原文链接:http://tecdat.cn/?p=5673
原文出处:拓端数据部落公众号
《第_二十二_条军规》是美国作家约瑟夫·海勒创作的长篇小说,该小说以第二次世界大战为背景,通过对驻扎在地中海一个名叫皮亚诺扎岛(此岛为作者所虚构)上的美国空军飞行大队所发生的一系列事件的描写,揭示了一个非理性的、无秩序的、梦魇似的荒诞世界。我喜欢整本书中语言的创造性使用和荒谬人物的互动。本文对该小说进行文本挖掘和可视化。
数据集
该文有大约175,000个单词,分为42章。我在网上找到了这本书的原始文本版本。
我使用正则表达式和简单字符串匹配的组合在Python中解析文本。
我shiny在R中以交互方式可视化这些数据集。
地理图
geo<- catch22\[( geo$Time > chapters\[1\]) & ( geo$Time < (chapters\[2\] + 1)),\]
paths_sub <- paths\[( paths$time > chapters\[1\]) & ( paths$time < (chapters\[2\] + 1)),\]
# 绘图
p <- ggplot() + borders("world", colour="black", fill="lightyellow") +
ylab(NULL) + xlab(NULL) +
# 仅在有条件的情况下尝试绘制位置和路径
if (nrow( geo_sub) != 0) {
p + geom\_point(data= geo\_sub, aes(x = Lon, y = Lat), size=3, colour='red') +
geom\_point(data= paths\_sub\[1,\], aes(x = lon, y = lat), size=3, colour='red') +
geom\_path(data= paths\_sub, aes(x = lon, y = lat, alpha=alpha), size=.7,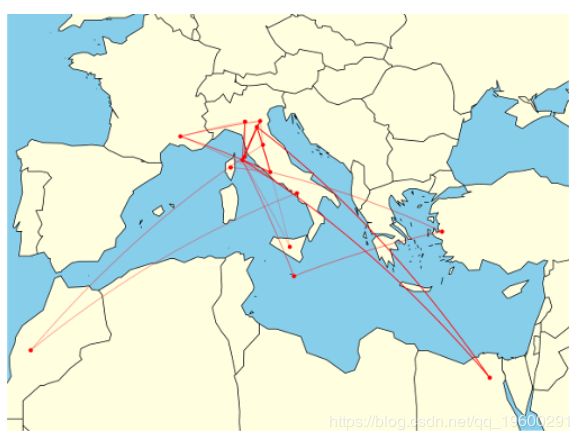
可视化映射了整本书中提到的地中海周围位置。
人物章节关系
ggplot(catch22, aes(x=Chapter, y=Character, colour=cols)) +
geom_point(size=size, shape='|', alpha=0.8) +
scale\_x\_continuous(limits=c(chapters\[1\],(chapters\[2\] + 1)), expand=c(0,0), breaks=(1:42)+0.5, labels=labs) +
ylab(NULL) + xlab('Chapter') +
theme(axis.text.x = element_text(colour = "black", angle = 45, hjust = 1, vjust=1.03),
axis.text.y = element_text(colour = "black"),
axis.title.x = element_text(vjust=5),
plot.title = element_text(vjust=1)) +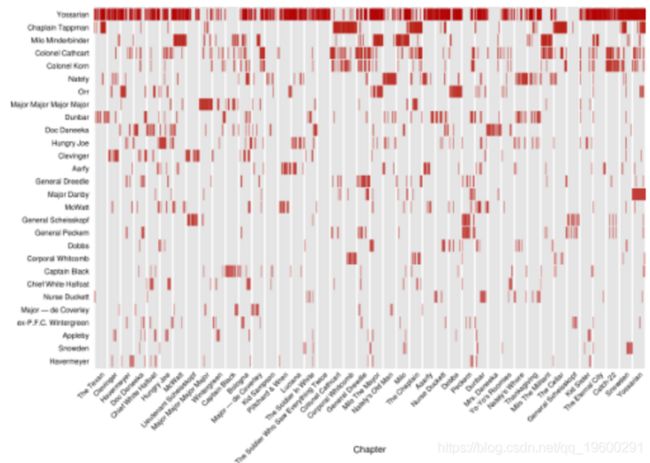
