Python的3.0版本,常被称为Python 3000,或简称Py3k。相对于Python的早期版本,这是一个较大的升级。为了不带入过多的累赘,Python 3.0在设计的时候没有考虑向下兼容,所以我还是直接学习Py3k吧。
目前是从
-廖大牛
-菜鸟教程
两个地方学习
python对于不同环境安装方法官网都有说明,如果还有不懂的话可以自行google一下。
下面是记录的自己学到的东西,可能不太详细,只是自己的笔记,方便以后如果忘记了之类的翻出来复习下用~~哈哈
一. python基础
>>> print(300)
300
>>> print(100 + 200)
300
单引号跟双引号
>>> print(‘hello’)
hello
>>> print("hello")
hello
input()输入函数
eg:
name = input('please enter your name: ')
print('hello,', name)
转义字符 “\”
eg:
'I\'m \"OK\"!'
输出的结果为:
I'm "OK"!
‘ 以及 “ 都需要被转义才可以正常的输出
list
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
eg:
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates
['Michael', 'Bob', 'Tracy']
list 可以用下标进行索引
eg:
>>> classmates[0]
'Michael'
>>> classmates[1]
'Bob'
>>> classmates[2]
'Tracy'
用“负数” 进行下表索引
eg:
>>> classmates[-1]
'Tracy'
tuple元组
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改
eg:
>>> classmates = ('Michael', 'Bob', 'Tracy')
classmates[0] = Michael
循环
python的循环语法跟c不太相同。python循环是利用for x in ...循环
for x in ...循环就是把每个元素代入变量x,然后执行缩进块的语句。
eg:
sum = 0
for x in [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]:
sum = sum + x
print(sum)
dict
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
eg:
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
>>> d['Michael']
95
要避免key不存在的错误,有两种办法,一是通过in判断key是否存在:
>>> 'Thomas' in d
False
通过dict提供的get()方法,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1
要删除一个key,用pop(key)方法,对应的value也会从dict中删除:
>>> d.pop('Bob')
75
>>> d
{'Michael': 95, 'Tracy': 85}
dict还有个要注意的问题:
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
要创建一个set,需要提供一个list作为输入集合
重复元素在set中自动被过滤:
eg
>>> s = set([1, 1, 2, 2, 3, 3])
>>> s
{1, 2, 3}
通过add(key)方法,remove(key)方法 可以添加 删除 元素到set中,可以重复添加,但不会有效果:
>>> s.add(4)
>>> s
{1, 2, 3, 4}
>>> s.remove(4)
>>> s
{1, 2, 3}
二 . 函数
求绝对值的函数 abs()
eg:
>>> abs(-20)
20
求最大值函数max()
eg:
>>> max(2, 3, 1, -5)
3
强制类型转换
eg :
>>> int('123')
123
>>> int(12.34)
12
>>> float('12.34')
12.34
>>> str(1.23)
'1.23'
>>> str(100)
'100'
>>> bool(1)
True
>>> bool('')
False
定义函数
def fun():
pass #pass可以当作什么也不做的空函数
用power()函数计算x的n次方
eg:
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
函数参数前面加 * 即是可变参数
eg:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
-------------
>>> calc(1, 2)
5
>>> calc()
0
另一种可变参数
eg:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
区分:
*args是可变参数,args接收的是一个tuple;
**kw是关键字参数,kw接收的是一个dict。
以及调用函数时如何传入可变参数和关键字参数的语法:
可变参数既可以直接传入:func(1, 2, 3),又可以先组装list或tuple,再通过*args传入:func(*(1, 2, 3));
关键字参数既可以直接传入:func(a=1, b=2),又可以先组装dict,再通过**kw传入:func(**{'a': 1, 'b': 2})。
使用*args和**kw是Python的习惯写法,当然也可以用其他参数名,但最好使用习惯用法。
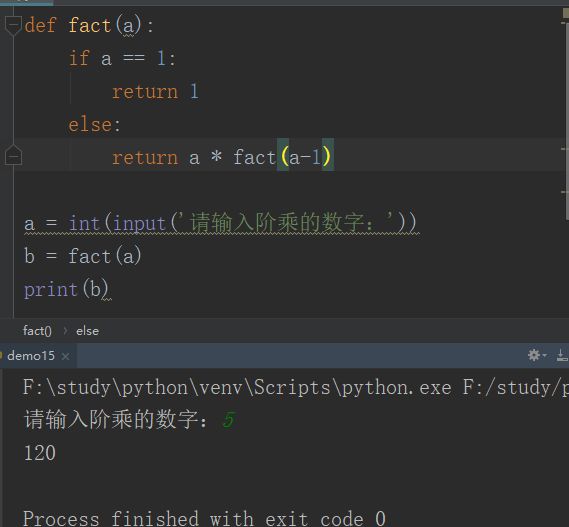
递归函数
最经典的例子,计算阶乘n! = 1 x 2 x 3 x ... x n
eg:
def fact(n):
if n==1:
return 1
return n * fact(n - 1)
切片
在一个list或tuple中取部分元素
eg:
>>> L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
>>> L[0:3] #取1-3个
['Michael', 'Sarah', 'Tracy']
>>> L[-2:] #取后两个
['Bob', 'Jack']
>>> L[:10:2] #前10个数每2个取一个
[0, 2, 4, 6, 8]
列表生成式
举个例子
eg:
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
二重循环
eg:
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
dict的items()可以同时迭代key和value
eg:
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> for k, v in d.items():
... print(k, '=', v)
...
