前言
最近接触到ROC曲线相关的问题,因此下面整理出相关的文章,记录相关原理和应用。
数据分析最让人着迷的一种用途是可以基于现有数据创建能够区分不同类型情景的机器学习预测模型。通过定义明确的模型,可以确定能够预测结果的最重要影响因素,为战略假设开发有价值的洞察力,甚至可以通过友好的用户界面将模型的逻辑实现到软件应用程序中。
首先,我们需要评估构建好的预测模型是否具有良好准确的预测能力!比如,如果我们的电子邮件程序的垃圾邮件分类器只能检测到50%的不需要的电子邮件或请求,我们都会非常愤怒。本文将讨论如何使用经典工具来评估预测模型:接收器操作特性(ROC)曲线。
本文主要分为三个部分整理ROC曲线相关内容,可根据自己的需要进行挑选:
1、使用ROC曲线分析的相关文献实例
2、ROC曲线的原理和历史
3、如何绘制ROC曲线
使用ROC曲线分析的相关文献实例
从一篇SCI出发:Improvement of Insulin Sensitivity after Lean Donor Feces in Metabolic Syndrome Is Driven by Baseline Intestinal Microbiota Composition
这是阿姆斯特丹大学学术医学中心在2017年发表在cell子刊上的文献,其中一个highlight提到:Response to lean donor FMT is driven by baseline fecal microbiota composition,使用了ROC曲线来评估预测模型的好坏。
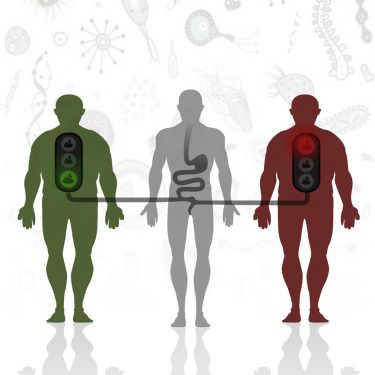
为了比较异体FMT中菌群与效果之间的关系,首先按照FMT前后Rd值的变化将患者分为responders组和non-responders组,并比较了两组的菌群差异,从菌群多样性变化来看,基于Shannon指数发现,两组的多样性均没有发生显著改变,然而,两组基线时的菌群多样性却又显著差异(图5A),具体表现为non-responders的基线菌群多样性显著高于responders。随后,作者使用了弹性网络算法elastic net algorithm (Zou and Hastie, 2005)区分responders和non-responders,为了避免过度拟合,在数据的训练分区(80%)上使用了十折交叉验证,剩下的20%样品用作测试数据集。要选择的参数是 L1,L2范数和正则化阈值之间的比率。稳定性选择采用80% 的随机二次抽样方法进行,共100次。在稳定性选择过程中,计算所有权重系数为非零的特征。这些计数被归一化并转换为稳定系数,对于总是被选择的特征值在1.0之间,对于从未被选择的特征值在0.0之间。通过随机试验评价弹性网络算法所得结果的统计有效性。按照程序将结果变量(例如,同种异体相对于自体或应答者相对于无应答者)随机重组,同时保留相应的微生物谱。重复100次,每次计算受试者-工作特征-曲线下面积(ROC AUC)评分。用于二进制分类任务的性能度量是 ROC AUC。ROC 可以理解为一个正确分类同种异体受试者与自体受试者或有效者与无效者的概率图。数据集中的交叉验证是通过随机隐藏模型中20% 的受试者并评估该组的预测质量来完成的。ROC AUC 评分用0.5 AUC 来衡量分类模型的预测准确性,对应于一个随机结果。定义了一个临界值0.05,并将原始数据集的真实 AUC 与此值进行了比较。
