结构化数组是ndarray,它的数据类型是由一些简单的数据类型组成的结构,这些数据类型按命名字段的序列组织。例如:

这里x是一个长度为2的一维数组,其数据类型为具有三个字段结构:
1.长度为10或更短的字符串,名称为“name”
2.一个32位整数“age”和3
3.一个32位浮点数,名称为“weight”
如果x在位置1索引,可以得到一个结构:
可以通过使用字段名称建立索引来访问和修改结构化数组和各个字段:

结构化数据类型被设计成能够模仿C语言中的结构,并共享类似的内存布局。它们用于与C代码进行接口,以及对结构化缓冲区进行低级操作,例如解释二进制blob。为此,它们支持特殊功能,如子数组、嵌套数据类型和联合,并允许控制结构的内存布局。
结构化数据类型
可以将结构化数据类型视为具有一定长度的字节序列(结构的itemssize),它被解释为字段的集合。每个字段在结构中都有一个名称、数据类型、字节偏移量。字段的数据类型可以是任何numpy数据类型,包括其它结构化数据类型,也可以是数组的子数据类型,其行为类似于指定形状的ndarray。字段的偏移是任意的,并且字段甚至可能重叠,这些偏移量通常由numpy自动确定,但也可以指定。
结构化数据类型创建
可以使用numpy.dtype函数创建结构化数据类型,规范有4种形式,它们在灵活性和简洁性上各不相同。
1.元组列表,每个字段一个元组
每个元组都有其形式(字段名、数据类型、形状),其中形状是可选的。fieldname是一个字符串,datatype可以是任何可转换为数据类型的对象,shape是指定子数组形状的整数元组。
如果fieldname为空字符串‘’,则将为该字段提供默认的形式名称f#,其中#是该字段的整数索引,从左侧的0开始计数:

结构内字段的字节偏移量和整个结构项的itemsize会自动确定。
2.一串用逗号分隔的dtype规范
在这种简写形式中,可以在字符串中使用任何字符串dtype规范,并用逗号分隔,字段的itemsize和字节偏移量自动确定和字段名默认名称为f0、f1等等。

3.字段参数数组字典
这是规范的最灵活形式,因为它允许控制字段的字节偏移量和结构的项目大小。
该词典有两个必需的键:“名称”和“格式”,以及四个可选键,“偏移”、“itemsize”、“aligned”和“titles”。“名称”和“格式”的值分别是字段名称的列表和dtype规范的列表,且长度相同。可选的“偏移量”值应该是整数字节偏移量的列表,每个字节偏移量对应于结构中的每个字段。如果未给出“偏移”,则自动确定偏移,可选的“itemsize”值应为整数,以dtype的字节数表示总大小,该大小必须足够大以包含所有字段。

可以选择偏移量以使字段重叠,虽然这意味着分配给一个字段可能会破会任何重叠字段的数据,但是作为例外,numpy.object_类型的字段不能与其它字段重叠,因为存在破坏内部对象指针然后对其取消引用的风险。
可以将可选的“aligned“值设置为True使自动偏移量计算使用对齐的偏移量,就像“align“关键字参数numpy.dtype已设置为True一样。
可选的“titles“值应该是与”names“长度相同的标题列表。
4.字段名的字典
这种形式的规范,不建议使用,这里说明,是因为较早的numpy代码可能会使用它。字典的键是字段名称,值是指定类型和偏移量的元组:

不建议使用此格式,因为Python字典不会在Python3.6之前的Python版本中保留顺序,并且结构化dtype中字段的顺序具有含义,字段标题可以使用三元组指定。
操作和显示结构化数据类型
结构化数据类型的字段名称列表可以在dtype对象的names属性中找到。

dtype对象还有一个类似于字典的属性fields,它的键是字段名和字段标题,其值是包含每个字段的dtype和字节偏移量的元组。
对于非结构化数组,名称和字段属性都等于None。测试一个dtype是否结构化的推荐方法是使用if dt.names不为None而不是if dt.names,来解决具有0字段的dtype。
如果可以的话,以“元组列表“形式显示结构化数据类型的字符串表示形式,否则numpy将退回到使用更通用的字典形式。
自动字节偏移和对齐
NumPy使用两种方法之一来自动确定字段字节偏移量和结构化数据类型的整体项目大小,具体取决于是否将align=True指定为numpy.dtype的关键字参数。
默认情况下(align=False),numpy会将字段打包在一起,以使每个字段都从上一个字段结束处的字节偏移处开始,并且这些字段在内存中是连续的。
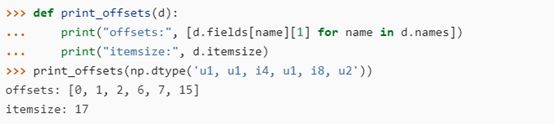
如果设置为align=True,numpy将以许多C编译器填充C结构一样的方式填充该结构。在某些情况下,对齐的结构可以提高性能,但要增加数据类型的大小。填充字节插入字段之间,这样每个字段的字节偏移量将是该字段对齐方式的倍数,对于简单数据类型,该字节偏移量通常等于该字段的大小(以字节为单位)。该结构还将添加尾随填充,以便使其大小是最大字段对齐方式的倍数。

尽管默认情况下几乎所有现代C编译器都以这种方式进行填充,但是C结构中的填充是C实现相关的,因此不能保证此内存布局与C程序中相应结构的布局完全匹配。
如果在基于字典的dtype规范中使用可选的offsets键指定偏移量,设置align=True将检查每个字段的偏移量是其大小的倍数,并且itemsize是最大字段大小的倍数,如果不是,则会引发异常。
结构化数组的字段偏移量和项目大小满足对齐条件时,该数组将设置ALIGNED标志。
便利函数numpy.lib.recfunctions.repack_fields将对齐的dtype或数组转换为压缩的dtype或数组,反之亦然,它使用dtype或结构化ndarray作为参数,并返回带有重新打包的字段(带或不带填充字节)的副本。
字段标题
除了字段名称之外,字段还可以具有关联的标题(备用名称),该名称有时用作字段的附加描述或别名。标题可以像字段名一样用于索引数组。
要在使用dtype规范的元组列表形式时添加标题,可以将字段名指定为两个字符串的元组,而不是单个字符串,分别是字段的标题和字段名。例如:
当使用基于字典的规范的第一形式时,如上所述,标题可以作为额外的“titles“键提供。当使用第二个(不建议使用)基于字典的规范时,可以通过提供一个3元素的元组(datatype、offset、title)来提供标题,而不是通常的2元素元组。
该dtype.fields字典将包含标题作为关键字,如果使用任何标题,这实际上意味这具有标题的字段将在字段字典中表示两次。这些字段的元组值还将具有第三个元素,即字段标题。因此,由于该names属性保留字段顺序,而该fields 属性可能不保留,因此建议使用dtypenames属性(不列出标题)遍历dtype的字段,如下所示:

如果你想学习Python,但是找不到学习路径和资源,欢迎上指尖编程。