循环展开和粗化锁
我们先来回顾一下什么是循环展开。
循环展开就是说,像下面的循环遍历的例子:
for (int i = 0; i < 1000; i++) {
x += 0x51;
}
因为每次循环都需要做跳转操作,所以为了提升效率,上面的代码其实可以被优化为下面的:
for (int i = 0; i < 250; i++) {
x += 0x144; //0x51 * 4
}
注意上面我们使用的是16进制数字,至于为什么要使用16进制呢?这是为了方便我们在后面的assembly代码中快速找到他们。
好了,我们再在 x += 0x51 的外面加一层synchronized锁,看一下synchronized锁会不会随着loop unrolling展开的同时被粗化。
for (int i = 0; i < 1000; i++) {
synchronized (this) {
x += 0x51;
}
}
万事具备,只欠我们的运行代码了,这里我们还是使用JMH来执行。
相关代码如下:
@Warmup(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(value = 1,
jvmArgsPrepend = {
"-XX:-UseBiasedLocking",
"-XX:CompileCommand=print,com.flydean.LockOptimization::test"
}
)
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class LockOptimization {
int x;
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public void test() {
for (int i = 0; i < 1000; i++) {
synchronized (this) {
x += 0x51;
}
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(LockOptimization.class.getSimpleName())
.build();
new Runner(opt).run();
}
}
上面的代码中,我们取消了偏向锁的使用:-XX:-UseBiasedLocking。为啥要取消这个选项呢?因为如果在偏向锁的情况下,如果线程获得锁之后,在之后的执行过程中,如果没有其他的线程访问该锁,那么持有偏向锁的线程则不需要触发同步。
为了更好的理解synchronized的流程,这里我们将偏向锁禁用。
其他的都是我们之前讲过的JMH的常规操作。
接下来就是见证奇迹的时刻了。
分析Assembly日志
我们运行上面的程序,将会得到一系列的输出。因为本文并不是讲解Assembly语言的,所以本文只是大概的理解一下Assembly的使用,并不会详细的进行Assembly语言的介绍,如果有想深入了解Assembly的朋友,可以在文后留言。
分析Assembly的输出结果,我们可以看到结果分为C1-compiled nmethod和C2-compiled nmethod两部分。
先看C1-compiled nmethod:

第一行是monitorenter,表示进入锁的范围,后面还跟着对于的代码行数。
最后一行是monitorexit,表示退出锁的范围。
中间有个add $0x51,%eax操作,对于着我们的代码中的add操作。
可以看到C1—compiled nmethod中是没有进行Loop unrolling的。
我们再看看C2-compiled nmethod:
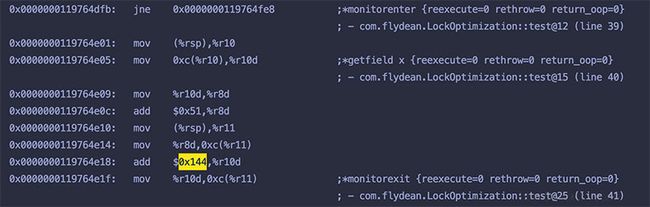
和C1很类似,不同的是add的值变成了0x144,说明进行了Loop unrolling,同时对应的锁范围也跟着进行了扩展。
最后看下运行结果:
Benchmark Mode Cnt Score Error Units
LockOptimization.test avgt 5 5601.819 ± 620.017 ns/op
得分还不错。
禁止Loop unrolling
接下来我们看下如果将Loop unrolling禁掉,会得到什么样的结果。
要禁止Loop unrolling,只需要设置-XX:LoopUnrollLimit=1即可。
我们再运行一下上面的程序:

可以看到C2-compiled nmethod中的数字变成了原本的0x51,说明并没有进行Loop unrolling。
再看看运行结果:
Benchmark Mode Cnt Score Error Units
LockOptimization.test avgt 5 20846.709 ± 3292.522 ns/op
可以看到运行时间基本是优化过后的4倍左右。说明Loop unrolling还是非常有用的。
以上就是详解Java编译优化之循环展开和粗化锁的详细内容,更多关于Java编译优化之循环展开和粗化锁的资料请关注脚本之家其它相关文章!