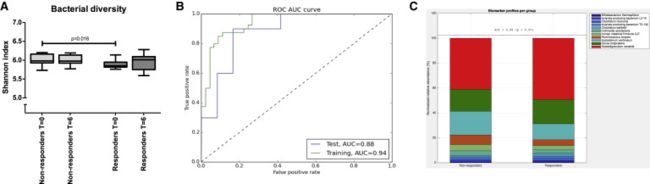
作者通过ROC曲线评估了基线菌群组成预测6周代谢反应的模型,显示AUC=0.88,模型良好。
从这篇文献了解到ROC曲线可用于评估某个寻找biomarkers的预测模型的好坏。
再从一篇SCI了解:Alterations in the gut microbiome and metabolism with coronary artery disease severity
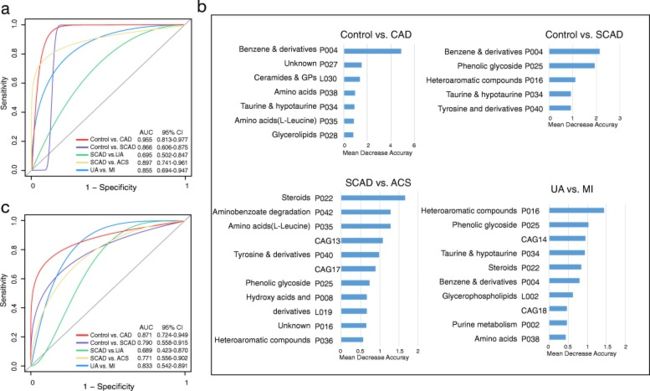
这是一篇本课题组与北京协和医学院合作在2019年发表的文章,关注了不同冠状动脉疾病Coronary artery disease (CAD)类型患者的肠道菌群区分差异。其中,作者通过ROC曲线评估了区分不同CAD亚型(稳定型冠状动脉疾病(SCAD) ,不稳定型心绞痛(UA)和心肌梗死(MI))的特征共变化菌群和代谢物随机森林模型,得到比较良好的预测结果。
Subgroup identification and prediction based on CAGs and CAD-associated metabotypes
为了确定肠道菌群中的 CAGs 和代谢产物模块是否可以作为鉴别冠心病不同阶段与正常冠状动脉的生物标志物,根据24个 CAGs 和72个血清代谢类型构建了随机森林模型对冠心病不同阶段进行分类,并利用 ROC曲线(ROC)曲线对分类进行了检验(详情见“材料和方法”一节)。总共构建了5个预测模型(Control vs. CAD, Control vs. SCAD, SCAD vs. UA, SCAD vs. ACS和UA vs. MI)。
随后,作者再通过招募新队列使用该模型进行分类预测,进一步论证该疾病亚型识别模型的潜在分类能力。
小结:从这两篇文献来看,作者均通过某个分类法机器学习预测模型寻找biomarkers,然后使用ROC曲线对模型进行评估。因此,我们可以初步得知,ROC曲线是用于检验构建的预测模型好坏的一种衡量方法。那么除了这种用途,ROC曲线还能做什么呢?
为了进一步了解并应用ROC曲线,我们需要首先了解ROC曲线的原理和过往↓
ROC曲线的原理和历史
关于ROC曲线相关介绍的文章非常多,这里我摘抄出个人认为比较详细,可用性强的文章,加以理解。
一、评估预测模型的方法
首先,我们应该了解到预测模型的类型可以分为回归模型和分类模型(分类模型又有两类算法:分类输出型和概率输出型,这里就不一一赘述),而不同模型的评估度量也是不同的,如何评估模型好坏,机器学习(二十四)——常见模型评估方法,分类模型的评估方法简介首先需要了解自己构建的预测模型类型来决定评估方法,并不局限于使用ROC曲线进行评估。
ROC曲线原理:
关于ROC曲线的概念和意义可参考:ROC曲线的概念和意义
英文比较好的话也可以看看这篇:ROC curves – what are they and how are they used?
为了更直观的理解ROC,也可以看看这个视频:ROC and AUC, Clearly Explained!
