数据库知识点
- 数据库相关概念
- mysql安装与使用
- navicat的使用
- SQL语言的查询(重点)
- 高级(了解)
一、数据库基本概念
数据库是什么
数据存储
1.人工管理阶段
- 结绳记事
- 甲骨
- 纸
人工阶段的数据存储使用起来不方便,不便于查询、共享、保存
2.文件系统阶段
- 磁盘
将数据存储在磁盘上,数据都存在文件中,查询很不方便
3.数据库系统阶段
- 数据库
长期存储在计算机内,有组织的数据集合,数据按照不同的分类存储到不同的表中,查询非常方便
RDBMS
Relational Database Managment System
关系型数据库系统
通过表来表示关系
- 当前主要有两种数据库,关系型数据库和非关系型数据库
- 所谓关系型数据库RDBMS ,是建立在关系模型的基础上的数据库,借助于集合代数等数学方法和概念来处理数据库中的数据
- 查看数据库排名 DB-Engines Ranking
关系型数据库核心元素
- 数据行(一条记录)
- 数据列(字段)
- 数据表(数据行集合)
- 数据库(数据表集合,一个数据库能有多个数据表)
SQL
Structured Query Language
结构化查询语言
在数据库中进行操作的语言,称为sql,结构化查询语言,当前关系型数据库都支持使用sql语言进行操作。
- SQL语言主要分为:
- DQL,数据查询语言,用于对数据进行查询,如select
- DML,数据操作语言,对数据进行增加、修改、删除,如insert、update、delete
- TPL,事务处理语言,对事务进行处理,包括begin transaction、commit、rollback
- DCL,数据控制语言,进行授权于权限回收,如grant、revoke
- DDL,数据定义语言,进行数据库、表的管理,如creat、drop
- CCL,指针控制语言,通过控制指针完成表的操作,如declare cursor
- 对于测试工程师,重点是数据查询,需要熟练编写DDL,其他语言如TPL、DCL、CCL了解即可
- SQL是一门特殊的语言,专门用来操作关系型数据库
- SQL不区分大小写
MySQL
是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,后被Sun公司收购,Sun公司后被Oracle公司收购,所以现在是Oracle旗下的产品。
特点:开源 免费 使用范围广 支持多平台
二、MySQL的安装与使用
MySQL下载中,已包含服务端和客户端
Linux平台下安装
Windows平台下安装
MacOS平台下安装
1.从MySQL官网下载安装包
-
拉到最下面MySQL Community Edition
-
选择MySQL Community Server
 g
g -
选择历史版本5.7
-
选择dmg格式

-
开始下载

2.安装
-
各种继续

-
复制最后一步的密码,是mysql的初始密码
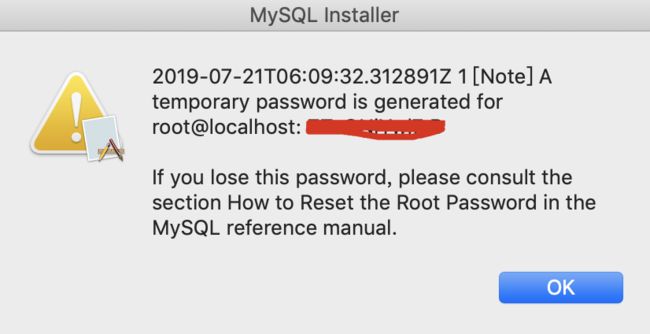
3.启动MySQL服务端
-
系统偏好设置-->MySQL
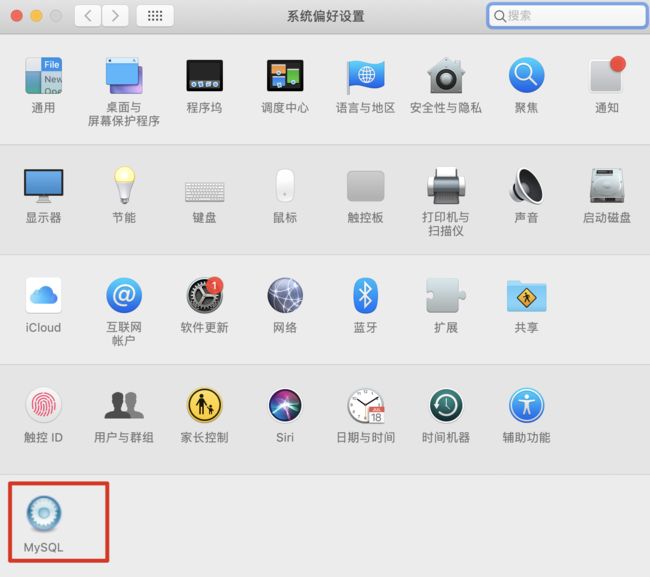
-
启动/停止MySQL服务
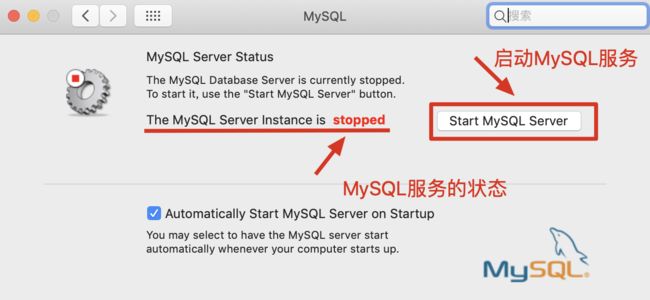

4.修改密码
- 打开终端
- 输入命令:
cd /usr/local/mysql/bin - 输入命令:
mysql -u root -p - 输入初始密码(安装的最后一步时,让记住的密码)
- 输入命令:
FLUSH PRIVILEGES; - 输入命令:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'MyNewPass';(MyNewPass处输入你的新密码)
5.配置环境变量
因为mysql的可执行命令在/usr/local/mysql/bin目录下,而这个目录不在普通用户的环境路径下,因此每次执行时都需要输入完整路径,比较麻烦。因此需要将这个路径添加到环境变量中。
打开终端
输入命令:
vim .bash_profile-
在.bash_profile文件中加入
#配置mysql环境变量 export PATH=${PATH}:/usr/local/mysql-5.7.26-macos10.14-x86_64/bin 输入命令:
source .bash_profile进行更新-
输入命令:
mysql -u root -p以及新设置的密码,出现welcome……吧啦吧啦表示环境变量配置成功遇到的问题
因为自己的Terminal,装了zsh+iTerm,所以它默认启动时执行的脚本文件是~/.zshrc文件,这就导致了每次关闭终端后,都需要重新source .bash_profilemysql配置才能生效
解决:
mac使用zsh后,文件.bash_profile中的配置无效
6.启动MySQL客户端
MySQL自带的客户端是命令行界面,其实前面已经操作过。
- 输入命令
mysql -u root -p和密码以root身份启动MySQL的客户端 - 在终端中出现mysql>,可以进行对数据库的操作
mysql>
7.使用Navicat连接MySQL服务端
-
Navicat安装
一般来说,测试常用的是图形界面的MySQL客户端,如Navicat。但是Navicat是收费软件,可试用14天,可以安装破解版,如果需要mac破解版的可以联系我。
三、Navicat的使用
连接数据库
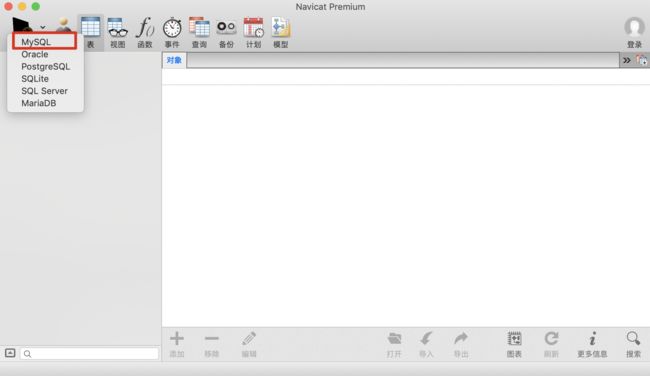
(1)选择数据库类型
服务端是什么数据库就选择什么数据库(MySQL)
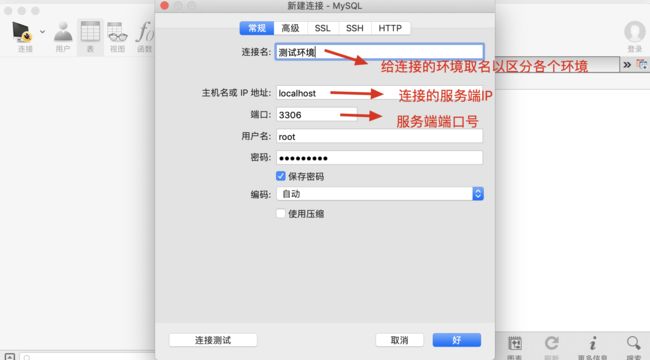
(2)填写连接信息(到公司问开发索要)
- 连接名:区分要接触到的各种环境,如测试环境、演示环境、生产环境
- 主机名或IP地址:MySQL服务端所在的IP,因为我们是在本机上安装并启动了MySQL服务,所以写localhost
- 端口号:默认是3306
-
用户名、密码:具备相应权限的用户名和密码(上文提到的root及修改后的密码)
(3)连接
此时是未连接状态,灰色。双击进行连接。
数据库操作
-
新建数据库
右键-新建数据库>>数据库名/选择默认字符集/默认排序规则


-
新建表
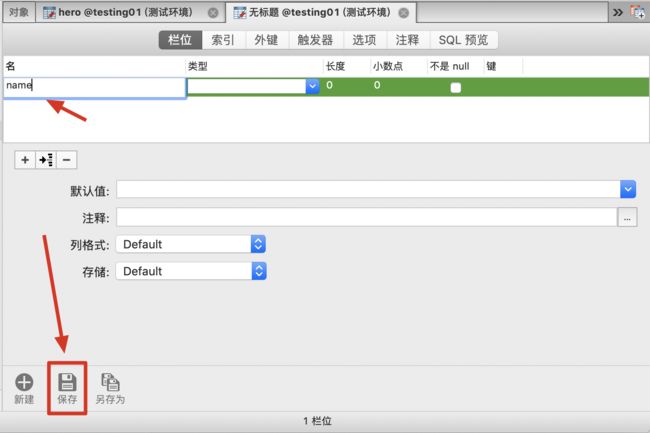
右键-新建表>>至少填写一个字段(name)>>保存为表(表名hero)
-
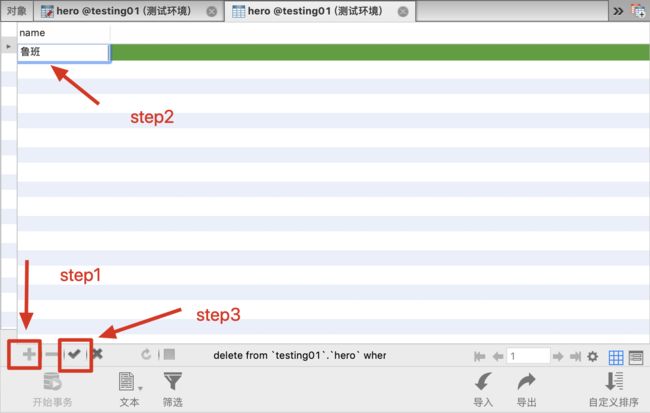
存一条数据
右键-打开表>>点击➕(增加)>>输入字段内容>>点击✅(完成)
- 修改一条数据
双击修改 - 删除一条数据
选中要删除的数据>>点击➖
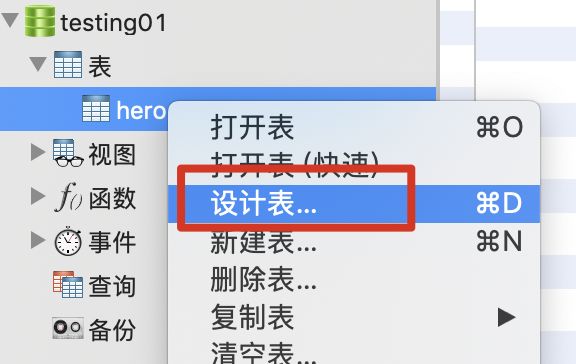
数据表操作
-
改表
-
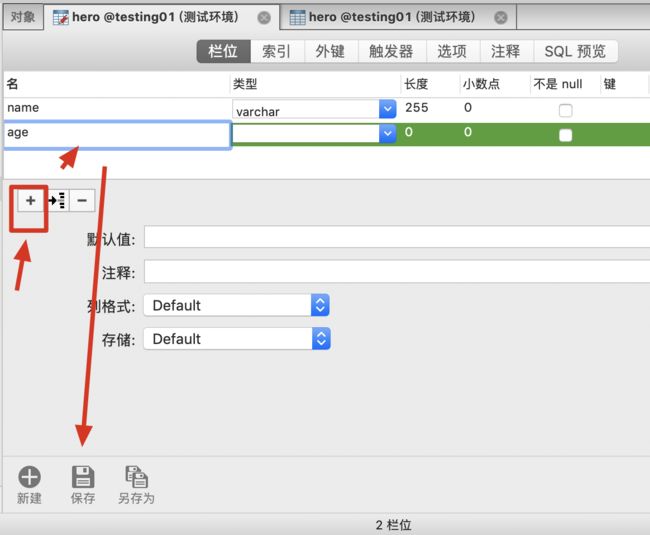
添加表字段
点击➕>>写入字段名>>保存
- 删除表字段
选中删除行>>点击➖>>保存
数据类型与约束
-
常用数据类型
-
