[TOC]
参考
1. TCP可靠性的保证机制总结
2. 网络基础:TCP协议-如何保证传输可靠性
3. TCP协议的流量控制和拥塞控制
4. TCP 的那些事儿(下)
5. TCP拥塞控制:慢开始、拥塞避免、快重传、快恢复
1. 校验和
TCP检验和的计算与UDP一样,在计算时要加上12byte的伪首部,检验范围包括TCP首部及数据部分,但是UDP的检验和字段为可选的,而TCP中是必须有的。计算方法为:在发送方将整个报文段分为多个16位的段,然后将所有段进行反码相加,将结果存放在检验和字段中,接收方用相同的方法进行计算,如最终结果为检验字段所有位是全1则正确(UDP中也是全为1则正确),否则存在错误。
2. 确认应答与序列号
TCP将每个字节的数据都进行了编号,这就是序列号。
序列号的作用:
a、保证可靠性(当接收到的数据总少了某个序号的数据时,能马上知道)
b、保证数据的按序到达
c、提高效率,可实现多次发送,一次确认
d、去除重复数据
数据传输过程中的确认应答处理、重发控制以及重复控制等功能都可以通过序列号来实现
TCP通过确认应答机制实现可靠的数据传输。在TCP的首部中有一个标志位——ACK,此标志位表示确认号是否有效。接收方对于按序到达的数据会进行确认,当标志位ACK=1时确认首部的确认字段有效。进行确认时,确认字段值表示这个值之前的数据都已经按序到达了。而发送方如果收到了已发送的数据的确认报文,则继续传输下一部分数据;而如果等待了一定时间还没有收到确认报文就会启动重传机制。
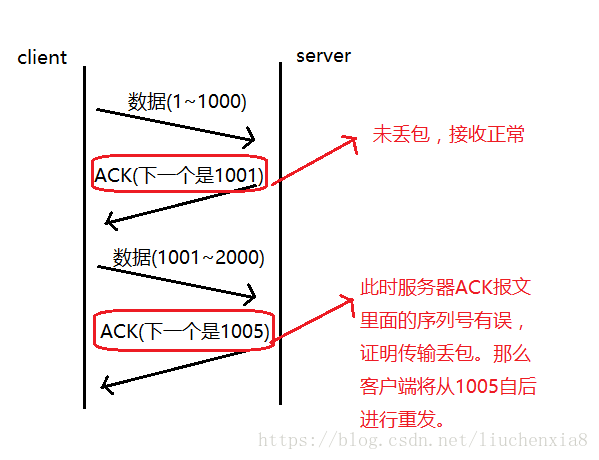
3. 超时重传
当报文发出后在一定的时间内未收到接收方的确认,发送方就会进行重传(通常是在发出报文段后设定一个闹钟,到点了还没有收到应答则进行重传)。
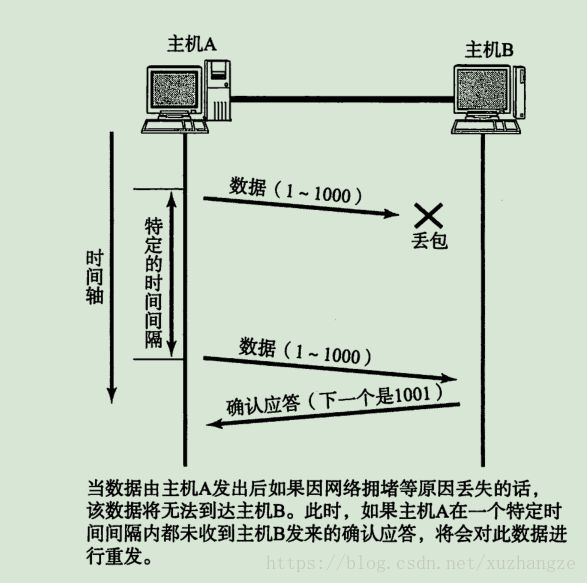
一种情况是发送包丢失了,其基本过程如下:
另一种情况是ACK 丢失,过程如下:
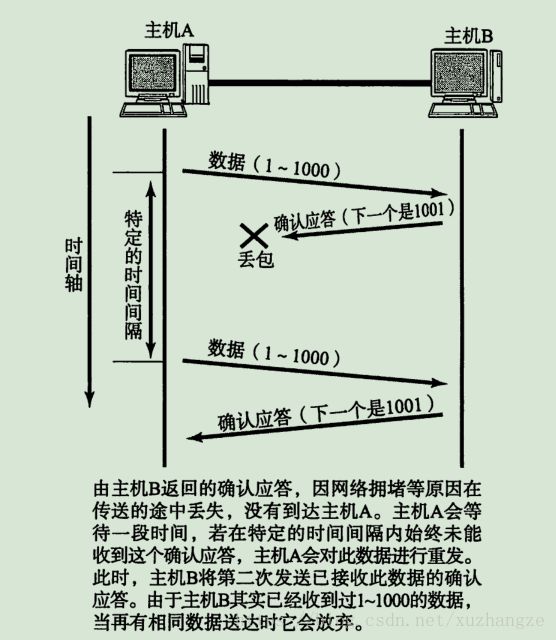
当接收方接收到重复的数据时就将其丢掉,重新发送ACK。而要识别出重复的数据,前面提到的序列号就起作用了。
重传时间的确定:
重传时间的确定:报文段发出到收到应答中间有一个报文段的往返时间RTT,显然超时重传时间RTO会略大于这个RTT,TCP会根据网络情况动态的计算RTT,即RTO是不断变化的。在Linux中,超时以500ms为单位进行控制,每次判定超时重发的超时时间都是500ms的整数倍。其规律为:如果重发一次仍得不到应答,就等待2500ms后再进行重传,如果仍然得不到应答就等待4500ms后重传,依次类推,以指数形式递增,重传次数累计到一定次数后,TCP认为网络或对端主机出现异常,就会强行关闭连接。
4. 连接管理
连接管理机制即TCP建立连接时的三次握手和断开连接时的四次挥手。
5. 流量控制
接收端处理数据的速度是有限的,如果发送方发送数据的速度过快,导致接收端的缓冲区满,而发送方继续发送,就会造成丢包,继而引起丢包重传等一系列连锁反应。
因此TCP支持根据接收端的处理能力,来决定发送端的发送速度,这个机制叫做流量控制。
在TCP报文段首部中有一个16位窗口长度,当接收端接收到发送方的数据后,在应答报文ACK中就将自身缓冲区的剩余大小,放入16窗口大小中。这个大小随数据传输情况而变,窗口越大,网络吞吐量越高,而一旦接收方发现自身的缓冲区快满了,就将窗口设置为更小的值通知发送方。如果缓冲区满,就将窗口置为0,发送方收到后就不再发送数据,但是需要定期发送一个窗口探测数据段,使接收端把窗口大小告诉发送端。

注意:窗口大小不受16位窗口大小限制,在TCP首部40字节选项中还包含一个窗口扩大因子M,实际窗口大小是窗口字段的值左移M位。
6. 拥塞控制
流量控制解决了两台主机之间因传送速率而可能引起的丢包问题,在一方面保证了TCP数据传送的可靠性。然而如果网络非常拥堵,此时再发送数据就会加重网络负担,那么发送的数据段很可能超过了最大生存时间也没有到达接收方,就会产生丢包问题。