受试者工作特征曲线(receiver operator characteristic curve, ROC曲线),最初用于评价雷达性能,又称为接收者操作特性曲线。ROC曲线其实就是从混淆矩阵衍生出来的图形,以真阳性率(灵敏度,Sensitivity)为纵坐标,假阳性率(1-特异度,1-Specificity)为横坐标绘制的曲线。
其自变量(检验项目)一般为连续性变量(如蛋白质因子、菌株、代谢物等的检测丰度或含量),因变量(金标准,如某疾病亚型分类、治疗响应和无响应、患病和未患病)一般为二分类变量。
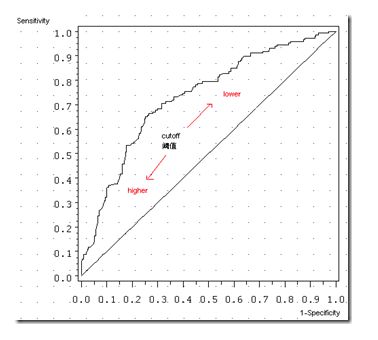
ROC曲线图形:随着阈值的减小,更多的值归于正类,敏感度和1-特异度也相应增加,所以ROC曲线呈递增趋势。那条45度对角线是一条参照线,也就是说ROC曲线要与这条曲线比较。简单的说,如果我们不用模型,直接随机把客户分类,我们得到的曲线就是那条参照线,然而我们使用了模型进行预测,就应该比随机的要好,所以ROC曲线要尽量远离参照线,越远,我们的模型预测效果越好。
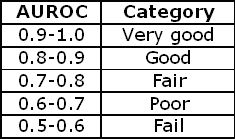
ROC曲线就是用来判断诊断的正确性,最理想的就是曲线下的面积为1,比较理想的状态就是曲线下的面积在0.8-0.9之间,0.5的话对实验结果没有什么影响。
提到ROC曲线,就离不开AUC(ROC曲线下面积),其判定方法为AUC应该大于0.5。ROC曲线是根据与对角线进行比较来判断模型的好坏,但这只是一种直觉上的定性分析,如果我们需要精确一些,就要用到AUC,也就是ROC曲线下面积(AUC)。
从AUC判断分类器(预测模型)优劣的标准:
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
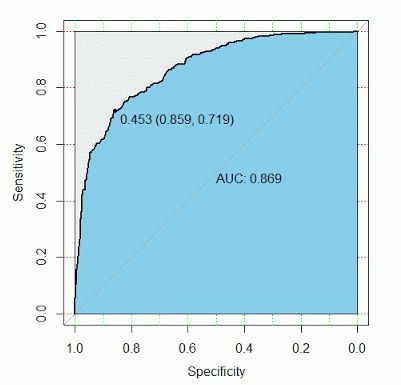
看上图,参考线的面积是0.5,ROC曲线与它偏离越大,ROC曲线就越往左上方靠拢,它下面的面积(AUC)也就越大,这里面积是0.869。我们可以根据AUC的值与0.5相比,来评估一个分类模型的预测效果。
二、ROC曲线的历史和关键值
这里推荐阅读这篇:机器学习基础(1)- ROC曲线理解。这里从最初雷达兵使用ROC曲线评估的故事说起,言简意赅。
ROC曲线最初的研究是为了确定美国雷达“接收机操作员”是如何漏掉日本飞机的。在模型预测判断中,会出现真阳、假阳、真阴和假阴的三种情况,而不同雷达兵都可能有自己的一套评判标准,对每个接收的信号是大鸟还是轰炸机,每个雷达兵会给出自己的判断结果,这样每个雷达兵就都能计算出一个ROC曲线上的关键点(一组FPR,TPR值),把大家的点连起来,也就是最早的ROC曲线了。
ROC曲线需要了解几个关键值:
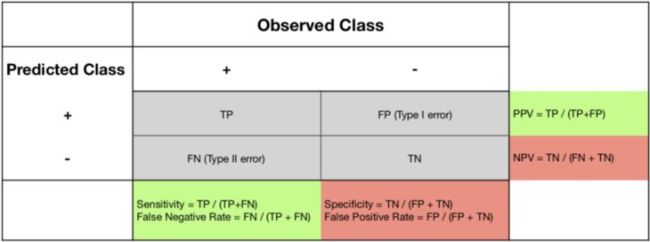
敏感性:正确识别真阳性的比例。在这种情况下,健康患者的比例由诊断工具正确识别。这有时被称为“召回”。
SN =真阳性/(真阳性+假阴性)
逆(1灵敏度)= 假负率。未被该工具检测到的健康患者被错误地识别为患有CAD。假阴性也称为II型错误。
特异性:正确识别真阴性的比例。在这种情况下,通过诊断工具正确识别CAD患者的比例。
SP =真阴性/(真阴性+误报)
逆(1-特异性)= 假阳性率。CAD患者被错误地识别为无CAD。误报也称为I型错误。
积极预测价值:该工具报告的阳性比例,实际上是积极的。对于诊断工具报告缺乏CAD的患者组,PPV是实际上没有患病的患者的比例。这有时被称为“精确度”。
PPV =真阳性/(真阳性+误报)