y = B
x = A
z = C
生成器
把一个列表生成式的[]改成(),就创建了一个generator
eg : generator与list的区别
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
at 0x1022ef630>
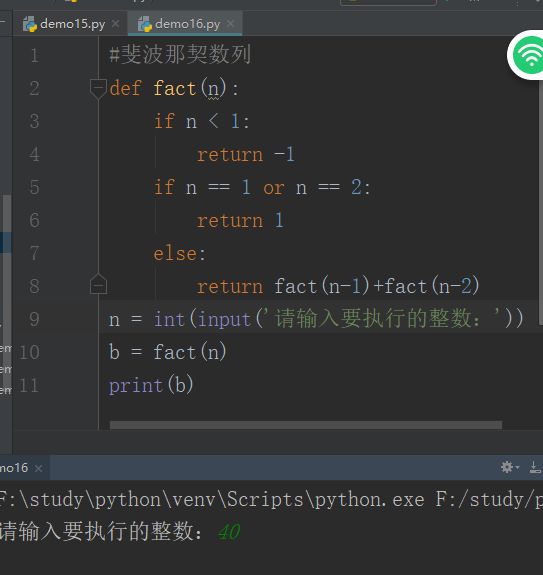
斐波那契数列
eg:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
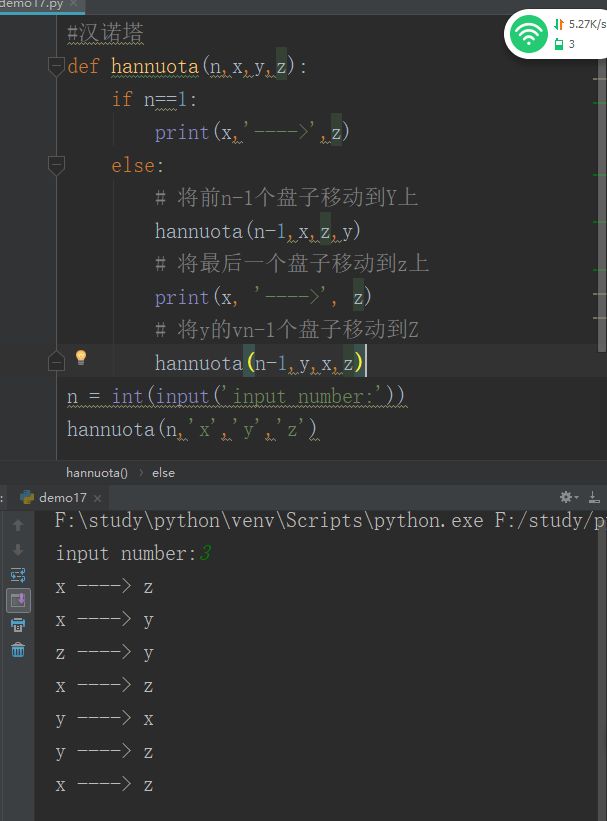
汉诺塔算法
刚看可能有点meng b,慢慢来,我这个弱智表示看了好久的!
高阶函数
1. map()函数
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
eg:
>>> def f(x):
... return x * x
...
>>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> list(r)
[1, 4, 9, 16, 25, 36, 49, 64, 81]
2. duce()函数
reduce把结果继续和序列的下一个元素做累积计算
eg:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
3. filter()函数
filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素
eg:
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
结果: [1, 5, 9, 15]
4. sorted()函数
eg:
>>> sorted([36, 5, -12, 9, -21])
[-21, -12, 5, 9, 36]
Python内置的sorted()函数就可以对list进行排序:
此外,sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序:
eg:
>>> sorted([36, 5, -12, 9, -21], key=abs)
[5, 9, -12, -21, 36]
给sorted传入key函数,即可实现忽略大小写的排序:
eg:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower)
['about', 'bob', 'Credit', 'Zoo']
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True
eg:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
['Zoo', 'Credit', 'bob', 'about']
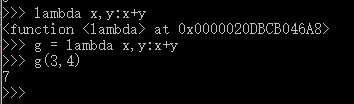
匿名函数
匿名函数 lambda x: x * x
匿名函数也可以作为返回值。
格式: 匿名函数名字:函数的表达式
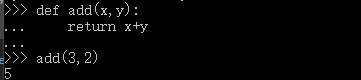
eg:
>>> list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
[1, 4, 9, 16, 25, 36, 49, 64, 81
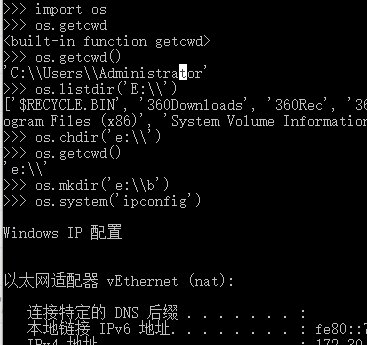
python 的os模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dir1/dir2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","new") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 用于分割文件路径的字符串
os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
就不一一列举了,用的时候进行查询就行
python 的pivkle模块
pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。
pickle模块只能在python中使用,python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化,
pickle序列化后的数据,可读性差,人一般无法识别。
eg:
#coding:utf-8
__author__ = 'MsLili'
#pickle模块主要函数的应用举例
import pickle
dataList = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
dataDic = { 0: [1, 2, 3, 4],
1: ('a', 'b'),
2: {'c':'yes','d':'no'}}
#使用dump()将数据序列化到文件中
fw = open('dataFile.txt','wb')
# Pickle the list using the highest protocol available.
pickle.dump(dataList, fw, -1)
# Pickle dictionary using protocol 0.
pickle.dump(dataDic, fw)
fw.close()
#使用load()将数据从文件中序列化读出
fr = open('dataFile.txt','rb')
data1 = pickle.load(fr)
print(data1)
data2 = pickle.load(fr)
print(data2)
fr.close()
#使用dumps()和loads()举例
p = pickle.dumps(dataList)
print( pickle.loads(p) )
p = pickle.dumps(dataDic)
print( pickle.loads(p) )
python 的异常总结【exception】
Python标准异常总结
AssertionError 断言语句(assert)失败
AttributeError 尝试访问未知的对象属性
EOFError 用户输入文件末尾标志EOF(Ctrl+d)
FloatingPointError 浮点计算错误
GeneratorExit generator.close()方法被调用的时候
ImportError 导入模块失败的时候
IndexError 索引超出序列的范围
KeyError 字典中查找一个不存在的关键字
KeyboardInterrupt 用户输入中断键(Ctrl+c)
MemoryError 内存溢出(可通过删除对象释放内存)
NameError 尝试访问一个不存在的变量
NotImplementedError 尚未实现的方法
OSError 操作系统产生的异常(例如打开一个不存在的文件)
OverflowError 数值运算超出最大限制
ReferenceError 弱引用(weak reference)试图访问一个已经被垃圾回收机制回收了的对象
RuntimeError 一般的运行时错误
StopIteration 迭代器没有更多的值
SyntaxError Python的语法错误
IndentationError 缩进错误
TabError Tab和空格混合使用
SystemError Python编译器系统错误
SystemExit Python编译器进程被关闭
TypeError 不同类型间的无效操作
UnboundLocalError 访问一个未初始化的本地变量(NameError的子类)
UnicodeError Unicode相关的错误(ValueError的子类)
UnicodeEncodeError Unicode编码时的错误(UnicodeError的子类)
UnicodeDecodeError Unicode解码时的错误(UnicodeError的子类)
UnicodeTranslateError Unicode转换时的错误(UnicodeError的子类)
ValueError 传入无效的参数
ZeroDivisionError 除数为零
easygui
建议看下这位博主写的,挺详细的,可以跟着敲一下
https://www.cnblogs.com/bldly1989/p/6651855.html
导入easygui
import easygui as g
g.msgbox('666')
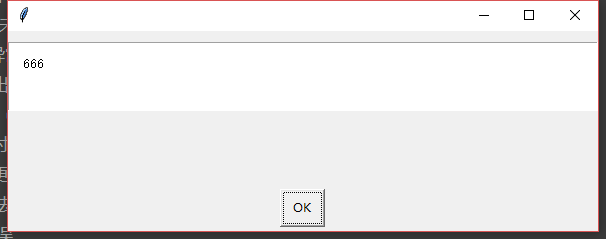 image.png
image.png