Jetpack 系列之AppSearch
前言
在今年的Google I/O 大会上,Jetpack库新增了三个组件(刚发布Alpha版本),分别是MarcrobenChmark、AppSearch和Google Shortcuts,MarcrobenChmark组件是用来衡量代码性能一个库,Google Shortcuts听起来像是一种快捷方式,本文我们将着重带领大家领略一下AppSearch的使用。那么什么是AppSearch呢?
什么是AppSearch
按照官方描述,AppSearch 是一个搜索库,用于管理本地存储的结构化数据,其中包含用于将数据编入索引和通过全文内搜索来检索数据的 API。您可以使用此库来为用户构建自定义的应用内搜索功能。看到应用内搜索,我首先想到了Android设置中的搜索页面,比如我们搜索显示两个字,这里将显示出所有包含“显示”字样的功能入口,如图1所示:

图1 设置内搜索
接下来我们来详细看如何使用AppSearch以及我踩过的那些坑。
引入相关库
首先我们在build.gradle中引入AppSearch组件的相关库,代码如下所示:
def appsearch_version = "1.0.0-alpha01"
implementation("androidx.appsearch:appsearch:$appsearch_version")
kapt("androidx.appsearch:appsearch-compiler:$appsearch_version")
implementation("androidx.appsearch:appsearch-local-storage:$appsearch_version")在 AppSearch 中,一个数据单元被表示为一个文档。 AppSearch 数据库中的每个文档都由其命名空间和 ID 唯一标识。 命名空间用于将来自不同来源的数据分开,这一点相当于sql中的表。所以接下来我们来创建一个数据单元。
创建一个数据单元
我们以新闻类为例,创建的数据类如下所示:
@Document
data class News(
@Document.Namespace
val namespace: String,
@Document.Id
val id: String,
@Document.StringProperty(indexingType = AppSearchSchema.StringPropertyConfig.INDEXING_TYPE_PREFIXES)
val newsTitle: String,
@Document.StringProperty(indexingType = AppSearchSchema.StringPropertyConfig.INDEXING_TYPE_PREFIXES)
val newsContent: String
)首先在AppSearch中所有的数据单元都要使用@Document注解,namespace和id在上面说了是数据类型的必须字段,newsTitle和newsContent是我们自己定义的新闻标题和新闻内容字段,这里提一下
@Document.StringProperty(indexingType = AppSearchSchema.StringPropertyConfig.INDEXING_TYPE_PREFIXES)这个注解,@Document.StringProperty 就是要将字符串类型的变量配置成AppSearch的属性,如果是整型那就是
@Document.Int64Property布尔类型就是
@Document.BooleanProperty等等等等,indexingType 属性值可以理解为匹配方式,这里设置为INDEXING_TYPE_PREFIXES,如当匹配条件是Huang的时候 可以匹配到HuangLinqing,其他属性感兴趣的可以看下源码androidx.appsearch.app.AppSearchSchema类。创建完数据类之后,同其他数据库操作一样,接下来来创建一个数据库。
创建数据库
创建数据库就会返回给我们一个ListenableFuture,用于整个数据库的操作,代码如下所示:
val context: Context = applicationContext
val sessionFuture = LocalStorage.createSearchSession(
LocalStorage.SearchContext.Builder(context, /*databaseName=*/"news")
.build()
)此时我们可以看到这行代码报了一个错误,错误如下所示:

大致意思是说还需要依赖一个库,说实话,其实AppSearch库完全可以自己依赖一下,这样对开发者方便很多,但是毕竟AppSearch刚出测试版,要求不能太高。
我们在build.gradle中引入guava库,代码如下所示:
implementation("com.google.guava:guava:30.1.1-android")依赖之后,上述代码就可以正常运行了,不过运行的话这里还不行,我们设置java1.8的环境才可以,否则后面运行会出现java.lang.NoSuchMethodError: No static method metafactory的错误
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
// For Kotlin projects
kotlinOptions {
jvmTarget = "1.8"
}原问题我提给了Google,可参看https://issuetracker.google.com/issues/191389033