负面预测值:该工具报告的负面影响的比例,实际上是负面的。对于诊断工具报告存在CAD的患者组,NPV是实际上没有CAD的患者的比例。
NPV =真阴性/(真阴性+假阴性)
这里可以借助混淆矩阵加以理解:
TP(True Positive): 真实为0,预测也为0
FN(False Negative): 真实为0,预测为1
FP(False Positive): 真实为1,预测为0
TN(True Negative): 真实为0,预测也为0
三、ROC曲线的主要作用
1、ROC曲线能很容易地查出任意界限值时的对疾病的识别能力。
2、选择最佳的诊断界限值。
3、两种或两种以上不同诊断试验对疾病识别能力的比较。在对同一种疾病的两种或两种以上诊断方法进行比较时,可将各试验的ROC曲线绘制到同一坐标中,以直观地鉴别优劣,靠近左上角的ROC曲线所代表的受试者工作最准确。亦可通过分别计算各个试验的ROC曲线下的面积(AUC)进行比较,哪一种试验的AUC最大,则哪一种试验的诊断价值最佳。
四、交叉验证和过拟合问题
参考:你真的了解交叉验证和过拟合吗?
机器学习】Cross-Validation(交叉验证)详解
10折交叉验证(10-fold Cross Validation)与留一法(Leave-One-Out)、分层采样(Stratification)
意识到过拟合好像也是个棘手的问题,所以在这里补充一下:
简单来讲,当 train set 误差较小,而 test set 误差较大时,我们即可认为模型过拟合。这句话表达的另一层意思是,模型评估指标的方差(variance)较大,即可认为模型过拟合。另外,无论监督学习还是非监督学习,均存在过拟合的问题。
有一个比喻还不错,这里也摘抄下来:
语文老师 让同学A 解释一个句子: ‘某鲁迅先生的文章~~~~~~~~’
欠拟合: 差生: 这是个什么鬼东西,比例哔哩哔哩~~~~
过拟合: 语文老师的解释: ‘表面上看是~~~,但其实~~~~,本质上~~~~~~,反映了~~~~心情,烘托了~~~气氛~~~’
正常: 当时鲁迅先生觉得天色晚了,该休息了。
那么,如何才能够在一定程度上避免过拟合呢?这就引出了交叉验证:
最简单的判断模型是否过拟合的方法,就是通过training accuracy 和 test accuracy 数值大小,直观的判断模型是否过拟合。例如,训练集的准确率为90%,而测试集的准确率为70%,那么我们可以认为模型过拟合。不过,这种方法没有明确的判断标准,完全靠个人的主观判断——“感觉训练和测试的误差相差有点大,有可能过拟合”。
如何利用交叉验证避免过拟合?
避免模型过拟合的方法,总结大概以下几点:
- 重新清洗数据(删除稀疏特征、对噪声数据进行处理(删除/替换))
- 重新采样(改变采样方法等)
- 增加训练数据
- 采用交叉验证训练模型
- 重新筛选特征
- 降低模型复杂度(增加正则项:L1,L2)
- dropout(神经网络中,让神经元一定的概率不工作)
这里探讨如何利用交叉验证来避免模型过拟合:
第一个作用是对模型的性能进行评估。当我们通过一次划分样本对模型进行训练和测试时,由于样本划分的偶然性,会导致我们对模型的评估不准确。因此,可以采用交叉验证对模型进行评估(一般采用5折或10折,sklearn默认采用的是3折),以 n 折交叉验证结果的均值,作为模型的性能评估。
第二个作用就是用来避免过拟合。例如当我们进行10折交叉验证时,训练了10次,得到了10个模型,每个模型的参数也是不同的,那么我们究竟用哪个模型作为我们最终的模型呢?答案是:一个都不用!我们要利用全量数据重新训练出一个最终模型!
