1.java常见的名词
| 英文名 | 中文名 | 含义 |
|---|---|---|
| EJB(Enterprise java bean) | Enterprise java bean 容器 | 提供给运行在其中的组件EJB各种管理功能 |
| JNDI(Java Naming & Directory Interface) | JAVA命名目录服务 | 提供一个目录系统,让其它各地的应用程序在其上面留下自己的索引,从而满足快速查找和定位分布式应用程序的功能。 |
| JMS | JAVA消息服务 | 主要实现各个应用程序之间的通讯。包括点对点和广播。 |
| JAF | JAVA安全认证框架 | 提供一些安全控制方面的框架。让开发者通过各种部署和自定义实现自己的个性安全控制策略。 |
| .RMI/IIOP(Remote Method Invocation /internet对象请求中介协议) | 远程调用服务 | 。首先,RMI-IIOP综合了RMI的简单性和CORBA的多语言性(兼容性),其次RMI-IIOP克服了RMI只能用于Java的缺点和CORBA的复杂性(可以不用掌握IDL) |
| JTA:(Java Transaction API) | JAVA事务服务 | 提供各种分布式事务服务。应用程序只需调用其提供的接口即可。 |
2.内部类的相关概念
你就把内部类理解成类的成员,成员有4种访问权限吧,内部类也是!分别为private、protected、public以及默认的访问权限
外部类的上一级程序单元是包,所以其有两个作用域:同一包内和任何位置。因此只需要2种访问权限:包访问权限和公开访问权限,正好对应的省略访问控制符和public。省略访问控制符是包访问权限,即同一个包内的其他类可以访问省略访问控制符的成员。因此,如果一个外部类不使用任何访问控制符修饰,则只能被同一个包的其他类访问。而内部类的上一级程序单元是外部类,它就具有4个作用域:同一个类、同一个包、父子类和任何位置。
我收集的一点关于内部类的资料,与大家共享,有不对的欢迎指正。题目说的应该是3.1,定义在方法外部的内部类:
1. 内部类中不能定义静态成员
2.内部类可以直接访问外部类中的成员变量,
3. 内部类可以定义在外部类的方法外面,也可以定义在外部类的方法体中
3.1. 在方法体外面定义的内部类的访问类型可以是public,protecte,默认的,private等4种类型,创建内部类的实例对象时,一定要先创建外部类的实例对象,然后用这个外部类的实例对象去创建内部类的实例对象
3.2. 方法内部定义的内部类前面不能有访问类型修饰符,就好像方法中定义的局部变量一样,但这种内部类的前面可以使用final或abstract修饰符。这种内部类对其他类是不可见的,其他类无法引用这种内部类,但是这种内部类创建的实例对象可以传递给其他类访问。
4.在方法外部定义的内部类前面可以加上static关键字,从而成为Static Nested Class,它不再具有内部类的特性,所有,从狭义上讲,它不是内部类
3.接口与类
接口中属性为public static final。方法为public abstract。
子类的权限不能比父类更低
JAVA 子类重写继承的方法时,不可以降低方法的访问权限,子类继承父类的访问修饰符要比父类的更大,也就是更加开放,假如我父类是protected修饰的,其子类只能是protected或者public,绝对不能是friendly(默认的访问范围)或者private,当然使用private就不是继承了。还要注意的是,继承当中子类抛出的异常必须是父类抛出的异常的子异常,或者子类抛出的异常要比父类抛出的异常要少。
4.String相关
Java中String不是基本类型,但是有些时候和基本类型差不多,如String b = "tao" ; 可以对变量直接赋值,而不用 new 一个对象(当然也可以用 new)。所以String这个类型值得好好研究下。
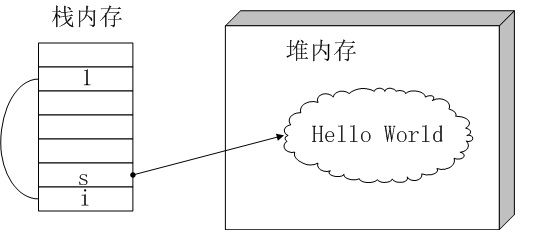
Java中的变量和基本类型的值存放于栈内存,而new出来的对象本身存放于堆内存,指向对象的引用还是存放在栈内存。例如如下的代码:
int i=1;
String s = new String( "Hello World" );
变量i和s以及1存放在栈内存,而s指向的对象”Hello World”存放于堆内存。
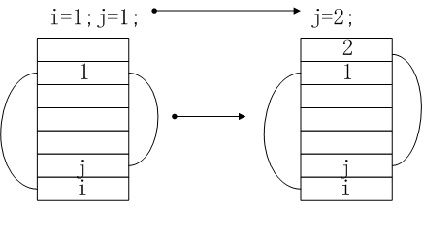
栈内存的一个特点是数据共享,这样设计是为了减小内存消耗,前面定义了i=1,i和1都在栈内存内,如果再定义一个j=1,此时将j放入栈内存,然后查找栈内存中是否有1,如果有则j指向1。如果再给j赋值2,则在栈内存中查找是否有2,如果没有就在栈内存中放一个2,然后j指向2。也就是如果常量在栈内存中,就将变量指向该常量,如果没有就在该栈内存增加一个该常量,并将变量指向该常量。
