决策树学习的目标:根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
决策树学习的本质:从训练集中归纳出一组分类规则,或者说是由训练数据集估计条件概率模型。
决策树学习的损失函数:正则化的极大似然函数
决策树学习的测试:最小化损失函数
决策树学习的目标:在损失函数的意义下,选择最优决策树的问题。
决策树原理和问答猜测结果游戏相似,根据一系列数据,然后给出游戏的答案。
决策树算法3要素:
特征选择,决策树生成,决策树剪枝
部分理解:
关于决策树生成
决策树的生成过程就是 使用满足划分准则的特征不断的将数据集划分为纯度更高,不确定性更小的子集的过程。
对于当前数据集D的每一次的划分,都希望根据某特征划分之后的各个子集的纯度更高,不确定性更小。
而如何度量划分数据集前后的数据集的纯度以及不确定性呢?
答案:特征选择准则,比如:信息增益,信息增益率,基尼指数

信息增益:信息增益是相对于特征而言的。所以,特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:
g(D,A)=H(D)−H(D|A)g(D,A)=H(D)−H(D|A)
一般地,熵H(D)与条件熵H(D|A)之差成为互信息(mutual information)。

CART算法
先分割区域,建议每层都用二分割,然后求cost function。另每块的损失函数都最小,则为最佳分类。
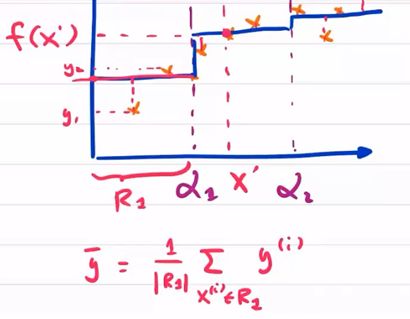
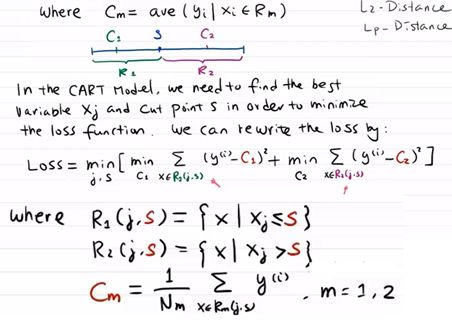
S是切割点。Cm是y的均值
参考
https://blog.csdn.net/jiaoyangwm/article/details/79525237#311-信息增益
https://www.cnblogs.com/muzixi/p/6566803.html
https://www.cnblogs.com/yonghao/p/5061873.html
https://blog.csdn.net/qq_39521554/article/details/80559531
https://www.cnblogs.com/yinheyi/p/6843009.html