该图基本上代表了书中提到不同人物的序列。
我将数据绘制为标准散点图,章节为x轴(因为它与时间相似),人物为离散y轴。
人物共现矩阵
ggplot(coloca, aes(x=Character, y=variable, alpha=alpha)) +
geom_tile(aes(fill=factor(cluster)), colour='white') +
ylab(NULL) + xlab(NULL) +
theme(axis.text.x = element_text(colour = "black", angle = 45, hjust = 1, vjust=1.03),
axis.text.y = element_text(colour = "black"),
axis.ticks.y = element_blank(),
axis.ticks.x = element_blank(),
panel.grid.minor = element_line(colour = "white", size = 1),
panel.grid.major = element_blank()) +
scale\_fill\_manual(values = cols, guide = FALSE) +
scale\_alpha\_continuous(guide = FALSE)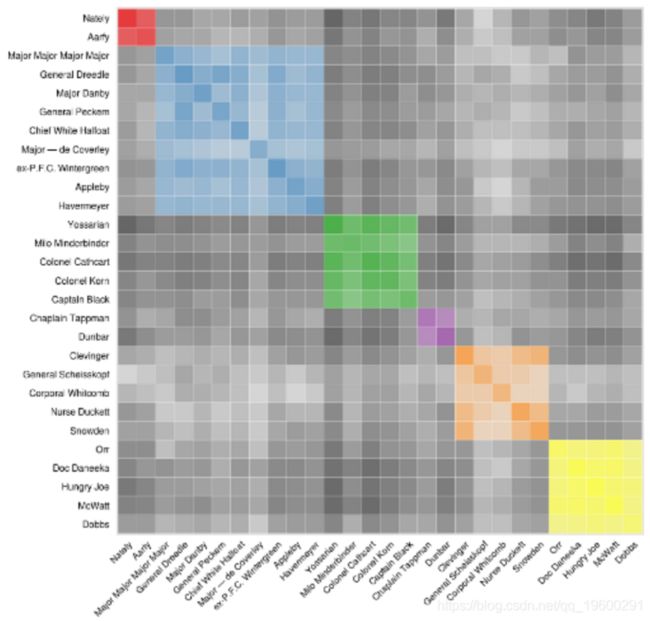
用于构建此可视化的数据与前一个中使用的数据完全相同,但需要进行大量的转换。
聚类为此图添加了另一个维度。在整本书上应用层次聚类,以尝试在角色中找到社群。使用AGNES算法对字符进行聚类。对不同聚类方案进行人工检查发现最优聚类,因为更频繁出现的角色占主导地位最少。这是六个簇的树形图:
ag <- agnes(cat2\[,-1\], method="complete", stand=F)
# 从树状图中切出聚类
cluster <- cutree(ag, k=clusters)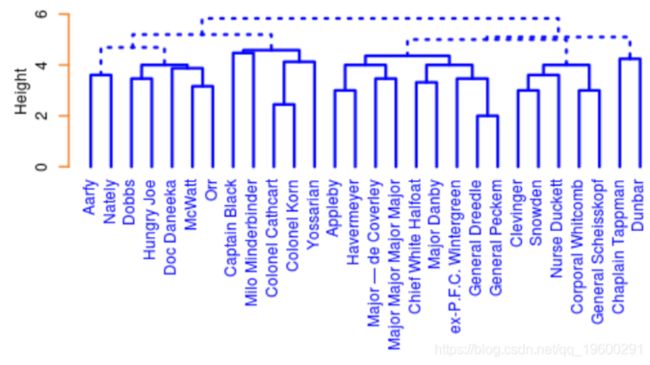
应该注意,聚类是在整个文本上执行的,而不是章节。按聚类排序会将角色带入紧密的社区,让观众也可以看到角色之间的某些交互。
特色词
ggplot( pos2, aes(Chapter, normed, colour=Word, fill=Word)) +
scale\_color\_brewer(type='qual', palette='Set1', guide = FALSE) +
scale\_fill\_brewer(type='qual', palette='Set1') +
scale\_y\_continuous(limits=c(0,y_max), expand=c(0,0)) +
ylab('Relative Word Frequency') + xlab('Chapter') +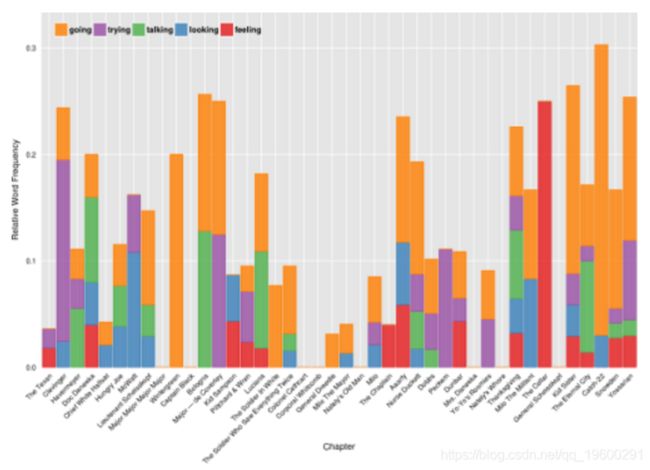
堆叠条形图更好地显示了单词所在的章节。
结论
我在这个过程中学到了很多东西,无论是在使用方面,还是在shiny。