ROC曲线的绘制方法
关于实现ROC曲线的绘制,可通过多种途径进行,这里列出一些可操作平台和方法:
1、SPSS:如何用SPSS做ROC曲线分析?看这1篇就够了!
2、R语言:R语言逻辑回归、ROC曲线和十折交叉验证
ROC曲线基于R语言-(pROC包)
R语言pROC包绘制ROC曲线
3、Python:机器学习基础(1)- ROC曲线理解
ROC原理介绍及利用python实现二分类和多分类的ROC曲线
4、Matlab:Matlab绘图——ROC曲线绘制(官方demo)
ROC曲线详解及matlab绘图实例
小结
ROC曲线的初步学习就到这里,我们初步了解到ROC曲线最初是用来评估雷达兵判断的轰炸机信号准确性的方法,随后沿用到了医学指标的判定上,在生活中应用广泛。ROC曲线可用于查出任意界限值时的对疾病的识别能力,选择最佳的诊断界限值,还可以用在评估机器学习预测模型的好坏上(目前好像这方面用的比较多)。当然,还有一些问题值得讨论,比如,何时需要使用ROC曲线,S折交叉验证平均ROC曲线如何绘制,等等。在机器学习模型构建过程中,训练集和测试集的建立,模型的交叉验证和ROC曲线评估的结合,还需要继续学习。
参考文献
Kootte RS, Levin E, Salojärvi J, Smits LP, Hartstra AV, Udayappan SD, Hermes G, Bouter KE, Koopen AM, Holst JJ, Knop FK, Blaak EE, Zhao J, Smidt H, Harms AC, Hankemeijer T, Bergman JJGHM, Romijn HA, Schaap FG, Olde Damink SWM, Ackermans MT, Dallinga-Thie GM, Zoetendal E, de Vos WM, Serlie MJ, Stroes ESG, Groen AK, Nieuwdorp M. Improvement of Insulin Sensitivity after Lean Donor Feces in Metabolic Syndrome Is Driven by Baseline Intestinal Microbiota Composition. Cell Metab. 2017 Oct 3;26(4):611-619.e6. doi: 10.1016/j.cmet.2017.09.008. PMID: 28978426.
Liu H, Chen X, Hu X, Niu H, Tian R, Wang H, Pang H, Jiang L, Qiu B, Chen X, Zhang Y, Ma Y, Tang S, Li H, Feng S, Zhang S, Zhang C. Alterations in the gut microbiome and metabolism with coronary artery disease severity. Microbiome. 2019 Apr 26;7(1):68. doi: 10.1186/s40168-019-0683-9. PMID: 31027508; PMCID: PMC6486680.
Rodriguez-Ruiz A, Lång K, Gubern-Merida A, Broeders M, Gennaro G, Clauser P, Helbich TH, Chevalier M, Tan T, Mertelmeier T, Wallis MG, Andersson I, Zackrisson S, Mann RM, Sechopoulos I. Stand-Alone Artificial Intelligence for Breast Cancer Detection in Mammography: Comparison With 101 Radiologists. J Natl Cancer Inst. 2019 Sep 1;111(9):916-922. doi: 10.1093/jnci/djy222. PMID: 30834436; PMCID: PMC6748773.
Duclos G, Bobbia X, Markarian T, Muller L, Cheyssac C, Castillon S, Resseguier N, Boussuges A, Volpicelli G, Leone M, Zieleskiewicz L. Speckle tracking quantification of lung sliding for the diagnosis of pneumothorax: a multicentric observational study. Intensive Care Med. 2019 Sep;45(9):1212-1218. doi: 10.1007/s00134-019-05710-1. Epub 2019 Jul 29. PMID: 31359081.