最近参考一些技术文章同时结合自己的思考用Python写了个可以批量保存微信文章的小工具。实现的功能是通过微信文章的链接将文章保存为图片、HTML以及PDF,使用方法很简单,不懂技术也能用。
写这个小工具源于我的一个习惯,在看到喜欢或者有启发的微信文章时,除了在微信收藏,我还会把它们保存下来。
一般手动操作的步骤,首先是把某篇公众号文章的链接放到谷歌浏览器的地址栏来打开文章,然后使用谷歌浏览器的打印功能将文章保存为PDF,按F12调出调试窗口后再按ctrl+shift+p调出命令输入框接着输入Capture full size screenshot按回车后保存为图片。
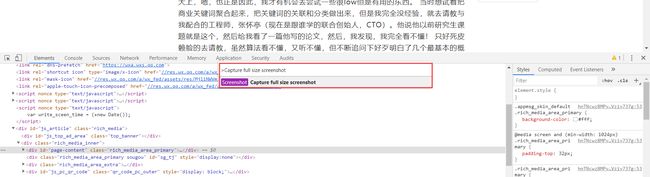
一篇两篇文章这样操作还没什么,一旦想要保存的文章多了我就得一遍又一遍地重复上面的操作,这无疑是非常繁琐的。为了提高效率,我把这些步骤写成脚本,用Python来自动帮我完成,于是就有了这个工具。
只需要将公众号文章的链接放入到某个特定的txt文件,然后运行工具就可以批量地将微信文章保存为图片、HTML以及PDF。比之前的手动步骤方便多了。
下面的内容主要分为两部分,第一部分「使用指南」是讲如何使用这个工具的,第二部分「开发者指南」是讲这个工具的开发思路和代码逻辑,如果对代码不感兴趣直接略过第二部分就好。工具的使用和开发都是基于Win10系统的。
使用指南
1.获取相关文件
关注公众号「双城笔录」后发送文字「Python」获取网盘链接及提取码,通过链接下载相关压缩包
2.解压文件
将压缩包解压获得saveArticle文件夹,将该文件夹放到没有中文的路径下,里面的文件如下:

如果压缩包中的谷歌浏览器、Chromedriver和wkhtmltopdf与你的系统不兼容,可以到下面的网址去下载适合的版本,将下载的包放在与exe文件相同的文件夹。其中谷歌浏览器、Chromedriver的版本要一致。
- 谷歌浏览器下载地址:
https://google.cn/intl/zh-CN/chrome/ - Chromedriver下载地址:
http://chromedriver.storage.googleapis.com/index.html - wkhtmltopdf下载地址:
https://wkhtmltopdf.org/downloads.html
3.安装谷歌浏览器和wkhtmltopdf
-
点击ChromeStandaloneSetup64.exe,在弹出的窗口点击“是”,等待安装完成即可。
 安装谷歌浏览器
安装谷歌浏览器 -
点击wkhtmltox-0.12.5-1.msvc2015-win64.exe,在弹出的窗口点击“是”,进入到下一步后点击“I Agree”,然后点击install将其安装在默认文件夹C:\Program Files\wkhtmltopdf,等待安装完成即可。
 安装wkhtmltopdf
安装wkhtmltopdf
4.填入公众号文章链接
在urls4.txt填写你需要保存的公众号文章的链接,注意一行只能写一条链接,注意不要有空格及其他特殊字符(urls4.txt中默认链接有两条微信文章的链接,第一次使用时可以先试下效果)

5.运行工具
按照实际需要点击exe文件,其中三个exe的功能略有差别,请酌情选择,差别如下:
- saveAricleToPIC.exe仅对文章进行截图
- saveArticleToPIC_HTML.exe 对文章截图并保存为HTML(因为保存为PDF耗时会比较长,所以通常我会选择这种,既可以保留文章的格式又可以节约时间)
- saveArticleToPIC_HTML_PDF.exe 对公众号文章截图、保存为HTML以及PDF
注意要在saveArticle文件夹中运行exe文件。
6.完成标志
命令提示符框显示"本次保存所有文章的总耗时为xx秒字样"时,表示已经完成本次操作

开发指南
1.开发环境部署
使用的编程语言版本、浏览器版本、Chromedriver版本以及wkhtmltopdf版本
- Python 3.6.8
- 谷歌浏览器 79.0.3945.88版
- Chromedriver 79.0.3945.88版
- wkhtmltopdf wkhtmltox-0.12.5-1.msvc2015-win64
安装Python的教程网上有很多这里就不赘述了,Chromedriver不需要安装,谷歌浏览器和wkhtmltopdf的安装包及安装步骤在上面「使用指南」已经提及。
2.使用到的Python模块
selenium,os,requests,time,pdfkit,re,BeautifulSoup,html5lib,pyinstaller.
其中os,time及re为Python标准库无需另外安装,selenium,requests,pdfkit,BeautifulSoup,html5lib以及pyinstaller可以用pip命令安装。
比如安装pyinstaller,在cmd窗口输入pip install pyinstaller然后点击回车等待安装完成即可。

