公司:英语在线培训机构
面试知识点:
1 并发
java线程池常用6大参数以及含义
1 corePoolSize:核心线程数
核心线程会一直存活,及时没有任务需要执行
当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理
设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭
2 queueCapacity:任务队列容量(阻塞队列)用来做缓冲
核心线程数达到最大时,新任务会放在队列中排队等待执行
3 maxPoolSize:最大线程数
当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务
当线程数=maxPoolSize,且任务队列已满时,线程池会拒绝处理任务而抛出异常
4 keepAliveTime:线程空闲时间
当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize
如果allowCoreThreadTimeout=true,则会直到线程数量=0 (也就是核心线程长时间没有活干也会退出)
5 allowCoreThreadTimeout:允许核心线程超时
6 rejectedExecutionHandler:任务拒绝处理器
两种情况会拒绝处理任务:
当线程数已经达到maxPoolSize,切队列已满,会拒绝新任务
当线程池被调用shutdown()后,会等待线程池里的任务执行完毕,再shutdown。如果在调用shutdown()和线 程池真正shutdown之间提交任务,会拒绝新任务
线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置默认是AbortPolicy,会抛出异常
## 任务拒绝处理器处理情形
ThreadPoolExecutor类有几个内部实现类来处理这类情况:
AbortPolicy 丢弃任务,抛运行时异常
CallerRunsPolicy 执行任务
DiscardPolicy 忽视,什么都不会发生
DiscardOldestPolicy 从队列中踢出最先进入队列(最后一个执行)的任务
当然也支持自定义处理器
reentrantlock 用法及实现原理
代码示例:
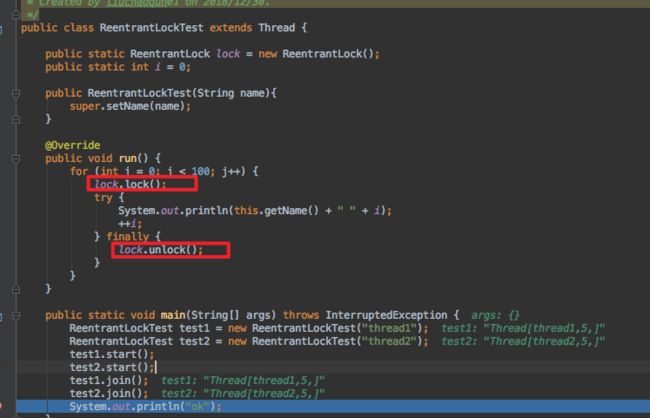
从代码中很容易看出,reentrantlock 相比于sychronized需要在finally中释放锁。如果不在 finally解锁,有可能代码出现异常锁没被释放。
说明: 在jdk1.5里面,ReentrantLock的性能是明显优于synchronized的,但是在jdk1.6里面,synchronized做了优化,他们之间的性能差别已经不明显了
reentrantlock 特点
 image.png
image.png
可中断(这里本身是有死锁的,但是可以通过中断来处理)
package com.protobuf.MultiThreading;
import java.lang.management.ManagementFactory;
import java.lang.management.ThreadInfo;
import java.lang.management.ThreadMXBean;
import java.util.concurrent.locks.ReentrantLock;
public class LockInterrupt extends Thread {
public static ReentrantLock lock1 = new ReentrantLock();
public static ReentrantLock lock2 = new ReentrantLock();
int lock;
public LockInterrupt(int lock, String name) {
super(name);
this.lock = lock;
}
@Override
public void run() {
try {
if (lock == 1) {
lock1.lockInterruptibly();
try {
Thread.sleep(500);
} catch (Exception e) {
// TODO: handle exception
}
lock2.lockInterruptibly();
} else {
lock2.lockInterruptibly();
try {
Thread.sleep(500);
} catch (Exception e) {
// TODO: handle exception
}
lock1.lockInterruptibly();
}
} catch (Exception e) {
// TODO: handle exception
} finally {
if (lock1.isHeldByCurrentThread()) {
lock1.unlock();
}
if (lock2.isHeldByCurrentThread()) {
lock2.unlock();
}
System.out.println(Thread.currentThread().getId() + ":线程退出");
}
}
public static void main(String[] args) throws InterruptedException {
LockInterrupt t1 = new LockInterrupt(1, "LockInterrupt1");
LockInterrupt t2 = new LockInterrupt(2, "LockInterrupt2");
t1.start();
t2.start();
Thread.sleep(1000);
// DeadlockChecker.check();
System.out.println("ok");
}
static class DeadlockChecker {
private final static ThreadMXBean mbean = ManagementFactory
.getThreadMXBean();
public static void check() {
Thread tt = new Thread(() -> {
{
// TODO Auto-generated method stub
while (true) {
long[] deadlockedThreadIds = mbean.findDeadlockedThreads();
if (deadlockedThreadIds != null) {
ThreadInfo[] threadInfos = mbean.getThreadInfo(deadlockedThreadIds);
for (Thread t : Thread.getAllStackTraces().keySet()) {
