这个数据结构在本科的数据结构课是没有教过的,我知道这个东西是在,学习redis内部原理的时候接触的,redis 中的 sorted set 中就是使用了这种数据结构。如果你要学习下 redis的有序集合的原理,那么一定要看 skip list这种数据结构。
基础
网上有很多大佬都写了很多不错的博客去介绍 skip list,我就直接给出链接先去学习下吧:
- 跳表 skiplist
- 跳跃表
- 原始论文
- 跳表SkipList
- 跳表──没听过但很犀利的数据结构
- 跳表(skiplist)的理解
只是列举了部分我觉得比较好的。如果你看到了更牛逼的文章可以在下面评论出来。
如果你看完了还是不理解可以找下别的文章再理解下。
go 代码实现
跳转表结构
直接看原始论文中的配图吧。
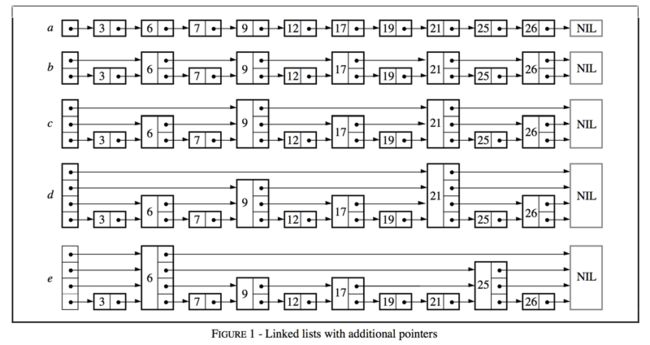
- 都会保存一个值,这个值是用来排序的key。
- 可以从途中看出每个元素都会有个
指针数据:比如e行中的6,17,25, 这几个比较明显。
// elementNode 数组指针,指向元素
type elementNode struct {
next []*Element
}
// Element 跳转表数据结构
type Element struct {
elementNode
key float64 // 用以排序和判断大小的关键字
value interface{} // 定义元素,附加
}
通过上面的两个结构体,就定义好了每个元素的一个结构。
但是我们还需要另外一个结构体来定义整个 skip list。
- 观察上图中每一行都有一个额外的
指针数组。 -
skip list是需要定义好一个maxLevel, 也就是一个深度,就比如在图中e行中一共有4层, 那么maxLevel就是4。 - 还需要一个概率,来初始化新添加进来的元素的
level, 每个元素都有个一个level, 也就是层数从高到低,数量按比例增多,具体可以参考原论文。这个概率值论文中给出了一个参考值,这个值是一个比较好概率。
type SkipList struct {
elementNode
maxLevel int // 最大深度
length int // 长度,跳表中
randSource rand.Source // 动态调节跳转表的长度
probability float64 // 概率
probTable []float64 // 存储位置,对应key
mutex sync.RWMutex // 保证线程安全
prevNodesCache []*elementNode // 缓存
}
含义解释:
-
elementNode就是用来表示上图中 每行中第一个指针数组。 -
probTable用来计算没一层元素出现的概率。 -
mutex用来控制并发读写,防止并发读写出现错误。 -
prevNodesCache用来查找某个元素的时候记录中间经过的元素的指针数组,在添加元素,和删除元素的时候有大用。 -
length跳表中 元素的个数。 -
maxLevel跳表的最大层数,或者叫做最大深度
基本方法
const (
// DefaultMaxLevel 默认skip list最大深度
DefaultMaxLevel int = 18
// DefaultProbability 默认的概率
DefaultProbability float64 = 1 / math.E
)
// Key 获取key的值
func (e *Element) Key() float64 {
return e.key
}
// Value 获取key的值
func (e *Element) Value() interface{} {
return e.value
}
type SkipList struct {
elementNode
maxLevel int // 最大深度
length int // 长度
randSource rand.Source // 随机数种子,动态调节跳转表元素的层数
probability float64 // 概率
probTable []float64 // 存储位置,对应key
mutex sync.RWMutex // 保证线程安全
prevNodesCache []*elementNode // 缓存
}
// NewSkipList 新建跳转表
func NewSkipList() *SkipList {
return NewWithMaxLevel(DefaultMaxLevel)
}
// ProbabilityTable 初始化 Probability Table
func ProbabilityTable(probability float64, maxLevel int) (table []float64) {
for i := 1; i <= maxLevel; i++ {
prob := math.Pow(probability, float64(i-1))
table = append(table, prob)
}
return table
}
// NewWithMaxLevel 自定义maxLevel新建跳转表
func NewWithMaxLevel(maxLevel int) *SkipList {
if maxLevel < 1 || maxLevel > DefaultMaxLevel {
panic("invalid maxlevel")
}
return &SkipList{
elementNode: elementNode{next: make([]*Element, maxLevel)},
prevNodesCache: make([]*elementNode, maxLevel),
maxLevel: maxLevel,
randSource: rand.New(rand.NewSource(time.Now().UnixNano())),
probability: DefaultProbability,
probTable: ProbabilityTable(DefaultProbability, maxLevel),
}
}
// 随机计算最接近的
func (list *SkipList) randLevel() (level int) {
r := float64(list.randSource.Int63()) / (1 << 63)
level = 1
for level < list.maxLevel && r < list.probTable[level] {
level++ // 级别追加
}
return level
}
// SetProbability 设置新的概率,刷新概率表
func (list *SkipList) SetProbability(newProbability float64) {
list.probability = newProbability
list.probTable = ProbabilityTable(newProbability, list.maxLevel)
}
方法解释:
-
NewWithMaxLevel初始化一个跳表,其中需要初始化elementNode指针数组, 这个指针数组的长度就是跳表的层数
prevNodesCache记录中间值的最大也只需要 最大层数个。 -
randLevel这个主要是插入一个元素时,我们要给这个元素指定高度,那就是通过这个函数在概率的范围下指定这个元素的高度。后面 添加元素的函数会再次提现。
核心方法