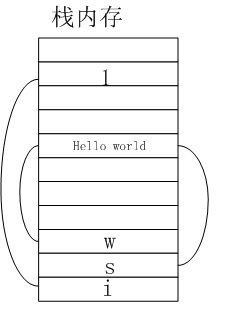
如果j++,这时指向的变量并不会改变,而是在栈内寻找新的常量(比原来的常量大1),如果栈内存有则指向它,如果没有就在栈内存中加入此常量并将j指向它。这种基本类型之间比较大小和我们逻辑上判断大小是一致的。如定义i和j是都赋值1,则i==j结果为true。==用于判断两个变量指向的地址是否一样。i==j就是判断i指向的1和j指向的1是同一个吗?当然是了。对于直接赋值的字符串常量(如String s=“Hello World”;中的Hello World)也是存放在栈内存中,而new出来的字符串对象(即String对象)是存放在堆内存中。如果定义String s=“Hello World”和String w=“Hello World”,s==w吗?肯定是true,因为他们指向的是同一个Hello World。
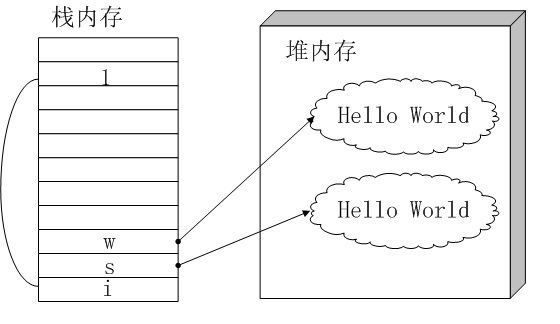
堆内存没有数据共享的特点,前面定义的String s = new String( "Hello World" );后,变量s在栈内存内,Hello World 这个String对象在堆内存内。如果定义String w = new String( "Hello World" );,则会在堆内存创建一个新的String对象,变量w存放在栈内存,w指向这个新的String对象。堆内存中不同对象(指同一类型的不同对象)的比较如果用==则结果肯定都是false,比如s==w?当然不等,s和w指向堆内存中不同的String对象。如果判断两个String对象相等呢?用equals方法。
说了这么多只是说了这道题的铺垫知识,还没进入主题,下面分析这道题。 MESSAGE 成员变量及其指向的字符串常量肯定都是在栈内存里的,变量 a 运算完也是指向一个字符串“ taobao ”啊?是不是同一个呢?这涉及到编译器优化问题。对于字符串常量的相加,在编译时直接将字符串合并,而不是等到运行时再合并。也就是说
String a = "tao" + "bao" ;和String a = "taobao" ;编译出的字节码是一样的。所以等到运行时,根据上面说的栈内存是数据共享原则,a和MESSAGE指向的是同一个字符串。而对于后面的(b+c)又是什么情况呢?b+c只能等到运行时才能判定是什么字符串,编译器不会优化,想想这也是有道理的,编译器怕你对b的值改变,所以编译器不会优化。运行时b+c计算出来的"taobao"和栈内存里已经有的"taobao"是一个吗?不是。b+c计算出来的"taobao"应该是放在堆内存中的String对象。这可以通过System. out .println( (b+c)== MESSAGE );的结果为false来证明这一点。如果计算出来的b+c也是在栈内存,那结果应该是true。Java对String的相加是通过StringBuffer实现的,先构造一个StringBuffer里面存放”tao”,然后调用append()方法追加”bao”,然后将值为”taobao”的StringBuffer转化成String对象。StringBuffer对象在堆内存中,那转换成的String对象理所应当的也是在堆内存中。下面改造一下这个语句System. out .println( (b+c).intern()== MESSAGE );结果是true, intern() 方*先检查 String 池 ( 或者说成栈内存 ) 中是否存在相同的字符串常量,如果有就返回。所以 intern()返回的就是MESSAGE指向的"taobao"。再把变量b和c的定义改一下,
**final** String b = "tao" ;
**final** String c = "bao" ;
System. *out* .println( (b+c)== *MESSAGE* );
现在b和c不可能再次赋值了,所以编译器将b+c编译成了”taobao”。因此,这时的结果是true。
在字符串相加中,只要有一个是非final类型的变量,编译器就不会优化,因为这样的变量可能发生改变,所以编译器不可能将这样的变量替换成常量。例如将变量b的final去掉,结果又变成了false。这也就意味着会用到StringBuffer对象,计算的结果在堆内存中。
如果对指向堆内存中的对象的String变量调用intern()会怎么样呢?实际上这个问题已经说过了,(b+c).intern(),b+c的结果就是在堆内存中。对于指向栈内存中字符串常量的变量调用intern()返回的还是它自己,没有多大意义。它会根据堆内存中对象的值,去查找String池中是否有相同的字符串,如果有就将变量指向这个string池中的变量。
String a = "tao"+"bao";
String b = new String("taobao");
