist_db --channel_first --db leveldb --image_file ~/Downloads/t10k-images-idx3-ubyte --label_file ~/Downloads/t10k-labels-idx1-ubyte --output_file ~/caffe2_notebooks/tutorial_data/mnist/mnist-test-nchw-leveldb
# This section preps your image and test set in a leveldb
current_folder = os.path.join(os.path.expanduser('~'), 'caffe2_notebooks')
data_folder = os.path.join(current_folder, 'tutorial_data', 'mnist')
root_folder = os.path.join(current_folder, 'tutorial_files', 'tutorial_mnist')
image_file_train = os.path.join(data_folder, "train-images-idx3-ubyte")
label_file_train = os.path.join(data_folder, "train-labels-idx1-ubyte")
image_file_test = os.path.join(data_folder, "t10k-images-idx3-ubyte")
label_file_test = os.path.join(data_folder, "t10k-labels-idx1-ubyte")
# Get the dataset if it is missing
def DownloadDataset(url, path):
import requests, zipfile, StringIO
print "Downloading... ", url, " to ", path
r = requests.get(url, stream=True)
z = zipfile.ZipFile(StringIO.StringIO(r.content))
z.extractall(path)
def GenerateDB(image, label, name):
name = os.path.join(data_folder, name)
print 'DB: ', name
if not os.path.exists(name):
syscall = "/usr/local/bin/make_mnist_db --channel_first --db leveldb --image_file " + image + " --label_file " + label + " --output_file " + name
# print "Creating database with: ", syscall
os.system(syscall)
else:
print "Database exists already. Delete the folder if you have issues/corrupted DB, then rerun this."
if os.path.exists(os.path.join(name, "LOCK")):
# print "Deleting the pre-existing lock file"
os.remove(os.path.join(name, "LOCK"))
if not os.path.exists(data_folder):
os.makedirs(data_folder)
if not os.path.exists(label_file_train):
DownloadDataset("https://download.caffe2.ai/datasets/mnist/mnist.zip", data_folder)
if os.path.exists(root_folder):
print("Looks like you ran this before, so we need to cleanup those old files...")
shutil.rmtree(root_folder)
os.makedirs(root_folder)
workspace.ResetWorkspace(root_folder)
# (Re)generate the leveldb database (known to get corrupted...)
GenerateDB(image_file_train, label_file_train, "mnist-train-nchw-leveldb")
GenerateDB(image_file_test, label_file_test, "mnist-test-nchw-leveldb")
print("training data folder:" + data_folder)
print("workspace root folder:" + root_folder)
在这里,我们使用modelHelper来代表我们的模型,使用brew和operators来搭建模型,modelHelper包含了两个net,包括param_init_net和net,分别代表初始化网络和主训练网络。
我们来一步一步分块构造模型:
(1)输入部分(AddInput function)
(2)网络计算部分(AddLeNetModel function)
(3)网络训练部分,添加梯度运算,更新等(AddTrainingOperators function)
(4)记录统计部分,打印一些统计数据来观察(AddBookkeepingOperators function)
(1)输入部分(AddInput function)
AddInput会从DB加载data,AddInput加载完成之后,和得到data 和label:
- data with shape `(batch_size, num_channels, width, height)`
- in this case `[batch_size, 1, 28, 28]` of data type *uint8*
- label with shape `[batch_size]` of data type *int*
def AddInput(model, batch_size, db, db_type):
# load the data
data_uint8, label = model.TensorProtosDBInput(
[], ["data_uint8", "label"], batch_size=batch_size,
db=db, db_type=db_type)
# cast the data to float
data = model.Cast(data_uint8, "data", to=core.DataType.FLOAT)
# scale data from [0,255] down to [0,1]
data = model.Scale(data, data, scale=float(1./256))
# don't need the gradient for the backward pass
data = model.StopGradient(data, data)
return data, label
在这里简单解释一下AddInput中的一些操作,首先将data转换成float类型,这样做是因为我们主要做浮点运算。为了保证计算稳定,我们将图像从[0,255]缩放到[0,1],并且这里做的事占位运算,不需要保存未缩放之前的值。当计算反向过程中,这一部分不需要计算梯度,我们使用StopGradient来禁止梯度反传,这样自动生成梯度时,这个operator和它之前的operator就不会变了。