设置数据模式
AppSearch中有Schema 和schema types的概念,意思是模式和模式类型,模式由表示独特数据类型的模式类型组成这里指的就是News类,模式类型由包含名称、数据类型和基数的属性组成。这里设置数据模式,其实就是指定我们可以在这个名称为“news”的数据空中可以添加什么样类型的数据。
val setChemaRequest = SetSchemaRequest
.Builder()
.addDocumentClasses(News::class.java).build()
var setSchemaFuture = Futures.transformAsync(
sessionFuture,
AsyncFunction {
it?.setSchema(setChemaRequest)
},
mainExecutor
) 首先我们创建了一个数据类型为News类的模式类,然后通过AppSearchSession的setSchema方法为数据文档设置了数据模式,这里大家疑惑的地方可能是Futures.transformAsync这个方法,其实很简单,Future就是一个Java中的异步线程框架,可以类比为协程,所以说如果AppSearch的设计可以不依赖Future在使用上可能会简单许多。
不过令我差异的是,我咨询了若干做Java的朋友,他们都表示,这个东西很少用。所以这里咱们只专注AppSearch的使用,Futures相关类的使用,感兴趣的可以深入学习下。
设置好数据模式后,我们就可以写入数据了。
写入数据
我们首先定义一个要插入的数据类,如下所示:
val new1 = News(
namespace = "new1",
id = "new_id_2",
newsTitle = "who is a boy",
newsContent = "Everyone, guess who is the handsome boy"
)构建PutDocumentsRequest对象并执行
val putRequest = PutDocumentsRequest.Builder().addDocuments(new1).build()
val putFuture = Futures.transformAsync(
sessionFuture,
AsyncFunction?> {
it?.put(putRequest)
},
mainExecutor
) 执行结果我们可以通过Futures.addCallback来监听,方法如下所示:
Futures.addCallback(
putFuture,
object : FutureCallback?> {
override fun onSuccess(result: AppSearchBatchResult?) {
// Gets map of successful results from Id to Void
val successfulResults = result?.successes
// Gets map of failed results from Id to AppSearchResult
val failedResults = result?.failures
Log.d(TAG, "成功:" + successfulResults.toString())
Log.d(TAG, "失败:" + failedResults.toString())
}
override fun onFailure(t: Throwable) {
Log.d(TAG, t.message.toString())
}
},
mainExecutor
) 运行,程序打印如下所示:
com.lonbon.appsearchdemo D/MainActivity: 成功:{new_id_1=null}
com.lonbon.appsearchdemo D/MainActivity: 失败:{}
说明存储成功了,接下来我们再插入一条数据,插入代码一致,就不重复展示了,数据如下所示:
val news2 = News(
namespace = "new1",
id = "new_id_1",
newsTitle = "Huang Linqing is handsome a boy",
newsContent = "Huang Linqing is an Android development engineer working in Hefei"
)查询数据
查询数据首先我们要指定查询的范围要就是namespace,相当于指定数据表,毕竟不同表中可能存在相同符合条件的数据。
val searchSpec = SearchSpec.Builder()
.addFilterNamespaces("new1")
.build()然后执行查询操作,我们这里查询的关键字是”handsome“
val searchFuture = Futures.transform(
sessionFuture,
Function {
it?.search("handsome", searchSpec)
},
mainExecutor
) 同样的我们使用addCallback方法来检测查询结果,代码如下所示:
Futures.addCallback(
searchFuture,
object : FutureCallback {
override fun onSuccess(result: SearchResults?) {
iterateSearchResults(result)
}