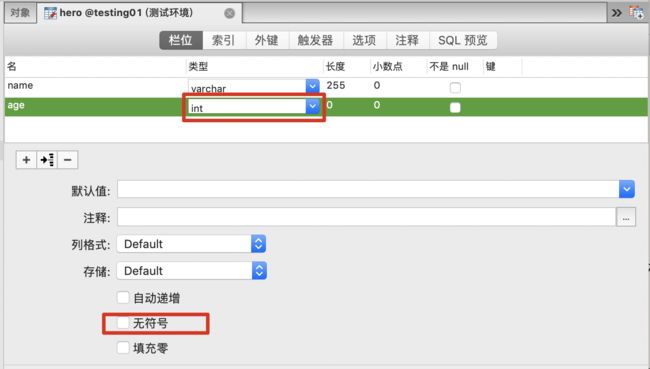
整数 int
-2^31 (-2,147,483,648) 到 2^31 - 1 (2,147,483,647) ,无符号的范围是0到4294967295。
- 小数 decimal decimal(5,2),共存5位数,小数占2位
- 字符串 varchar varchar(3),最多存3个字符,一个中文或一个英文都是一个字符
- 日期时间 datetime
tips:数据类型的取值范围可以通过命令查看
mysql -u root -p-
help 数据类型
如help int,表示int的取值范围
-
-
约束
-
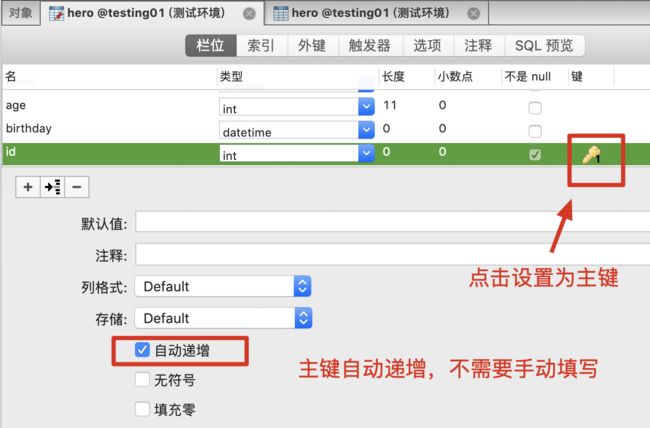
主键(primary key):物理上存储的顺序。
不能重复的一列且必须有值。
自动递增从1开始,删除一条数据,主键依然被占用。
一般作为主键使用时,int类型+自动递增+无符号
-
非空(not null):此字段不允许填空值
不能不填值。
字段后面勾选不是null,即表示该字段不允许填空值。
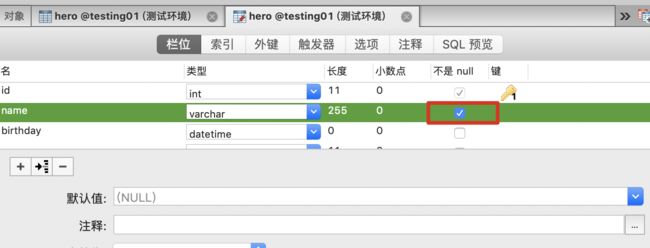
唯一(unique):此字段不允许重复
跟主键有点类似,值不重复。但主键是用来唯一标识一条信息。同一张表只能有一个主键,但能有多个唯一约束;-
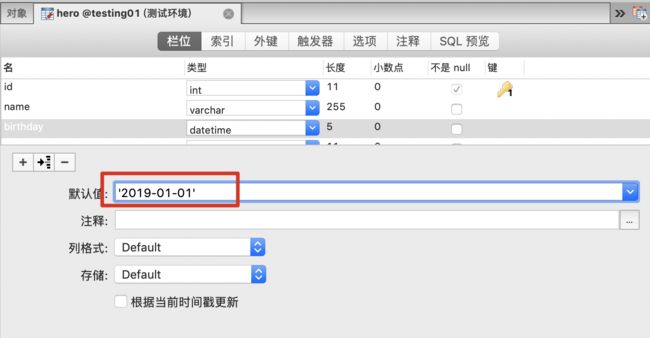
默认值(default):当不填写此值时会使用默认值,如果填写时以填写为准

外键(foreign key):维护两个表之间的关联关系
【属于高级内容,后面讲】
-
数据库的备份与恢复
-
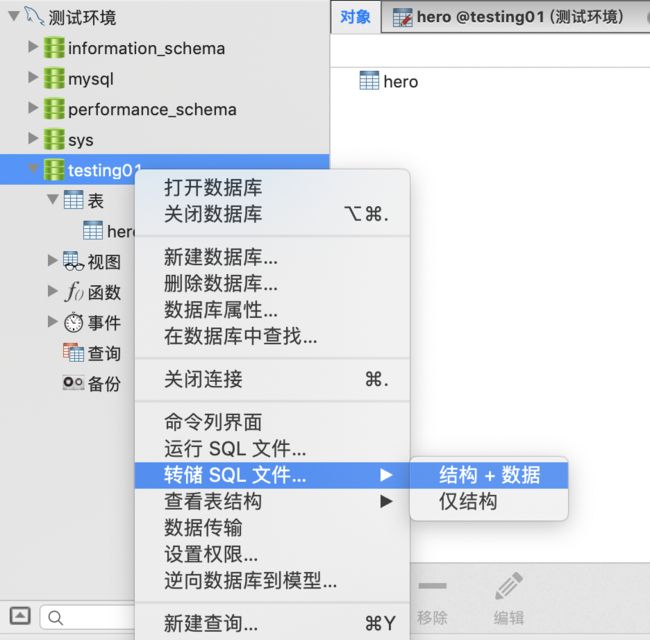
备份
-
右键>>转储SQL文件>>结构+数据
-
保存为一个.sql文件

-
.sql文件里存的是SQL语句和数据
-
-
恢复
- 新建一个数据库
选择与要恢复的表相同的字符集和默认排序规则 - 右键>>运行SQL文件>>选择要恢复的.sql文件
- 刷新
- 新建一个数据库
三、SQL语言
查询编辑器介绍
- 注释 ctrl+/
- 修改注释的颜色 偏好设置>>字体和颜色>>编辑器颜色
- 选中要运行的语句,右键选择“运行已选择的”
数据表操作
- 创建表
create table 表名 ( 字段名 类型 [约束], 字段名 类型 [约束] …… )-- 创建一个newHero表 CREATE TABLE newHero ( id int unsigned primary key auto_increment, name VARCHAR(10), age int unsigned, height decimal(5,2), contact varchar(10) not null )

- 删除表
格式一:drop table 表名表名存在就删除,表名不存在就报错
格式二:drop table if exists 表名表名存在就删除,表名不存在也不报错,一般使用格式二,搭配在create语句前面写。
drop table if exists hero;
create table hero (
id int unsigned primary key auto_increment,
name VARCHAR(10),
age int unsigned,
height decimal(5,2),
contact varchar(10) not null
)
数据操作-增删改
增
格式一:所有字段设置值,值的顺序与表中字段顺序对应
insert into 表名 values (……);
说明:主键列自动增长,插入时要占位,通常使用0或者defualt或者null来占位
insert into newHero values (default,'小鲁班',15,140.55,'tony');
insert into newHero values (0,'小亚瑟',20,185.00,'tony');
insert into newHero values (null,'小守约',18,180.00,'herry');
格式二:指定字段设置值,值的顺序跟给出的字段对应
insert into 表名(字段名1,字段名2,……) values (字段值1,字段值2,……);
-- 添加一行数据 --
insert into newHero(name,contact) values('小文姬','relics');
-- 添加多行数据 --
insert into newHero(name,contact) values('小露娜','luna'),('小悟空','merry');
改
格式:update 表名 set 列1=值1,列2=值2……where 条件
-- 修改name为小鲁班的身高为135.00,年龄为12 --
update newHero set height=135.00,age=12 where name='小鲁班';
删
格式:delete from 表名 where 条件
-- 删除id为7的这条数据 --
delete from newHero where id=7;
逻辑删除:对于重要的数据 ,不能轻易执行delete语句进行删除,一旦删除,数据无法恢复,这时可以进行逻辑删除。
1.给表添加字段,代表数据是否删除,一般起名isdeleted,0代表未删除,1代表删除,默认值为0。
2.当要删除某条数据时,只需要设置isdeleted字段的值为1
3.以后查询数据时,只查询出isdeleted为0的数据
数据操作-查询
创建表
drop table if exists students;
create table students(
studentNo varchar(10) primary key,
name varchar(10),
sex varchar(1),
hometown varchar(20),
age tinyint(4),
class varchar(10),
card varchar(20)
)
准备数据
insert into students values ('001','王昭君','女','北京','20','1班','340322199001249654'),
('002','诸葛亮','男','上海','20','2班','340322199002242345'),
('003','张飞','男','南京','24','3班','340322199003242045'),
('004','白起','男','安徽','19','2班','340322199004249999'),
('005','大乔','女','天津','18','3班','340322199005242343'),
('006','孙尚香','女','安徽','24','2班','340322199006241233'),
('007','小乔','女','山西','20','2班','340322199007246789'),
('008','百里飞','男','河南','25','2班','340322199008242345'),
('009','百里守约','男','河南','30','2班',''),