def AddInput(model, batch_size, db, db_type):
# load the data
data_uint8, label = model.TensorProtosDBInput(
[], ["data_uint8", "label"], batch_size=batch_size,
db=db, db_type=db_type)
# cast the data to float
data = model.Cast(data_uint8, "data", to=core.DataType.FLOAT)
# scale data from [0,255] down to [0,1]
data = model.Scale(data, data, scale=float(1./256))
# don't need the gradient for the backward pass
data = model.StopGradient(data, data)
return data, label
在这个基础上,就是加入网络AddLenetModel,同时加入一个AddAccuracy来追踪模型的准确率:
def AddLeNetModel(model, data):
# Image size: 28 x 28 -> 24 x 24
conv1 = brew.conv(model, data, 'conv1', dim_in=1, dim_out=20, kernel=5)
# Image size: 24 x 24 -> 12 x 12
pool1 = brew.max_pool(model, conv1, 'pool1', kernel=2, stride=2)
# Image size: 12 x 12 -> 8 x 8
conv2 = brew.conv(model, pool1, 'conv2', dim_in=20, dim_out=50, kernel=5)
# Image size: 8 x 8 -> 4 x 4
pool2 = brew.max_pool(model, conv2, 'pool2', kernel=2, stride=2)
# 50 * 4 * 4 stands for dim_out from previous layer multiplied by the image size
fc3 = brew.fc(model, pool2, 'fc3', dim_in=50 * 4 * 4, dim_out=500)
fc3 = brew.relu(model, fc3, fc3)
pred = brew.fc(model, fc3, 'pred', 500, 10)
softmax = brew.softmax(model, pred, 'softmax')
return softmax
def AddAccuracy(model, softmax, label):
accuracy = model.Accuracy([softmax, label], "accuracy")
return accuracy
接下来,我们将加入梯度生成和更新,这部分由AddTrainingOperators实现,梯度生成和更新和之前例子中的原理一样。
def AddTrainingOperators(model, softmax, label):
# something very important happens here
xent = model.LabelCrossEntropy([softmax, label], 'xent')
# compute the expected loss
loss = model.AveragedLoss(xent, "loss")
# track the accuracy of the model
AddAccuracy(model, softmax, label)
# use the average loss we just computed to add gradient operators to the model
model.AddGradientOperators([loss])
# do a simple stochastic gradient descent
ITER = model.Iter("iter")
# set the learning rate schedule
LR = model.LearningRate(
ITER, "LR", base_lr=-0.1, policy="step", stepsize=1, gamma=0.999 )
# ONE is a constant value that is used in the gradient update. We only need
# to create it once, so it is explicitly placed in param_init_net.
ONE = model.param_init_net.ConstantFill([], "ONE", shape=[1], value=1.0)
# Now, for each parameter, we do the gradient updates.
for param in model.params:
# Note how we get the gradient of each parameter - ModelHelper keeps
# track of that.
param_grad = model.param_to_grad[param]
# The update is a simple weighted sum: param = param + param_grad * LR
model.WeightedSum([param, ONE, param_grad, LR], param)
# let's checkpoint every 20 iterations, which should probably be fine.
# you may need to delete tutorial_files/tutorial-mnist to re-run the tutorial
model.Checkpoint([ITER] + model.params, [],
db="mnist_lenet_checkpoint_%05d.leveldb",
db_type="leveldb", every=20)
接下来,我们使用AddBookkeepingOperations来打印一些统计数据供我们之后观察,这一部分不影响训练部分,只是统计,打印日志。
def AddBookkeepingOperators(model):
# Print basically prints out the content of the blob. to_file=1 routes the
# printed output to a file. The file is going to be stored under
# root_folder/[blob name]
model.Print('accuracy', [], to_file=1)
model.Print('loss', [], to_file=1)
# Summarizes the parameters. Different from Print, Summarize gives some
# statistics of the parameter, such as mean, std, min and max.
for param in model.params:
model.Summarize(param, [], to_file=1)
model.Summarize(model.param_to_grad[param], [], to_file=1)