for (int i = 0; i < threadInfos.length; i++) {
if (t.getId() == threadInfos[i].getThreadId()) {
System.out.println(t.getName());
t.interrupt();
}
}
}
}
try {
Thread.sleep(5000);
} catch (Exception e) {
// TODO: handle exception
}
}
}
});
tt.setDaemon(true);
tt.start();
}
}
}
死锁具体情形如下,但是上文的守护线程可以通过中断的方式解决死锁。但是对于sychronized 如果获取不到锁只能阻塞等待,因此没有这个机制

可限时
超时不能获得锁,就返回false,不会永久等待构成死锁
使用lock.tryLock(long timeout, TimeUnit unit)来实现可限时锁,参数为时间和单位。
公平锁
一般意义上的锁是不公平的,不一定先来的线程能先得到锁,后来的线程就后得到锁。不公平的锁可能会产生饥饿现象。
公平锁的意思就是,这个锁能保证线程是先来的先得到锁。虽然公平锁不会产生饥饿现象,但是公平锁的性能会比非公平锁差很多。
## 使用方法
public ReentrantLock(boolean fair)
public static ReentrantLock fairLock = new ReentrantLock(true);
ConcurrentHashmap实现原理以及使用方法(重新写一篇详细介绍)
redis分布式实现原理(重新写一篇详细介绍)
docker知识点(重新写一篇详细介绍)
redis 并发数据结构以及pipline
常用linux命令
java的复制clone() 命令(重新写一篇节详细介绍)
2 接口编程
restful API的好处,如何实现资源间的耦合
## 之前在老部门做过reseful的接口,可惜忘记的差不多了。
REST是什么?(Resource Representational State Transfer: 资源代表状态变化)
Resource:资源,即数据(前面说过网络的核心)
Representational:某种表现形式: 比如用JSON,XML,JPEG等
State Transfer:状态变化。通过HTTP动词实现
简单介绍:
restful API中,url中只使用名词来指定资源, 原则上不使用动词。“资源”是REST架构或者整个网路处理的核心。
## pf:
http://api.qc.com/v1/newsfeed: 获取某人的信息;
http://api.qc.com/v1/friends: 获取某人的好友列表;
http://api.qc.com/v1/profile: 获取某人的详细信息
但是只有资源,没有操作方法,并不知道具体要做些什么?那么这个时候就需要动词来实现
GET 用来获取资源
POST 用来新建资源(也可以用于更新资源 pf:http://api.qc.com/v1/friends
PUT 用来更新资源 (PUT http://api.qc.com/v1/profile: 更新个人资料)
DELETE 用来删除资源。(比如:DELETE http://api.qc.com/v1/friends, 删除某人的好友, 在http parameter指定好友id)
优势: 接口制定简单,通过url就知道要做什么
看Url就知道要什么
看http method就知道干什么
看http status code就知道结果如何
spring mvc 具体实现以及过程,分发器,hander等
参考[6]
3 工具类知识点
kafka具体了解哪些知识点
zookeeper 具体了解哪些知识点
4 提高篇
你认为上一段工作自己做的比较好的地方
经常通过哪些渠道学习,举例自己学习到的知识点
5 mysql:
question: 写出同时用username + age做 联合主键的查询语句 ?
注意此时是将a,b,c三列所有不同的组合全部列出来,而不仅仅只是distinct a
方案一: distinct多列
select distinct a,b,c from tableA;
方案二:group by
select a,b,c from tableA group by a,b,c
mysql的7大事务传播机制
PROPAGATION_REQUIRED 支持当前事务,如果当前没有事务,则新建一个事(spring 默认)
PROPAGATION_SUPPORTS 支持,如果当前没有则以非事务方式执行
PROPAGATION_MANDATORY 支持,如果没有强制抛出异常
PROPAGATION_REQUIRES_NEW 新建,如果存在挂起当前事务
PROPAGATION_NOT_SUPPORTED 以非事务方式运行,如果存在事务则挂起事务
PROPAGATION_NEVER —— 以非事务方式执行,如果当前存在事务,则抛出异常
PROPAGATION_NESTED —— Nested的事务和它的父事务是相依的,它的提交是要等和它的父事务一块提交的。
小结: 其实可以看出事务的是从支持事务和不支持事务的顺序过渡
Spring事务的5种隔离级别
1、ISOLATION_DEFAULT (使用DB默认隔离级别)
这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别。
另外4个与 JDBC 的隔离级别相对应。
2、ISOLATION_READ_UNCOMMITTED(对应mysql:UNCOMMITTED )
这是事务最低的隔离级别,它允许另外一个事务可以看到这个事务未提交的数据。
这种隔离级别会产生脏读,不可重复读和幻读。
3、 ISOLATION_READ_COMMITTED(对应mysql:READ_COMMITTED)
保证一个事务修改的数据提交后才能被另外一个事务读取,其它事务不能读取该事务未提交的数据。
4、ISOLATION_REPEATABLE_READ(对应mysql:REPEATABLE_READ) mysql 默认隔离级别
保证一个事务不能读取另一个事务未提交的数据,避免了“脏读取”和“不可重复读取”的情况,但是带来了更多的性能损失。
这种事务隔离级别可以防止脏读,不可重复读,但是可能出现幻读。
5、ISOLATION_SERIALIZABLE(对应mysql:SERIALIZABLE)
这是最可靠的但是代价花费最高的事务隔离级别,事务被处理为顺序执行。
除了可防止脏读,不可重复读外,还避免了幻读
具体实例详解参考3
6 vim 常用命令,大文件替换文本等
## 对第一行到最后一行的内容进行替换(即全部文本)多种写法
:1,$s/from/to/g
:%s/from/to/g
参考文献:
1 distinct 多列详解
2 Spring 七种事务传播机制和五种事务隔离级别
3 脏读、幻读和不可重复读 + 事务隔离级别
4 Vim文本替换
5 RESTful API
6 SpringMVC执行流程及工作原理
7 reentrantlock可重入锁