('010','妲己','女','贵州','20','1班',null);
查询所有字段
select * from 表名;
例:
select * from students;
查询指定字段
- 在select后面的列名部分,可以使用as为列起别名,这个别名出现在结果集中。
select 列1,列2,...from 表名;
--表名.字段名
select students.name,students.age from students;
--可以通过as给表起名
select s.name,s.age from students as s;
--如果是单表查询可以省略表名
select name,age from students;
--用as给字段起别名
select name as 姓名,age as 年龄 from students;
--查询性别有哪几种
select distinct sex from students;
消除重复行
- 在select后面列前使用distinct可以消除重复的行
select dictinct 列1,...from 表名;
例:
--sex 去重
select distinct sex from students;
--sex+age的组合去重
select distinct sex,age from students;
条件查询
- 使用where子句对表中的数据筛选,符号条件的数据会出现在结果集中。
- 语法如下:
select 字段1,字段2... from 表名 where 条件;
例:
select * from students where id=1;
-
where后面支持多种运算符,进行条件的处理
- 比较运算
- 逻辑运算
- 模糊查询
- 范围查询
- 空判断
-
比较运算符
- 等于: =
- 大于: >
- 大于等于: >=
- 小于: <
- 小于等于: <=
- 不等于: != 或<>
-- 查询小乔的年龄 select age from students where name='小乔'; -- 查询年龄在20岁一下的同学的名字 select name from students where age<20; -- 查询家乡不在天津的同学的名字 select name from students where hometown!='天津'; -
逻辑运算符
- and
- or
- not
---查询年龄小于20的女同学 select * from students where age<20 and sex='女'; ---查询非天津的学生 select * from students where not hometown '天津'; -
模糊查询
- like 结合%和_搭配使用
- % 表示任意多个任意字符
- _表示一个任意字符
--查询姓百里的同学 select * from students where name like '百里%'; --查询姓百里且名只有一个字的同学 select * from students where name like '百里_'; --查询名字中包含有里的同学 select * from students where name like '%里%'; -
范围查询
- in表示在一个非连续的范围内
- between...and...表示在一个连续的范围内
--查询家乡是北京或上海或广州的学生 select * from students where hometown in('北京','上海','广州'); --查询年龄为18至22的学生 select * from students where age between 18 and 22; -
空判断
注意
null与''是不同的判空is null
--查询没有填写身份证的同学 select * from students where card is null;- 判非空is not null
--查询填写了身份证的同学 select * from students where card is not null;
排序查询
- 为了方便查看数据,可以对数据进行排序
- 语法
select * from 表名
order by 列1 asc|desc,列2 asc|desc,...;
- 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
- 默认按照列值从大到小排列,默认升序
- asc从小到大,升序排列
- desc 从大到小,降序排列
--查询所有学生信息,按年龄从小到大排列
select * from students order by age;
--查询所有学生信息,按年龄从大到小排列,年龄相同时,再按学号从小到大排列
select * from students order by age desc,studentNo asc;
--查询所有学生信息,按姓名从a-z排序(对中文进行排序)
select * from students order by convert(name using gbk);
聚合函数
- 为了快速得到统计数据,经常会使用到如下5个聚合函数
- count(*)表示计算总行数,括号中写星与列名,结果都是相同的
- 聚合函数不能在where中使用
--计数count(*)
--查询学生总数
select count(*) from students;
--max(列)表示求此列最大值
--查询女生的最大年龄
select max(age) from students where sex='女';
--min(列)表示求此列最大值
--查询1班的最小年龄
select min(age) from students where class='1班';
--sum(列)表示求此列的和
-- 查询北京的学生的年龄总和
select sum(age) from students where hometown='北京';
--avg(列)表示求此列的平均值
--查询女生的平均年龄
select avg(age) from students where sex='女';
分组
- 按照字段分组,表示此字段相同的数据会被放到一个组中
- 分组后,分组的依据列会显示在结果中,其他列不会显示在结果集中
- 可以对分组后的数据进行统计,做聚合运算
- 语法
select 列1,列2,聚合... from 表名 group by 列1,列2,…;
--查询各种性别的人数
select sex,count(*) from students group by sex;
--查询各种年龄的人数
select age,count(*) from students group by age;
--查询各个班级学生的平均年龄、最大年龄、最小年龄
select class,avg(age),max(age),min(age) from students group by class;
--查询各班男女生人数
select class,sex,count(*) from students group by class,sex;
-
分组后过滤 having
语法:select 列1,列2,... from 表名 group by 列1,列2,... having 列1,列2,...聚合 ; --having后面的条件运算符与where一样--查询男生的总人数 --方法1: select sex,count(*) from students where sex='男'; --方法2: select sex,count(*) from students group by sex having sex='男'; where与having 对比
where是对from后面指定的表进行数据筛选,属于对原始表的筛选
having是对group by的结果进行筛选
分页
获取部分行
- 当数据量过大时,在一页中查看数据是一件非常麻烦的事情
- 语法
select * from 表名 limit strat,count- 从strat开始,获取count条数据
- start索引从0开始
--查询前3行学生信息 select * from students limit 0,3 --查询第4行到第6行学生信息 select * from students limit 3,3
分页
-- 需求分页, 每页3条数据 --
-- 总共有多少条 10条
select count(*) from students;
-- 10/3 获取总页数,共4页
-- 第一页 --3(1-1)
select * from students limit 0,3;
-- 第二页 --3(2-1)
select * from students limit 3,3;
-- 第三页 --3(3-1)
select * from students limit 6,3;
-- 第四页 --3(4-1)
select * from students limit 9,3;
- 分页功能实现原理就是,点击按钮时,执行对应的sql,每个sql语句的起始位置不一样。
连接查询
- 当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回
-
等值连接查询:查询结果为两个表匹配到的数据

-
左连接:查询到的结果为两个表匹配到的数据加左表特有的数据,对于右表中不存在的数据使用null填充
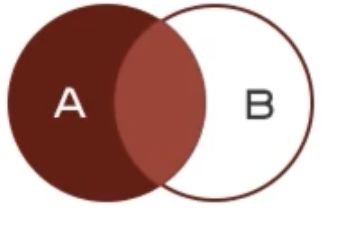
-
右连接:查询到的结果为两个表匹配到的数据加右表特有的数据,对于左表中不存在的数据使用null填充
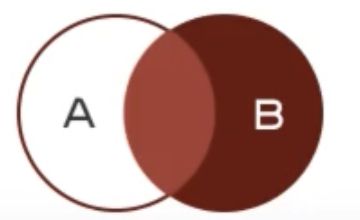
准备数据
drop table if exists courses;
create table courses(
courseNo int(10) unsigned primary key auto_increment,
name varchar(10)
)
insert into courses values
('1','数据库'),
('2','qtp'),
('3','linux'),
('4','系统测试'),
('5','单元测试'),
('6','测试过程');
drop table if exists scores;
create table scores(
id int(10) unsigned primary key auto_increment,
courseNo int(10),
studentNo varchar(10),
score tinyint(4)
);
insert into scores VALUES
('1','1','001','90'),
('2','1','002','75'),
('3','2','002','98'),
('4','3','001','86'),
('5','3','003','80'),
('6','4','004','79'),
('7','5','005','96'),
('8','6','006','80');
-
等值连接
- 方式一
select * from 表1,表2 where 表1.列=表2.列;
此方式会产生笛卡尔积,生成的记录总数=表1的总数X表2的总数,会产生临时表。- 笛卡尔积原理
1.先确定数据要用到哪些表。(表1,表2)
2.将多个表先通过笛卡尔积变成一个表
select * from 表1,表2,表1的每一行X表2的每一行
3.然后去除不符合逻辑的数据(根据两个表的关系去掉)
表1.列=表2.列
4.最后当做是一个虚拟表一样来加上条件即可
- 笛卡尔积原理
- 方式二(内连接)
select * from 表1 inner join 表2 on 表1.列=表2.列;- 内连接是先判断是否符合
表1.列=表2.列再生成结果 - 不会产生临时表,性能高
- 内连接是先判断是否符合
--查询学生信息及学生成绩 -两种方法 SELECT * FROM students stus, scores sco WHERE stus.studentNo = sco.studentNo; -------- SELECT stus. NAME, sco.score FROM students stus INNER JOIN scores sco ON stus.studentNo = sco.studentNo; -- 查询课程信息及课程的成绩 select * from courses cou, scores sco where cou.courseNo=sco.courseNo; ------- select * from courses cou inner join scores sco on cou.courseNo=sco.courseNo; -- 查询学生信息及学生的课程对应的成绩(3表查询) select * from students stu,courses cour,scores sco where stu.studentNo=sco.studentNo and cour.courseNo=sco.courseNo; ----- select * from students stu inner join scores sco on stu.studentNo=sco.studentNo inner join courses cour on cour.courseNo=sco.courseNo; -- 查询王昭君的成绩,要求显示姓名、课程名、成绩 select stu.name as 姓名,cour.name as 课程名,score 成绩 from students stu inner join scores sco on stu.studentNo=sco.studentNo inner join courses cour on cour.courseNo=sco.courseNo where stu.name ='王昭君' - 方式一
左连接
select * from 表1
left join 表2 on 表1.列=表2.列
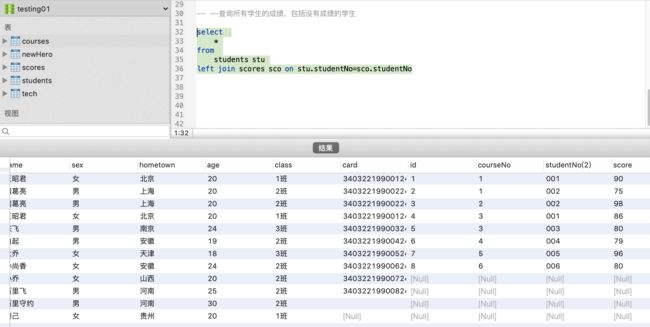
--查询所有学生的成绩,包括没有成绩的学生(2表查询)
select
*
from
students stu
left join scores sco on stu.studentNo=sco.studentNo
对于左表不存在的数据用null填充
-- 查询所有学生的成绩,包括没有成绩的学生,显示课程名(3表查询)
select
stu.name,sco.score,cour.courseNo
from
students stu
left join scores sco on stu.studentNo=sco.studentNo
left join courses cour on cour.courseNo=sco.courseNo
- 右连接
select * from 表1
right join 表2 on 表1.列=表2.列
为了便于练习,在此数据库加入两条数据:
insert into courses values
(0,'语文'),
(0,'数学')
--查询所有课的成绩,包括没有成绩的课程(2表查询)
select
*
from
scores sco
right join courses cour on cour.courseNo=sco.courseNo;
--查询所有课程的成绩,包括没有成绩的课程,包括学生信息(3表查询)
select
*
from
scores sco
right join courses cour on cour.courseNo=sco.courseNo
left join students stu on sco.studentNo=stu.studentNo;
-- 注意区分要让左边全显示还是右边全显示
练习
-- 查询所有学生的成绩 包括没有成绩的学生,显示课程名
select
stu.name,cour.name,score
FROM
students stu
left join scores sco on stu.studentNo=sco.studentNo
left join courses cour on sco.courseNo=cour.courseNo;
自关联
- 表中的某一列,关联了这个表的另外一列,但是它们的业务逻辑含义是不一样的。
| 编号 | 城市 | 上级编号 |
|---|---|---|
| 01 | 湖南省 | |
| 02 | 长沙市 | 01 |
| 03 | 岳阳市 | 01 |
| 05 | 陕西省 | |
| 06 | 西安市 | 05 |
| 07 | 咸阳市 | 05 |
准备数据
drop table if exists areas;
create table areas(
aid int primary key,
atitle varchar(20),
pid int
);
insert into areas values
('130000','河北省',NULL),
('130100','石家庄市','130000'),
('130400','邯郸市','130000'),
('130600','保定市','130000'),
('130700','张家口市','130000'),
('130800','承德市','130000'),
('410000','河南省',null),
('410100','郑州市','410000'),
('410300','洛阳市','410000'),
('410500','安阳市','410000'),
('410700','新乡市','410000'),
('410800','焦作市','410000');
--查询一共有多少个省
select count(*) from areas where pid is null;
--查询河南省所有城市(自关联2次)
select
*
from
areas pro,areas city
where
pro.aid=city.pid and pro.atitle='河南省';
添加区县数据
insert into areas values
('410101','中原区','410100'),
('410102','二七区','410100'),
('410103','金水区','410100');
--查找河南省所有区县(关联3次)
select * from areas pro,areas city,areas qu
where pro.aid=city.pid and city.aid=qu.pid and pro.attle='河南省';
子查询
- 在一个select语句中,嵌入了另一个select语句,那么被嵌入的select语句称之为子查询语句
主查询:
- 主要查询的对象,第一条select语句
主查询和子查询的关系:
- 子查询是嵌入到主查询中的
- 子查询是辅助主查询的,要么充当条件,要么充当数据源
- 子查询是可以独立存在的,是一条完整的select语句
子查询的分类:
- 标量子查询:子查询返回的结果是一个数据(一行一列)
- 列子查询:返回的结果是一列(一列多行)
- 行子查询:返回的结果是一行(一行多列)
- 表级子查询:返回的结果是多行多列
标量子查询
--查询年龄大于平均年龄的学生
--方法1:
--1.求出平均年龄的值为22
select avg(age) from students;
--2.求age大于22的学生
select * from students where age > 22;
--方法2:
select * from students where age > (select avg(age) from students);
--ps:第一个select语句就是主查询,第二个select语句就是子查询
--查询王昭君的数据库成绩
select
score
from
scores
where
studentNo=(select studentNo from students where name ='王昭君')
and courseNo=(select courseNo from courses where name='数据库');
列级子查询
--查询20岁的学生的成绩,要求显示成绩
--方法1:
--1.求出age等于20的学号是001,002,007,010
select studentNo from students where age=18;
--2.求学号是005的成绩
select score from scores where studentNo in(001,002,007,010);
--方法2:
select score from scores where studentNo in(select studentNo from students where age);
行级子查询
--查询男生中年龄最大的学生信息
--方法1:标量子查询
select max(age) from students; --30
select * from students where sex='男' and age=(select max(age) from students);
--where后面条件都是且关系的,可以有另一种写法
select * from students where (sex,age)=('男','30');
--方法2:行级子查询
--1.返回sex,age(一行多列)
select sex,age from students where sex='男' order by age desc limit 1;
--2.