System.out.println(a==MESSAGE); //true
System.out.println(b==MESSAGE); //false
b = b.intern();
System.out.println(b==MESSAGE); //true
System. *out* .println(a==a.intern()); //true
5.Hibernate
优化Hibernate所鼓励的7大措施:
1.尽量使用many-to-one,避免使用单项one-to-many
2.灵活使用单向one-to-many
3.不用一对一,使用多对一代替一对一
4.配置对象缓存,不使用集合缓存
5.一对多使用Bag 多对一使用Set
6.继承使用显示多态 HQL:from object polymorphism="exlicit" 避免查处所有对象
7.消除大表,使用二级缓存
6. i++
如果你理解JVM的内存模型,就不难理解为什么答案返回的是0,而不是1。
我们单独看问题中的这两句代码。
1
int i = 0; i = i++;
Java虚拟机栈(JVM Stack)描述的是Java方法执行的内存模型,而JVM内存模型是基于“栈帧”的,每个栈帧中都有 局部变量表 和 操作数栈 (还有动态链接、return address等),那么JVM是如何执行这个语句的呢?通过javap大致可以将上面的两行代码翻译成如下的JVM指令执行代码。
0: iconst_0
1: istore_1
2: iload_1
3: iinc 1, 1
6: istore_1
7: iload_1
接下来分析一下JVM是如何执行的:
第0:将int类型的0入栈,就是放到操作数栈的栈顶
第1:将操作数栈栈顶的值0弹出,保存到局部变量表 index (索引)值为1的位置。(局部变量表也是从0开始的,0位置一般保存当前实例的this引用,当然静态方法例外,因为静态方法是类方法而不是实例方法)
第2:将局部变量表index 1位置的值的副本入栈。(这时局部变量表index为1的值是0,操作数栈顶的值也是0)
第3:iinc是对int类型的值进行自增操作,后面第一个数值1表示,局部变量表的index值,说明要对此值执行iinc操作,第二个数值1表示要增加的数值。(这时局部变量表index为1的值因为执行了自增操作变为1了,但是操作数栈中栈顶的值仍然是0)
第6:将操作数栈顶的值弹出(值0),放到局部变量表index为1的位置(旧值:1,新值:0),覆盖了上一步局部变量表的计算结果。
第7:将局部变量表index 1位置的值的副本入栈。(这时局部变量表index为1的值是0,操作数栈顶的值也是0)
总结:从执行顺序可以看到,这里第1和第6执行了2次将0赋值给变量i的操作(=号赋值),i++操作是在这两次操作之间执行的,自增操作是对局部变量表中的值进行自增,而栈顶的值没有发生变化,这里需要注意的是保存这个初始值的地方是操作数栈而不是局部变量表,最后再将栈顶的值覆盖到局部变量表i所在的索引位置中去。
有兴趣的同学可以去了解一下JVM的栈帧(Stack Frame)
关于第二个陷阱(为什么 fermin方法没有影响到i的值 )的解答看下面。
1
inc.fermin(i);
- java方法之间的参数传递是 值传递 而不是 引用传递
- 每个方法都会有一个栈帧,栈帧是方法运行时的数据结构。这就是说每个方法都有自己独享的局部变量表。(更严谨的说法其实是每个线程在执行每个方法时都有自己的栈帧,或者叫当前栈帧 current stack frame)
- 被调用方法fermin()的形式参数int i 实际上是调用方法main()的实际参数 i 的一个副本。
- 方法之间的参数传递是通过局部变量表实现的,main()方法调用fermin()方法时,传递了2个参数:
第0个隐式参数是当前实例(Inc inc = new Inc(); 就是inc引用的副本,引用/reference 是指向对象的一个地址,32位系统这个地址占用4个字节,也就是用一个Slot来保存对象reference,这里传递的实际上是reference的一个副本而不是 reference本身 );
第1个显示参数是 i 的一个副本。所以 fermin()方法对 i 执行的操作只限定在其方法独享或可见的局部变量表这个范围内,main()方法中局部变量表中的i不受它的影响;
如果main()方法和fermin()方法共享局部变量表的话,那答案的结果就会有所不同。 其实你自己思考一下,就会发现, JVM虚拟机团队这么设计是有道理的。
7.线程安全
线程安全(Thread-safe)的集合对象:
Vector 线程安全:
HashTable 线程安全:
StringBuffer 线程安全:
非线程安全的集合对象:
ArrayList :
LinkedList:
HashMap:
HashSet:
TreeMap:
TreeSet:
StringBulider: