基于用户的协同过滤推荐算法WEB版代码实现(包含输出用户-评分矩阵模型、用户间相似度、最近邻居、推荐结果、平均绝对误差MAE、查准率、召回率)
一、开发工具及使用技术
MyEclipse10、jdk1.7、mahout API、movielens数据集。
二、实现过程
1、定义用户-电影评分矩阵:
/**
*用户-电影评分矩阵工具类
*/
public class DataModelUtil {
//定义用户-电影评分矩阵
private static DataModel model = null;
//初始化数据
static{
try {
//找到用户-电影评分文件
// File file = newFile(Constant.dataPath+Constant.rateFile);
// model = new FileDataModel(file);//实例化数据源
//jar包中的文件必须改成文件流进行操作,而且数据文件必须放在src文件夹下
InputStream inputStream = DataModelUtil.class.getClassLoader().
getResourceAsStream(Constant.dataPath+Constant.rateFile);
File file =new File("d://"+Constant.rateFile);
if (!file.exists())
file.createNewFile();
OutputStream outputStream =new FileOutputStream(file);
int bytesRead = 0;
byte[] buffer = new byte[1024];
while ((bytesRead = inputStream.read(buffer, 0,
1024)) != -1) {
outputStream.write(buffer,0, bytesRead);
}
outputStream.close();
inputStream.close();
model = new FileDataModel(file);//实例化数据源
// File file = new File(Constant.dataPath+Constant.rateFile2);
// model = new FileDataModel(file,"::");//实例化数据源
}catch (Exception e) {
e.printStackTrace();
}
}
/**
*得到用户-电影评分矩阵
*@return
*/
public static DataModel getDataModel(){
return model;
}
/**
*获取矩阵中的所有用户
*@return
*/
public static LongPrimitiveIterator getUserids(){
try {
return model.getUserIDs();
}catch (TasteException e) {
e.printStackTrace();
}
return null;
}
/**
*获取矩阵中的所有电影
*@return
*/
public static LongPrimitiveIterator getItemids(){
try {
return model.getItemIDs();
}catch (TasteException e) {
e.printStackTrace();
}
return null;
}
/**
*根据用户id和电影id找到评分
*@param userid
*@param itemid
*@return
*/
public static Float getPreferenceValue(long userid,long itemid){
try {
return model.getPreferenceValue(userid,itemid);
}catch (TasteException e) {
e.printStackTrace();
}
return null;
}
}
2、计算用户之间的相似度:
/**
*相似度工具类
*/
public class SimilarityUtil {
/**
*获取用户相似度对象
*@param dataModel
*@return
*/
public static UserSimilarity getUserSimilarity(DataModel
dataModel){
return(UserSimilarity)getPearsonSimilarity(dataModel);
}
/**
*使用pearson皮尔森相似度算法
*@param dataModel
*@return
*/
private static Object getPearsonSimilarity(DataModel
dataModel){
try {
return newPearsonCorrelationSimilarity(dataModel);
}catch (TasteException e) {
e.printStackTrace();
}
return null;
}
}
3、计算目标用户的最近邻居:
/**
*最近邻居工具类
*@author line
*
*/
public class NearestNUserUtil {
/**
*最近邻居工具方法
*@param userSimilarity
*@param dataModel
*@return
*/
public static UserNeighborhood
getNearestNUser(UserSimilarity userSimilarity,
DataModel dataModel){
try {
return newNearestNUserNeighborhood(Constant.knn, userSimilarity,