下面讲讲开发的思路和比较关键的代码。
3. 思路
使用Chromedriver和selenium模拟浏览器来访问微信文章并进行全屏截图。
使用BeautifulSoup,用它的find方法和tag属性修改删除来解决微信文章图片懒加载(即当查看到文章某部分时图片才加载)的问题,用find方法提取文章的作者和标题,同时将BeautifulSoup提取的HTML保存为HTML文件。
使用pdfkit调用wkhtmltopdf将保存的HTML转换为PDF文件。
4.关键代码
1)引入selenium和chromedriver,先设置好相关配置,将chrome设置为无界面模式同时屏蔽掉chromedriver运行日志。在开发过程中如果不屏蔽掉运行日志,那么将会有很多冗余的信息干扰你的视线。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
os.environ['webdriver.chrome.driver'] = chromedriver
# 设置chrome开启的模式,headless就是无界面模式,只有开启这个模式才能截取全屏
chrome_options = Options()
chrome_options.add_argument('headless')
# 屏蔽chromedriver运行日志
chrome_options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver = webdriver.Chrome(chromedriver, chrome_options=chrome_options)
2)因为微信文章使用的是懒加载图片的方式,所以如果直接使用save_screenshot方法只能截取到文字内容而无法截取文章里的图片,所以要用selenium的webdirver来执行JS脚本,模拟拖动滚动条到页面的最底部。
all_window_height = []
# 当前页面的最大高度加入列表
all_window_height.append(driver.execute_script('return document.body.scrollHeight;'))
while True:
# 执行拖动滚动条操作
driver.execute_script('scroll(0,100000)')
time.sleep(3)
check_height = driver.execute_script('return document.body.scrollHeight;')
# 判断拖动滚动条后的最大高度与上一次的最大高度的大小,相等表明到了最底部
if check_height == all_window_height[-1]:
break
else:
# 如果不相等,将当前页面最大高度加入列
all_window_height.append(check_height)
本段代码参考自
https://blog.csdn.net/weixin_40718824/article/details/84196233
3)用selenium的webdirver来执行JS脚本,从而获得整个网页的高度和宽度,然后使用save_screenshot对整篇文章进行截图
width = driver.execute_script('return document.documentElement.scrollWidth')
height = driver.execute_script('return document.documentElement.scrollHeight')
# 将浏览器的宽高设置成刚刚获取的宽高
driver.set_window_size(width, height)
driver.save_screenshot(pic_path)
4)和上面截图时遇到的图片懒加载一样,如果用BeautifulSoup直接将微信文章保存为HTML的话,保存的文件中是看不到图片的,只能看到一个个loading。请教前端同事后,发现只要先将微信文章HTML中的属性data-src改为src,然后再保存为HTML文件就不会有这个问题了
soup = BeautifulSoup(response.content, 'html5lib')
# 将拥有'data-src'属性的图片标签的'data-src'改为'src',解决JS懒加载的问题
for img in soup.find_all('img', {'data-src': True}):
img['src'] = img['data-src']
del img['data-src']
5)通过pdfkit调用wkhtmltopdf模块
pdfkit.from_file(html_path, pdf_path, options=options, configuration=config)
6)完成代码开发后,使用pyinstaller -F saveArticleToPIC_HTML_PDF.py将代码和使用到的Python模块打包成exe,这样在没有Python环境的电脑也可以使用这个工具了。
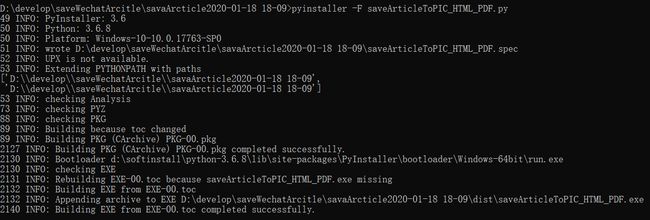
完整代码在上面的「使用指南」提及的下载包里面有,另外点击https://github.com/bchainn/tool/blob/master/saveArticleToPIC_HTML_PDF.py也可以跳转到源码页。
参考资料
- Python 爬虫:把廖雪峰的教程转换成 PDF 电子书
- Beautiful Soup 4.4.0 文档
- 函数解决页面懒加载问题
题图:Photo by Python官网和微信官网
Note:
1.因为水平有限,写的这个小工具也只是能用而已,如果读者朋友们发现功能或者代码有不合理的地方,欢迎后台留言指正交流,不胜感激。
2.一些网页也可以用这个工具来保存,使用方法也是一样的,读者们可以试一试。
3.点击https://github.com/bchainn/tool/blob/master/saveArticleToPIC_HTML_PDF.py可以跳转到源码页
本文原文链接为 一个保存微信文章的小工具