为此TCP引入慢启动机制,先发出少量数据,就像探路一样,先摸清当前的网络拥堵状态后,再决定按照多大的速度传送数据。
此处引入一个拥塞窗口:
发送开始时定义拥塞窗口大小为1;每次收到一个ACK应答,拥塞窗口加1;而在每次发送数据时,发送窗口取拥塞窗口与接送段接收窗口最小者。
慢启动:在启动初期以指数增长方式增长;设置一个慢启动的阈值,当以指数增长达到阈值时就停止指数增长,按照线性增长方式增加;线性增长达到网络拥塞时立即“乘法减小”,拥塞窗口置回1,进行新一轮的“慢启动”,同时新一轮的阈值变为原来的一半。
“慢启动”机制可用图表示:
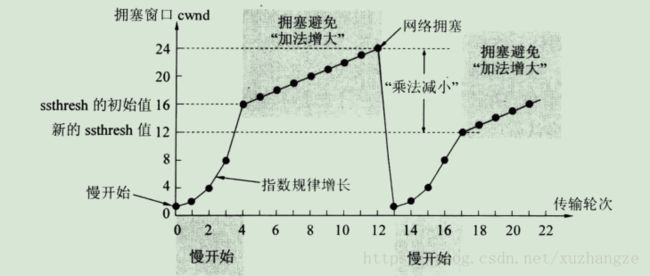
关于拥塞控制的算法细节,可以参考 4. TCP 的那些事儿(下)
6.1. 慢启动
1)连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
2)每当收到一个ACK,cwnd++; 呈线性上升
3)每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
4)还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”(后面会说这个算法)
6.2. 拥塞避免
1)收到一个ACK时,cwnd = cwnd + 1/cwnd
2)当每过一个RTT时,cwnd = cwnd + 1
这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。很明显,是一个线性上升的算法。
6.3. 快重传
当出现ack超时的时候,需要重传数据包。
- sshthresh = cwnd /2
- cwnd 重置为 1
- 进入慢启动过程
TCP认为这种情况太糟糕,反应也很强烈。
快速重传在收到3个duplicate ACK时就开启重传(三次 ack 就认为丢包的原理见关于TCP乱序和重传的问题、TCP 快速重传为什么是三次冗余 ACK),而不用等到RTO超时。
TCP Reno的实现是:
- cwnd = cwnd /2
- sshthresh = cwnd
- 进入快速恢复算法——Fast Recovery
6.4. 快恢复

快速重传和快速恢复算法一般同时使用。快速恢复算法是认为,你还有3个Duplicated Acks说明网络也不那么糟糕,所以没有必要像RTO超时那么强烈。 注意,正如前面所说,进入Fast Recovery之前,cwnd 和 sshthresh已被更新:
cwnd = cwnd /2
sshthresh = cwnd
然后,真正的Fast Recovery算法如下:
cwnd = sshthresh + 3 * MSS (3的意思是确认有3个数据包被收到了)
重传Duplicated ACKs指定的数据包
如果再收到 duplicated Acks,那么cwnd = cwnd +1
如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法了。
如果你仔细思考一下上面的这个算法,你就会知道,上面这个算法也有问题,那就是——它依赖于3个重复的Acks。注意,3个重复的Acks并不代表只丢了一个数据包,很有可能是丢了好多包。但这个算法只会重传一个,而剩下的那些包只能等到RTO超时,于是,进入了恶梦模式——超时一个窗口就减半一下,多个超时会超成TCP的传输速度呈级数下降,而且也不会触发Fast Recovery算法了。
通常来说,正如我们前面所说的,SACK或D-SACK的方法可以让Fast Recovery或Sender在做决定时更聪明一些,但是并不是所有的TCP的实现都支持SACK(SACK需要两端都支持),所以,需要一个没有SACK的解决方案。而通过SACK进行拥塞控制的算法是FACK(可参见关于TCP乱序和重传的问题)