dataModel);
}catch (TasteException e) {
e.printStackTrace();
}
return null;
}
}
4、定义推荐器:
/**
*推荐器工具类
*@author line
*
*/
public class RecommendUtil {
public static Recommender getRecommend(DataModel
dataModel,
UserNeighborhoodneighborhood,UserSimilarity userSimilarity){
return newGenericUserBasedRecommender(dataModel, neighborhood, userSimilarity);
}
}
5、计算MAE、precision、recall:
/**
*协同过滤算法评判标准类
*/
public class JudgeUtil {
// public static void main(String[] args) {
// getJudge();
// }
/**
*协同过滤算法评判标准方法
*/
public static void getJudge(){
System.out.println("计算平均绝对误差MAE、查准率、召回率开始");
try {
RandomUtils.useTestSeed();
//这里使用的评估方法--平均差值
RecommenderEvaluator evaluator =newAverageAbsoluteDifferenceRecommenderEvaluator();
/*
我们创建了一个推荐器生成器
因为评估的时候我们需要将源数据中的一部分作为测试数据,其他作为算法的训练数据
需要通过新训练的DataModel构建推荐器,所以采用生成器的方式生成推荐器
*/
RecommenderBuilder builder =new RecommenderBuilder() {
public Recommender buildRecommender(DataModel
dataModel) throws TasteException {
UserSimilarity userSimilarity =SimilarityUtil.getUserSimilarity(dataModel);
LongPrimitiveIteratoruserids= DataModelUtil.getUserids();
UserNeighborhood neighborhood =NearestNUserUtil.getNearestNUser(userSimilarity, dataModel);
returnRecommendUtil.getRecommend(dataModel,neighborhood, userSimilarity);
}
};
/*
RecommenderEvaluator负责将数据分为训练集和测试集,用训练集构建一个DataModel和Recommender用来进行测试活动,得到结果之后在于真实数据进行比较。
参数中0.7代表训练数据为70%,测试数据是30%。最后的1.0代表的是选取数据集的多少数据做整个评估。
此处第二个null处,使用null就可以满足基本需求,但是如果我们有特殊需求,比如使用特殊的DataModel,在这里可以使用DataModelBuilder的一个实例。
*/
double score = evaluator.evaluate(builder, null, DataModelUtil.getDataModel(),
Constant.trainCount, Constant.testCount);
/*
最后得出的评估值越小,说明推荐结果越好
最后的评价结果是0.943877551020408,表示的是平均与真实结果的差值是0.9.
*/
System.out.println("平均绝对误差MAE:"+score);
/*
计算推荐4个结果时的查准率和召回率,使用评估器,并设定评估期的参数
4表示"precision and recall at 4"即相当于推荐top4,然后在top-4的推荐上计算准确率和召回率
查准率为0.75 上面设置的参数为4,表示 Precision at 4(推荐4个结果时的查准率),平均有3/4的推荐结果是好的
Recall at 4推荐两个结果的查全率是1.0 表示所有的好的推荐都包含在这些推荐结果中
*/
RandomUtils.useTestSeed();
RecommenderIRStatsEvaluator statsEvaluator =new GenericRecommenderIRStatsEvaluator();
IRStatistics stats = statsEvaluator.evaluate(builder,null, DataModelUtil.getDataModel(),
null, Constant.cfCount, GenericRecommenderIRStatsEvaluator.CHOOSE_THRESHOLD, 1.0);
System.out.println("查准率:"+stats.getPrecision());
System.out.println("召回率:"+stats.getRecall());
}catch (Exception e) {
e.printStackTrace();
}
System.out.println("计算平均绝对误差MAE、查准率、召回率结束");
}
}
三、运行结果
1、用户-电影评分矩阵:

2、用户相似度:
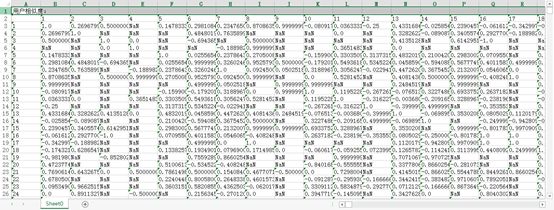
3、用户最近邻:
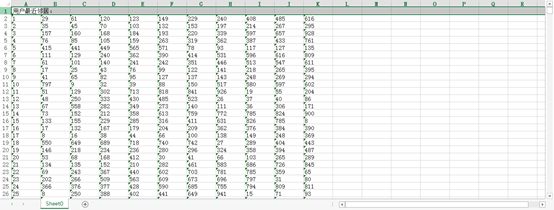
4、推荐结果:

5、MAE、precision、recall结果:

需要源代码的朋友可私信。