select
*
from
students
where
(sex,age)=(select sex,age from students where sex='男' order by age desc limit 1);
表级子查询
- 标量子查询、列级子查询、行级子查询都是作为where条件,而表级子查询是作为数据源。
--查询数据库和系统测试的成绩
--方法1:
select * from courses
inner join scores on courses.courseNo=scores.courseNo
where courses.name in('数据库','系统测试');
--先连接了两个表,再筛选,连接两表时,多了很多无效数据。
--方法2:
select * from scores a
inner join (select courseNo from courses where name in('数据库','系统测试')) b
on a.courseNo=b.courseNo;
--直接连接筛选后的表,会快一些
子查询中特定的关键字
- in 范围
- 格式:主查询 where 条件 in(列子查询)
- any | some 任意一个
- 格式:主查询 where 列=any(列子查询)
- 在条件查询的结果中匹配任意一个即可,
=any等价于in
- all
- 格式:主查询 where 列=all(列子查询):等于里面所有
- 格式:主查询 where 列<>all(列子查询):不等于其中所有
查询演练
-- 求所有学生的平均成绩,保留两位小数
select round(avg(score),2) as 平均成绩 from scores;
-- 查询年龄大于平均年龄的学生,并按年龄降序排序
select * from students
where age >(select avg(age) from students) order by age desc;
-- 查询年龄大于王昭君的学生,并按年龄降序排列
select * from students
where age>(select age from students where name='王昭君') order by age desc;
数据分表
-
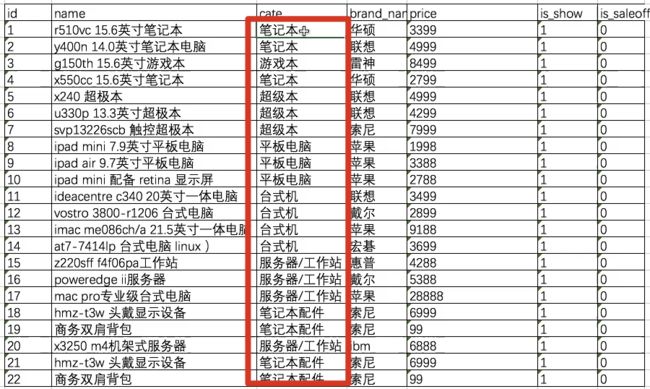
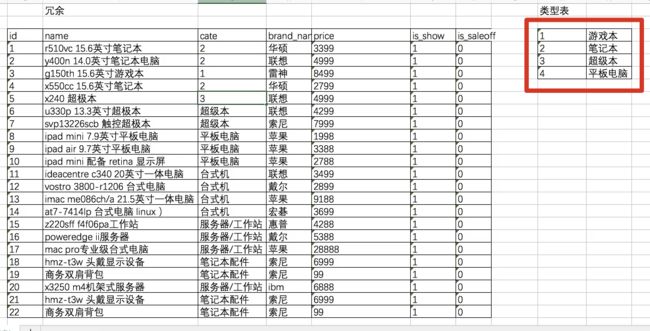
一个表中某一列出现了重复的内容,叫冗余内容,采用数据分表,减少内存。
如下表,笔记本类型,出现了大量重复文字。
可以增加一个新表,类型表,来存储笔记本所有类型,给类型加上编号,需要用到笔记本类型时,填入编号。
另一个好处,如果笔记本类型变了,只用改类型表即可。
四、数据库高级
数据库设计
E-R模型
E-R模型的基本元素是:实体、联系和属性
- E表示entry,实体:一个数据对象,描述具有相同特征的事物
- R表示relationship,联系:表示一个或多个实体之间的关联关系,关系的类型包括一对一、一对多、多对多
- 属性:实体的某一特性称为属性
关系也是一种数据,需要通过一个字段存储在表中
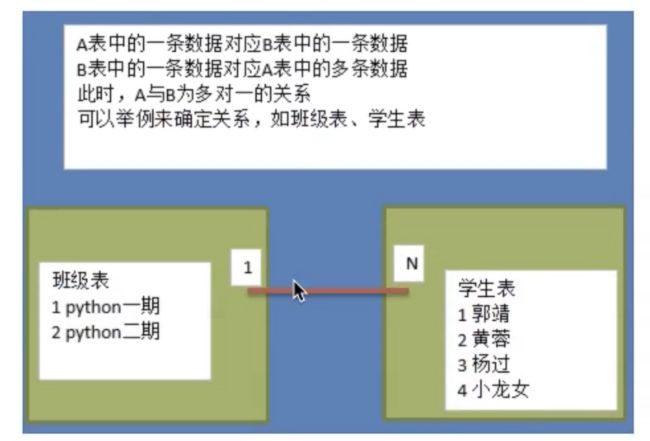
1.实体A对实体B为1对1,则在表A或表B中创建一个字段,存储另一个表的主键。(让使用频率少的表来维护关系)

2.实体A对实体B为1对多:在表中创建一个字段,存储表A的主键值(让"多"的一方的表来维护关系)
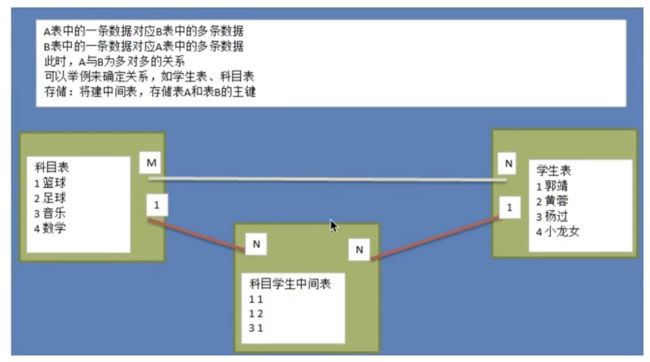
3.实体A对实体B为多对多:新建一个表C, 这个表只有两个字段,一个用于存储A的主键值,一个用于存储B的主键值。(让中间表C来维护关系)
命令行客户端
windows
- 程序-MySQL-MySQL server-MySQL Commandline Client
- 输入密码
mac
- 进入bin目录
cd /usr/local/mysql-5.7.26-macos10.14-x86_64/bin - 输入命令
mysql -u root -p和密码以root身份启动MySQL的客户端 - 在终端中出现mysql>,可以进行对数据库的操作
mysql>
常用命令
-
展示所有的数据库
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | testing01 | +--------------------+ 5 rows in set (0.00 sec) -
使用某个数据库
mysql> use testing01; Database changed -
使用select语句
mysql> select * from students; ps:使用select语句之前必须先use要使用的数据库,否则会报错 --- mysql> select * from students; ERROR 1046 (3D000): No database selected -
查看当前使用的数据库
mysql> select database(); +------------+ | database() | +------------+ | testing01 | +------------+ 1 row in set (0.00 sec) -
创建数据库
create database 数据库名 charset=utf8;mysql> create database testing02 charset=utf8; Query OK, 1 row affected (0.01 sec) -
删除数据库
drop database 数据库名;mysql> drop database testing02; Query OK, 0 rows affected (0.02 sec) -
查看当前数据库所有表
mysql> show tables; +---------------------+ | Tables_in_testing01 | +---------------------+ | areas | | courses | | newHero | | scores | | students | | tech | +---------------------+ 6 rows in set (0.00 sec) -
查看表结构
方法一: mysql> desc students; +-----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------+-------------+------+-----+---------+-------+ | studentNo | varchar(10) | NO | PRI | NULL | | | name | varchar(10) | YES | | NULL | | | sex | varchar(1) | YES | | NULL | | | hometown | varchar(20) | YES | | NULL | | | age | tinyint(4) | YES | | NULL | | | class | varchar(10) | YES | | NULL | | | card | varchar(20) | YES | | NULL | | +-----------+-------------+------+-----+---------+-------+ 7 rows in set (0.01 sec) 方法二: mysql> show create table students; 展示创建students表的SQL语句。 -
中文乱码
mysql>set charset gbk; 备份和恢复
备份
- 进入bin目录
cd /usr/local/mysql-5.7.26-macos10.14-x86_64/bin - 输入命令
mysqldump -u root -p密码 数据库名 > 备份路径;
mysqldump -u root -padmin1234 testing01>~/back.sql
恢复
- 先新建一个数据库 testing03
- 输入命令
mysql -uroot -padmin1234 testing03<~/back.sql
函数
-
字符串函数
拼接字符串 concat(str1,str2,...)
select name,hometown,CONCAT(name,'的家乡是',hometown) from students;-
包含字符个数 length(str)
1个英文、数字、字符的length都是1,但是1个中文的length是3--查询名字是两个字的学生 select * from students where length(name)=6; -
截取字符串
- left(str,len) 返回字符串str的左端len个字符
- right(str,len) 返回字符串str的右端len个字符
- substring(str,pos,len) 返回字符串str的位置pos起len个字符
--隐藏学生的名,只显示学生的姓氏 select concat(left(name,1),'**')from students; -
去除空格
- ltrim(str) 返回删除了左空格的字符串str
- rtrim(str) 返回删除了右空格的字符串str
- ltrim(rtrim(str)) 左右空格都去掉
- trim(str) 左右空格都去掉
- 中间的空格没法去掉
-
大小写转换
- lower(str)
- upper(str)
select lower('aBadQ');
-
数学函数
求四舍五入的值
round(n,b)n表示原数,d表示小数位数,默认为0
select round(1.555,2);求x的y次幂
pow(x,y)
select pow(2,3);获取圆周率
PI()
select PI();随机数
rand(),值为0-1.0的浮点数
select rand();
拓展:随机从一个表中获取一条记录
select * from students order by rand() limit 1;
-
日期时间函数
当前日期 current_date()
select current_date();当前时间 current_time()
select current_time();当前日期时间 now()
select now();-
日期格式化 date_format(date,format)
select date_format(current_date(),'%Y-%M');- 参数format可选值
%Y 获取年,返回完整年份 %y 获取年,返回简写年份 %m 获取月,返回月份 %d 获取日,返回天值 %H 获取时,返回24小时进制的小时数 %h 获取时,返回12小时进制的小时数 %i 获取分,返回分钟数 %s 获取秒,返回秒数
流程控制
- case语法:等值判断
- 说明:当值等于某个比较值的时候,对应的结果会被返回;如果所有的比较值都不相等则返回else的结果;如果没有else并且所有比较值都不相等则返回null
select case 1 when 1 then 'one' when 2 then 'two' else 'zero' end as result--根据性别判断该称呼为先生还是女士 select case sex when '男' then concat(left(name,1),'先生') when '女' then concat(left(name,1),'女士') else concat(left(name,1),'大侠') end as result from students;
自定义函数
-
创建自定义函数
- 语法:
--设置分隔符 delimiter $$ --创建函数 create function 参数名称 (参数列表) return 返回类型 begin sql语句 end $$ --还原分隔符 delimter ;- delimiter用于设置分隔符,分隔符就是告诉MySQL解释器,该段命令是否已结束,是否可执行。默认情况下,delimiter是分号
;。在命令行客户端中,如果有一行命令以分号结束,那么回车后,mysql将会执行该命令。 - 在“sql语句”编写部分的语句需要以分号结尾,此时回车会直接执行,所以要创建存储过程前需要指定其他符号作为分隔符,此处使用
$$,也可以使用其他字符。 - 最后要把delimter设置回来,
delimter ;
示例:
--函数功能:去掉字符串前面和后面的空格 DROP FUNCTION IF EXISTS my_trim; delimiter $$ create function my_trim(str varchar(100)) returns varchar(100) begin return ltrim(rtrim(str)); end; $$ delimiter ; 使用自定义函数
select my_trim(' ab d ');
存储过程
存储过程,也翻译为存储程序,是一条或多条SQL语句的集合
-
创建存储过程
- 语法
--设置分隔符 delimeter // --创建存储过程 create procedure 存储过程名称(参数列表) begin sql语句 end; // --还原分隔符 delimiter ;- 示例
drop procedure if exists pro_stu; delimiter // create procedure pro_stu() BEGIN select * from students; end; // delimiter ; -
调用存储过程
语法
call 存储过程(参数列表);示例
call pro_stu();存储过程和函数都是为了可重复执行操作数据库的sql语句的集合。
存储过程和函数都是经过一次编译,就会被缓存起来,下次使用就直接命中缓存中已经编译好的sql,不需要重复编译
减少网络交互,减少网络访问流量
视图
对于复杂的查询,在多个地方被使用,如果需求发生了改变,需要更改sql语句,则需要在多个地方进行修改,维护起来非常麻烦
解决:定义视图
视图本质就是对查询的封装
定义视图,建议以v_开头
create view 视图名称 as select语句;示例:创建视图,查询学生对应的成绩信息
create view v_stu_sco_cour as
select
stu.name,sco.courseNo,sco.score
from
students stu
inner join scores sco on stu.studentNo=sco.studentNo
inner join courses cour on sco.courseNo=cour.courseNo;
使用视图
select * from v_stu_sco_cour;show tables;也能展示出视图还有一个用处是可以利用视图把真正的表名和字段名隐藏起来
create view v_students as
select name 姓名,age 年龄 from students;
事务
为什么要有事务
事务广泛的运用于订单系统、银行系统等多种场景
例如:A用户和B用户是银行的储户,现在A要给B转账500元,那么需要做以下几件事:
1.检查A的账户余额>500元
2.A账户中扣除500元
3.B账户中增加500元正常的流程是:A账户扣了500元,B账户加了500,皆大欢喜。那如果A账户扣钱之后,系统出了故障呢?A白白损失500元,而B也没有得到本该属于它的500元。这个案例,隐藏一个前提条件:A的钱和B的钱,要么同时成功,要么同时失败。
所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如银行转账:从一个账号扣款并从另一个账号增款,这两个操作要么都执行,要么都不执行。所以,应该把他们看作一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
--开启事务
begin;
所有操作都成功了;
--提交
commit;
--开启事务
begin;
任意一步操作失败了;
--回滚
rollback;
- 示例
mysql> select * from students where name in('大乔','小乔');
+-----------+--------+------+----------+------+-------+--------------------+
| studentNo | name | sex | hometown | age | class | card |
+-----------+--------+------+----------+------+-------+--------------------+
| 005 | 大乔 | 女 | 天津 | 18 | 3班 | 340322199005242343 |
| 007 | 小乔 | 女 | 山西 | 20 | 2班 | 340322199007246789 |
+-----------+--------+------+----------+------+-------+--------------------+
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update students set age=age+3 where name='大乔';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update students set age=age-3 where name='小乔';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from students where name in('大乔','小乔');
+-----------+--------+------+----------+------+-------+--------------------+
| studentNo | name | sex | hometown | age | class | card |
+-----------+--------+------+----------+------+-------+--------------------+
| 005 | 大乔 | 女 | 天津 | 21 | 3班 | 340322199005242343 |
| 007 | 小乔 | 女 | 山西 | 17 | 2班 | 340322199007246789 |
+-----------+--------+------+----------+------+-------+--------------------+
2 rows in set (0.00 sec)
索引
一般应用系统对比数据库的读写比例在10:1左右,而且插入操作和更新操作很少出现性能问题,遇到最多的,也最容易引起问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重
当数据库中的数据量很大时,查找数据会变得特别慢
优化方案:索引
索引是作用在某个字段上的,where条件通过有索引的字段查询时,查询时间才会比较快。
-
示例
- 建测试数据
--建测试表 drop table if exists test_index; create table test_index( title varchar(10) default null ) --插入数据:通过excel造插入20000条数据的语句 insert into test_index values('test0'); insert into test_index values('test1'); …… insert into test_index values('test20000');开启运行时间监控
set profiling=1;查找第一万条数据 test10000
select * from test_index where title='test10000';查看执行时间
show profiles;//0.00880900s创建索引
create index title_index on test_index(title(10));创建索引后再次查找第一万条数据 test10000
select * from test_index where title='test10000';查看执行时间
show profiles//0.00276300
语法
查看索引
show index from 表名;-
创建索引
- 建表时创建索引
create table creat_index( id int primary key, name varchar(10) unique, age int, key (age) ); --会为primary key、unique自动创建索引,通过key(字段)也是创建索引。- 对已经存在的表,添加索引
如果指定字段是字符串,需要指定长度,建议长度与定义字段的长度一样
字段类型不是字符串,可以不填写长度部分
create index 索引名称 on 表名(字段名称(长度)); 例: create index age_index on create_index(age); create index name_index on create_index(name(10)); 删除索引
drop index 索引名称 on 表名;查询分析
explain
select * from test_index where title='test10000';
- 有索引时查询分析:

- 删除索引后查询分析:

说明:key-有值表示有使用到索引;rows-表示查询了多少行,不准确,但能反应出有索引查询的行数减少。
缺点
索引虽然大大提高了查询速度,同时却会降低更新表的速度,如对表进行update\insert\delete,因为更新表时,MySQL不仅要保存数据,还要保存以下索引文件
但是 ,在互联网应用中,查询语句远远大于增删改的语句,甚至可以占到80-90%,所以不用太在意,只是大量数据导入时,可以先删除索引,再批量插入数据,最后再添加索引。
外键 foreign key
如果一个实体的某个字段指向另一个实体的主键,就成为外键。被指向的实体,称之为主实体(主表),也叫父实体(父表)。负责指向的实体,称之为从实体(从表),也叫子实体(子表)
对关系字段进行约束,当为从表中的关系字段填写值时,会到关联的主表中查询此表的值是否存在,如果存在则填写成功,如果不存在则填写失败并报错。
语法
查看外键
show create table 表名;-
设置外键约束
- 创建数据表时设置外键约束
foreign key(自己的字段) reference 主表(主表字段);
create table class( id int unsigned primary key auto_increment, name varchar(10) ); create table stu( name varchar(10), class_id int unsigned, foreign key(class_id) reference class(id) );- 对于已经存在的表设置外键约束
alter table 从表名 add foreign key (从表字段) references 主表名(主表字段);
alter table stu add foreign key (class_id) references class(id); - 创建数据表时设置外键约束
删除外键
-- 需要先获取外键约束名称
show create table stu; --stu_ibfk_1
-- 获取名称之后就可以根据名称来删除外键约束
alter table 表名 drop foreign key 外键名称;
alter table stu drop foreign key stu_ibfk_1;
- 实际开发中很少使用外键约束,会极大降低表更新的效率。一般通过开发人员写代码来约束。
修改密码
- 使用root登录,修改mysql数据库的user表
- 使用password()函数进行密码加密
- 注意修改完后需刷新权限
use mysql;
--update user set authentication_string=password('新密码') where user='用户名';
--旧版本:update user set password=password('新密码') where user='用户名';
update user set authentication_string=password('123') where user='root';
--刷新权限
flush privileges;
忘记密码
- 配置mysql登录时不需要密码,修改配置文件
- centos中,配置文件位置/etc/my.cnf
- windows中,配置文件位置为安装目录..\MySQL Server 5.1\my.ini
找到mysqld,在它的下一行,添加skip-grant-tables
2.重启mysql,免密码登陆,修改mysql数据库的user表
use mysql;
--update user set authentication_string=password('新密码') where user='用户名';
--旧版本:update user set password=password('新密码') where user='用户名';
update user set authentication_string=password('123') where user='root';
--刷新权限
flush privileges;
3.改完之后,把配置文件改回去,删除skip-grant-tables,再重启mysql
mac忘记密码 实践有效
-
关闭mysql服务:
苹果->系统偏好设置->最下边点mysql 在弹出页面中 关闭mysql服务(点击stop mysql server)
进入终端输入:
cd /usr/local/mysql/bin/登录管理员权限:
sudo su输入以下命令来禁止mysql验证功能:
./mysqld_safe --skip-grant-tables &mysql会自动重启(偏好设置中mysql的状态会变成running)
输入命令
./mysql输入命令
FLUSH PRIVILEGES;输入命令
SET PASSWORD FOR ['root'@'localhost'](mailto:'%20rel=) = PASSWORD('你的新密码');