跳表中元素的查找效率和AVL树差不多,那这个效率是怎么实现这么高的我们就在这里说一下。
首先我们看下论文中出现的查询的一个说明图,看最上面的那个图就好
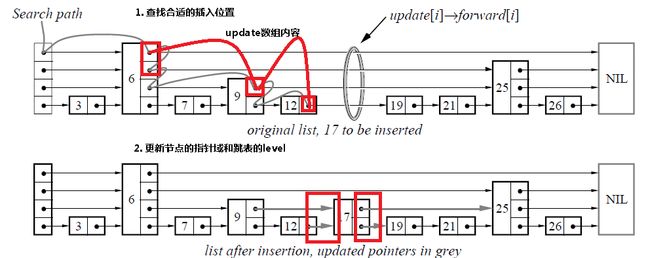
在图中的第一个查找中,查询12
- 首先会从最左边最上层开始向右遍查找,然后会找到
6 - 然后 根据
6的再下一层 也就是第三层向后找,没有找到 - 然后 继续根据
6的第二层开始向后找,找到了9 - 继续在
9的更下一层继续找,然后可以找到12
其实用语言来表述不是很准确,那就直接看代码
// Get 获取key对应的值
func (list *SkipList) Get(key float64) *Element {
list.mutex.Lock()
defer list.mutex.Unlock() // 线程安全
var prev *elementNode = &list.elementNode // 保存前置结点
var next *Element
for i := list.maxLevel - 1; i >= 0; i-- {
next = prev.next[i] // 循环跳到下一个
for next != nil && key > next.key {
prev = &next.elementNode
next = next.next[i]
}
}
if next != nil && next.key == key { // 找到
return next
}
return nil // 没有找到
}
自己理解的时候可以边在自己脑袋里面一步一步的执行这些代码,然后再结合图中的结构就很快就理解了。
接下来看跳表的插入和删除了。
func (list *SkipList) getPrevElementNodes(key float64) []*elementNode {
var prev *elementNode = &list.elementNode // 保存前置结点
var next *Element
prevs := list.prevNodesCache // 缓冲集合
for i := list.maxLevel - 1; i >= 0; i-- {
next = prev.next[i] // 循环跳到下一个
for next != nil && key > next.key {
prev = &next.elementNode
next = next.next[i]
}
prevs[i] = prev
}
return prevs
}
// Set 存储新的值
func (list *SkipList) Set(key float64, value interface{}) *Element {
list.mutex.Lock()
defer list.mutex.Unlock() // 线程安全
var element *Element
prevs := list.getPrevElementNodes(key)
if element = prevs[0].next[0]; element != nil && key == element.key {
element.value = value
return element
}
element = &Element{
elementNode: elementNode{next: make([]*Element, list.randLevel())}, // 通过概率随机指定一个 level 给新插入的元素,调用了前面出现的函数 randLevel
key: key,
value: value,
}
list.length++
for i := range element.next { // 插入数据
element.next[i] = prevs[i].next[i]
prevs[i].next[i] = element // 记录位置
}
return element
}
// Remove 获取key对应的值
func (list *SkipList) Remove(key float64) *Element {
list.mutex.Lock()
defer list.mutex.Unlock() // 线程安全
var element *Element
prevs := list.getPrevElementNodes(key)
if element = prevs[0].next[0]; element != nil && key == element.key {
for k, v := range element.next {
prevs[k].next[k] = v // 删除
}
list.length--
return element
}
return nil
}
在Set函数中最核心的要数这两块代码:
var element *Element
prevs := list.getPrevElementNodes(key)
if element = prevs[0].next[0]; element != nil && key == element.key {
element.value = value
return element
}
getPrevElementNodes 函数是用来记录我们在查找 key 的中途会经过的元素的指针数组。在上面的查询元素12的例子中,prevs 记录的值分别就是 :
- prevs[3] ==
6.elementCode - prevs[2] ==
6.elementCode - prevs[1] ==
9.elecmentCode - prevs[0] ==
9.elementCode
在 Set 函数中拿到 prevs 这样的一个数组后,在查找元素12中就可以通过prevs[0].next[0]可以索引到元素12,判断是否找到元素
if element = prevs[0].next[0]; element != nil && key == element.key
另外一块比较核心的代码就是:
for i := range element.next { // 插入数据
element.next[i] = prevs[i].next[i]
prevs[i].next[i] = element // 记录位置
}
这部分代码就完全提现了在 SkipList 结构体中 prevNodesCache 的作用在哪里,这就是用来插入新元素的时候把元素中的指针数组把前后相同层的元素连接起来。在 Remove 中的函数是一样的。
Remove 方法和 Set方法差不多可以对参照起来理解
go 源代码
package skipList
import (
"math"
"math/rand"
"sync"
"time"
)
const (
// DefaultMaxLevel 默认skip list最大深度
DefaultMaxLevel int = 18
// DefaultProbability 默认的概率
DefaultProbability float64 = 1 / math.E
)
// elementNode 数组指针,指向元素
type elementNode struct {
next []*Element
}
// Element 跳转表数据结构
type Element struct {
elementNode
key float64
value interface{} // 定义元素
}
// Key 获取key的值