override fun onFailure(t: Throwable) {
Log.d(
TAG, "查询失败:" + t
.message
)
}
},
mainExecutor
) 查询成功会返回SearchResults类,我们需要遍历这个实例取出所有数据打印出来,即iterateSearchResults方法,代码如下所示:
private fun iterateSearchResults(searchResults: SearchResults?) {
Futures.transform(searchResults?.nextPage, Function, Any> {
it?.let {
it.forEach { searchResult ->
val genericDocument: GenericDocument = searchResult.genericDocument
val schemaType = genericDocument.schemaType
if (schemaType == "News") {
try {
var note = genericDocument.toDocumentClass(News::class.java)
Log.d(
TAG,
"查询结果:新闻标题-" + note.newsTitle
)
Log.d(
TAG,
"查询结果:新闻内容-" + note.newsContent
)
} catch (e: AppSearchException) {
Log.e(
TAG,
"Failed to convert GenericDocument to Note",
e
)
}
}
}
}
}, mainExecutor)
} 查询出来的结果是一个集合,所以我们需要遍历集合,并且数据类型需要是News类才可以继续下一步,这里我们将符合条件查询的新闻标题打印出来,结果如下所示:
D/MainActivity: 查询结果:新闻标题-who is a boy
.appsearchdemo D/MainActivity: 查询结果:新闻内容-Everyone, guess who is the handsome boy
.appsearchdemo D/MainActivity: 查询结果:新闻标题-Huang Linqing is a handsome boy
.appsearchdemo D/MainActivity: 查询结果:新闻内容-Huang Linqing is an Android development engineer working
这里我们可以看到我们查询的关键字是handsome的时候将两个结果都打印出来了,而第一条结果是新闻标题包含handsome关键字,第二条结果是新闻内容包含关键字,如果我们使用普通的sql,大概需要这么做
select * from table where newsTitle like %key% or newsContent like %key%
而使用AppSearch 不需要关心具体匹配的是哪个字段,只要任一字段包含相关内容,就将结果显示出来,有点像百度搜索时,我们可以看到有些关键字是在标题中有些关键字是在内容中而这些内容都可以很快的查询出来。
我为什么夸自己
这里我们搜索的关键字是handsome,新闻标题是 Huang Linqing is a handsome boy,黄林晴是个帅气的男孩,这里我并不是故意夸我自己的,而是在学习AppSearch的使用时,我发现了一个bug,那就是上面的代码如果插入的是中文,在搜索时将不会得到任何结果,昨天晚上发现这个问题后我将此问题提给了Google
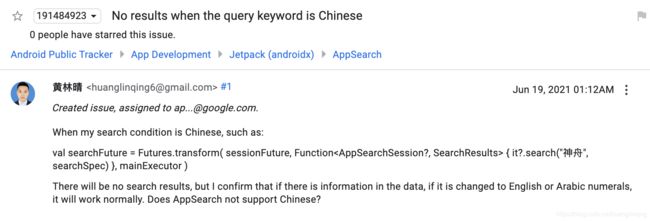
Google 也很快给了答复
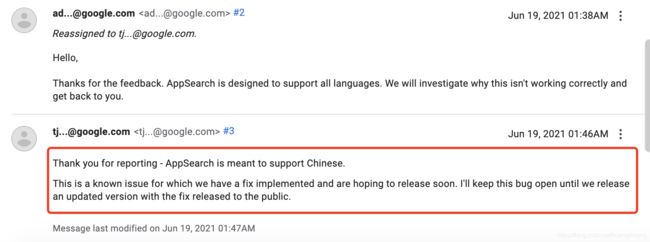
不支持中文搜索,这是一个已知问题,并且Google将在新版本中修复,会尽快发布版本,所以我们在新版本发布前知道有这个问题就行了,避免无效检查自己的代码问题。
删除数据
删除数据时我们需指定命名空间和数据id,构建一个删除数据的请求,代码如下所示:
val deleteRequest = RemoveByDocumentIdRequest.Builder("new1")
.addIds("new_id_2")
.build()val removeFuture = Futures.transformAsync(
sessionFuture, AsyncFunction {
it?.remove(deleteRequest)
},
mainExecutor
)到这里,我们也看出来了,其实Appsearch的使用,对数据的操作都是先构建一个请求,然后使用Futures去执行,如果需要检测结果的话,就通过Futures.addCallback添加一个回调即可,这里执行删除操作后,我们再次通过关键字”handsome“去查询,会发现就只有一条数据显示出来了,这里执行结果就不在展示了。
关闭会话
在开始使用的使用,我们创建了一个
ListenableFuture
val closeFuture = Futures.transform(
sessionFuture,
Function {
it?.close()
}, mainExecutor
) 小结
AppSearch是Jetpack最新推出的组件,AppSearch 是一个搜索库,可以很方便的来实现应用内的搜索功能,AppSearch的 I/O 使用很低,与 SQLite 相比,AppSearch 可能会更高效。但目前个人还是认为针对的问题不同和解决问题的角度不同,和其他数据库没有可比性,选择合适的方案最重要。