# Now, if we really want to be verbose, we can summarize EVERY blob
# that the model produces; it is probably not a good idea, because that
# is going to take time - summarization do not come for free. For this
# demo, we will only show how to summarize the parameters and their
# gradients.
print("Bookkeeping function created")
在这里,我们一共做了四件事:
(1)输入部分(AddInput function)
(2)网络计算部分(AddLeNetModel function)
(3)网络训练部分,添加梯度运算,更新等(AddTrainingOperators function)
(4)记录统计部分,打印一些统计数据来观察(AddBookkeepingOperators function)
基本的操作我们都定义好了,接下来调用定义模型,在这里,它定义了一个训练模型,用于训练,一个部署模型,用于部署:
arg_scope = {"order": "NCHW"}
train_model = model_helper.ModelHelper(name="mnist_train", arg_scope=arg_scope)
data, label = AddInput(
train_model, batch_size=64,
db=os.path.join(data_folder, 'mnist-train-nchw-leveldb'),
db_type='leveldb')
softmax = AddLeNetModel(train_model, data)
AddTrainingOperators(train_model, softmax, label)
AddBookkeepingOperators(train_model)
# Testing model. We will set the batch size to 100, so that the testing
# pass is 100 iterations (10,000 images in total).
# For the testing model, we need the data input part, the main LeNetModel
# part, and an accuracy part. Note that init_params is set False because
# we will be using the parameters obtained from the train model.
test_model = model_helper.ModelHelper(
name="mnist_test", arg_scope=arg_scope, init_params=False)
data, label = AddInput(
test_model, batch_size=100,
db=os.path.join(data_folder, 'mnist-test-nchw-leveldb'),
db_type='leveldb')
softmax = AddLeNetModel(test_model, data)
AddAccuracy(test_model, softmax, label)
# Deployment model. We simply need the main LeNetModel part.
deploy_model = model_helper.ModelHelper(
name="mnist_deploy", arg_scope=arg_scope, init_params=False)
AddLeNetModel(deploy_model, "data")
# You may wonder what happens with the param_init_net part of the deploy_model.
# No, we will not use them, since during deployment time we will not randomly
# initialize the parameters, but load the parameters from the db.
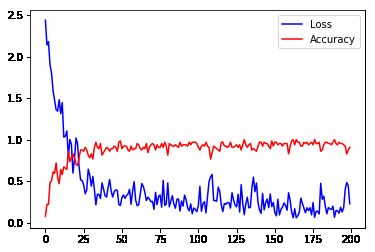
运行网络,打印loss曲线:
# The parameter initialization network only needs to be run once.
workspace.RunNetOnce(train_model.param_init_net)
# creating the network
workspace.CreateNet(train_model.net)
# set the number of iterations and track the accuracy & loss
total_iters = 200
accuracy = np.zeros(total_iters)
loss = np.zeros(total_iters)
# Now, we will manually run the network for 200 iterations.
for i in range(total_iters):
workspace.RunNet(train_model.net.Proto().name)
accuracy[i] = workspace.FetchBlob('accuracy')
loss[i] = workspace.FetchBlob('loss')
# After the execution is done, let's plot the values.
pyplot.plot(loss, 'b')
pyplot.plot(accuracy, 'r')
pyplot.legend(('Loss', 'Accuracy'), loc='upper right')
我们也可以输出来预测:
# Let's look at some of the data.
pyplot.figure()
data = workspace.FetchBlob('data')
_ = visualize.NCHW.ShowMultiple(data)
pyplot.figure()
softmax = workspace.FetchBlob('softmax')
_ = pyplot.plot(softmax[0], 'ro')
pyplot.title('Prediction for the first image')


记得我们也定义了一个test_model,我们可以运行它得到测试集准确率,虽然test_model的权值由train_model来加载,但是测试数据输入还需要运行param_init_net。
# run a test pass on the test net
workspace.RunNetOnce(test_model.param_init_net)
workspace.CreateNet(test_model.net)
test_accuracy = np.zeros(100)
for i in range(100):
workspace.RunNet(test_model.net.Proto().name)
test_accuracy[i] = workspace.FetchBlob('accuracy')
# After the execution is done, let's plot the values.
pyplot.plot(test_accuracy, 'r')
pyplot.title('Acuracy over test batches.')
print('test_accuracy: %f' % test_accuracy.mean())
test_accuracy: 0.946700
这样,我们就简单的完成了模型的搭建、训练、部署
转载自
作者:陆姚知马力
连接:
https://www.jianshu.com/p/5c0fd1c9fef9