func (e *Element) Key() float64 {
return e.key
}
// Value 获取key的值
func (e *Element) Value() interface{} {
return e.value
}
type SkipList struct {
elementNode
maxLevel int // 最大深度
length int // 长度
randSource rand.Source // 动态调节跳转表的长度
probability float64 // 概率
probTable []float64 // 存储位置,对应key
mutex sync.RWMutex // 保证线程安全
prevNodesCache []*elementNode // 缓存
}
// NewSkipList 新建跳转表
func NewSkipList() *SkipList {
return NewWithMaxLevel(DefaultMaxLevel)
}
// ProbabilityTable 初始化 Probability Table
func ProbabilityTable(probability float64, maxLevel int) (table []float64) {
for i := 1; i <= maxLevel; i++ {
prob := math.Pow(probability, float64(i-1))
table = append(table, prob)
}
return table
}
// NewWithMaxLevel 自定义maxLevel新建跳转表
func NewWithMaxLevel(maxLevel int) *SkipList {
if maxLevel < 1 || maxLevel > DefaultMaxLevel {
panic("invalid maxlevel")
}
return &SkipList{
elementNode: elementNode{next: make([]*Element, maxLevel)},
prevNodesCache: make([]*elementNode, maxLevel),
maxLevel: maxLevel,
randSource: rand.New(rand.NewSource(time.Now().UnixNano())),
probability: DefaultProbability,
probTable: ProbabilityTable(DefaultProbability, maxLevel),
}
}
// 随机计算最接近的
func (list *SkipList) randLevel() (level int) {
r := float64(list.randSource.Int63()) / (1 << 63)
level = 1
for level < list.maxLevel && r < list.probTable[level] {
level++ // 级别追加
}
return level
}
// SetProbability 设置新的概率,刷新概率表
func (list *SkipList) SetProbability(newProbability float64) {
list.probability = newProbability
list.probTable = ProbabilityTable(newProbability, list.maxLevel)
}
// Set 存储新的值
func (list *SkipList) Set(key float64, value interface{}) *Element {
list.mutex.Lock()
defer list.mutex.Unlock() // 线程安全
var element *Element
prevs := list.getPrevElementNodes(key)
if element = prevs[0].next[0]; element != nil && key == element.key {
element.value = value
return element
}
element = &Element{
elementNode: elementNode{next: make([]*Element, list.randLevel())},
key: key,
value: value,
}
list.length++
for i := range element.next { // 插入数据
element.next[i] = prevs[i].next[i]
prevs[i].next[i] = element // 记录位置
}
return element
}
// Get 获取key对应的值
func (list *SkipList) Get(key float64) *Element {
list.mutex.Lock()
defer list.mutex.Unlock() // 线程安全
var prev *elementNode = &list.elementNode // 保存前置结点
var next *Element
for i := list.maxLevel - 1; i >= 0; i-- {
next = prev.next[i] // 循环跳到下一个
for next != nil && key > next.key {
prev = &next.elementNode
next = next.next[i]
}
}
if next != nil && next.key == key { // 找到
return next
}
return nil // 没有找到
}
// Remove 获取key对应的值
func (list *SkipList) Remove(key float64) *Element {
list.mutex.Lock()
defer list.mutex.Unlock() // 线程安全
var element *Element
prevs := list.getPrevElementNodes(key)
if element = prevs[0].next[0]; element != nil && key == element.key {
for k, v := range element.next {
prevs[k].next[k] = v // 删除
}
list.length--
return element
}
return nil
}
func (list *SkipList) getPrevElementNodes(key float64) []*elementNode {
var prev *elementNode = &list.elementNode // 保存前置结点
var next *Element
prevs := list.prevNodesCache // 缓冲集合
for i := list.maxLevel - 1; i >= 0; i-- {
next = prev.next[i] // 循环跳到下一个
for next != nil && key > next.key {
prev = &next.elementNode
next = next.next[i]
}
prevs[i] = prev
}
return prevs
}